突破大模型推理瓶颈!首篇「Test-Time Scaling」全景综述,深入剖析AI深思之道
突破大模型推理瓶颈!首篇「Test-Time Scaling」全景综述,深入剖析AI深思之道当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
来自主题: AI技术研报
9403 点击 2025-05-13 14:48
 搜索
搜索
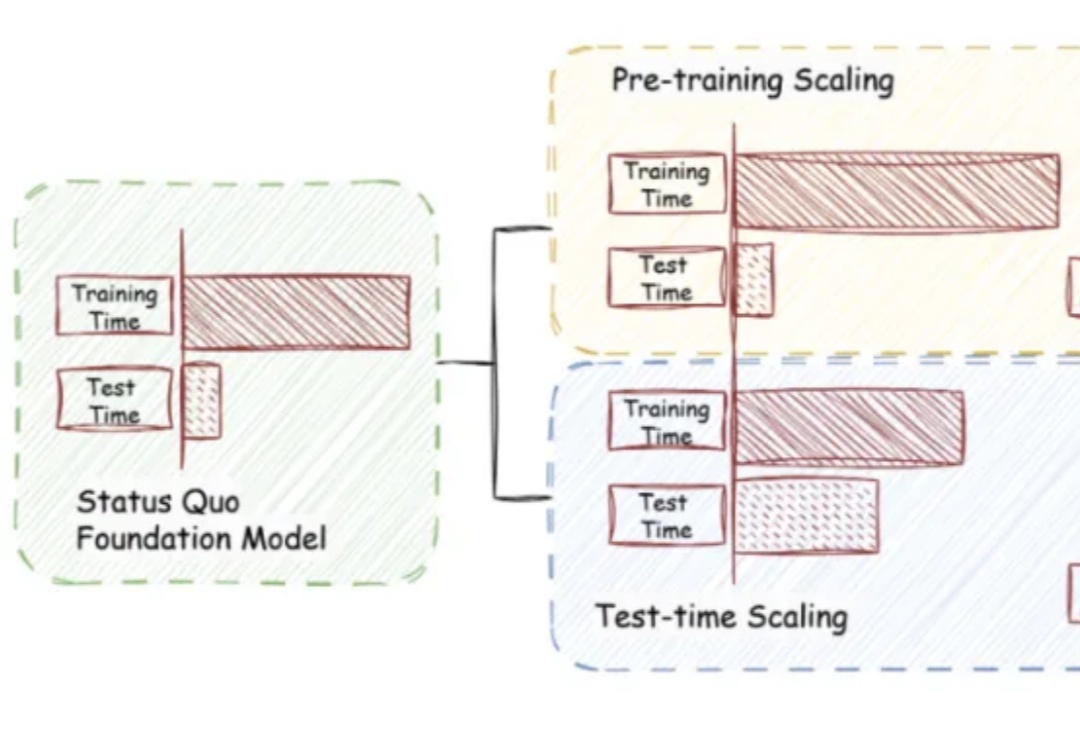
当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
当AI与工具相结合,智能体不再只是概念!Minion-agent整合多框架能力,解决碎片化问题,支持多智能体协作与工具调用,降低开发门槛,已在多个场景中展现高效能力,有望推动AI智能体创新和普及!
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。
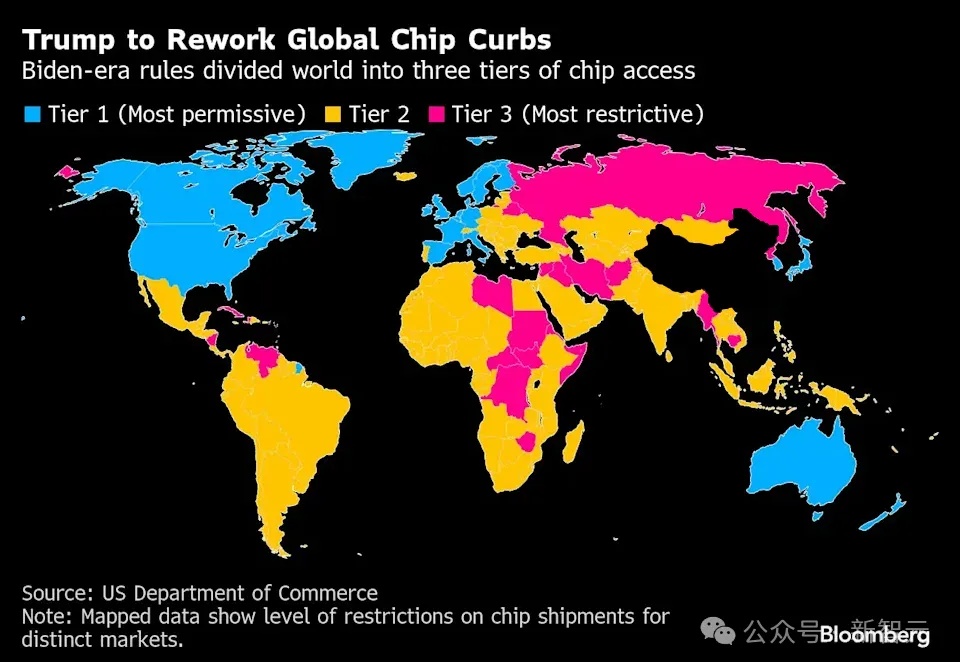
外媒称,特朗普政府将撤销拜登时代《AI扩散框架》,取消AI芯片出口「三档」限制,并将提出简版规则,巩固美国AI创新地位。
在前端开发领域,Vue 框架一直以其易用性和灵活性受到广大开发者的喜爱。而如今,Vue 生态在人工智能(AI)领域的应用上又迈出了重要的一步。尤雨溪近日宣布,Vue、Vite 和 Rolldown 的文档网站均已添加了llms.txt文件,这一举措旨在让大型语言模型(LLM)更方便地理解这些前端技术。
