简单吧,Agent优化就两种路径,有参数优化和无参数优化,你选哪种 | 最新综述