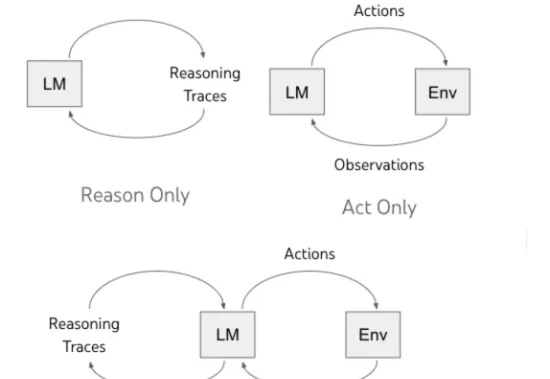
Agent 即一系列自动化帮助人类完成具体任务的智能体或者智能助手,可以自主进行推理,与环境进行交互并获取环境以及人类反馈,从而最终完成给定的任务,比如最近爆火的 Manus 以及 OpenAI 的 o3 等一系列模型和框架。
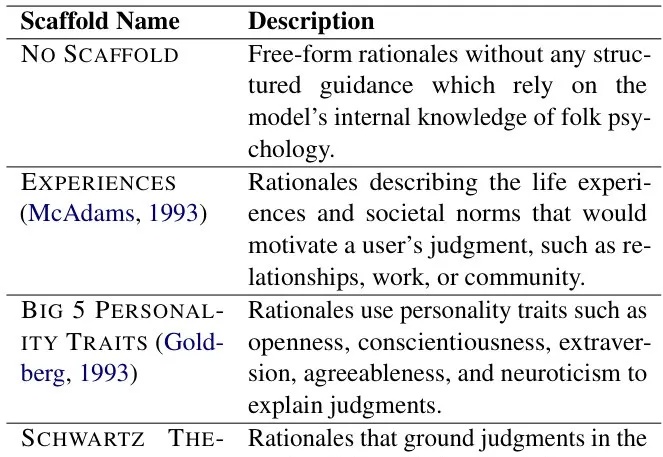
照这个发展速度,不远的将来AI不仅能模仿你的行为,还能理解你为何做出这些选择。PB&J框架正是这一突破性技术的代表,它通过引入心理学中的"支架"概念,使AI能够构建合理化解释,深入理解人类决策背后的动机。

今天凌晨,OpenAI 董事会以及创始人 Sam Altman 用一封公开信给出了一个制度层面的回答:将旗下营利业务转为「公共利益公司」(PBC),使命不变,由非营利组织继续掌控,但治理框架更为清晰。

近日,美国 AI 初创公司 Anthropic(Claude 背后公司)就美国商务部的《人工智能扩散框架》临时最终规则提交意见书,呼吁加强对高端AI 芯片的出口控制。更具争议性的是,Anthropic 在博客中声称,中国已建立起高度成熟的芯片走私网络,涉及金额高达数亿美元。
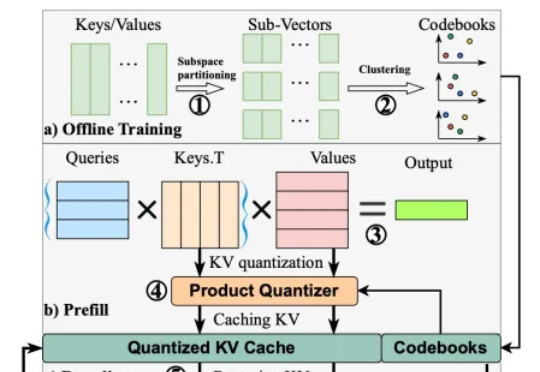
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。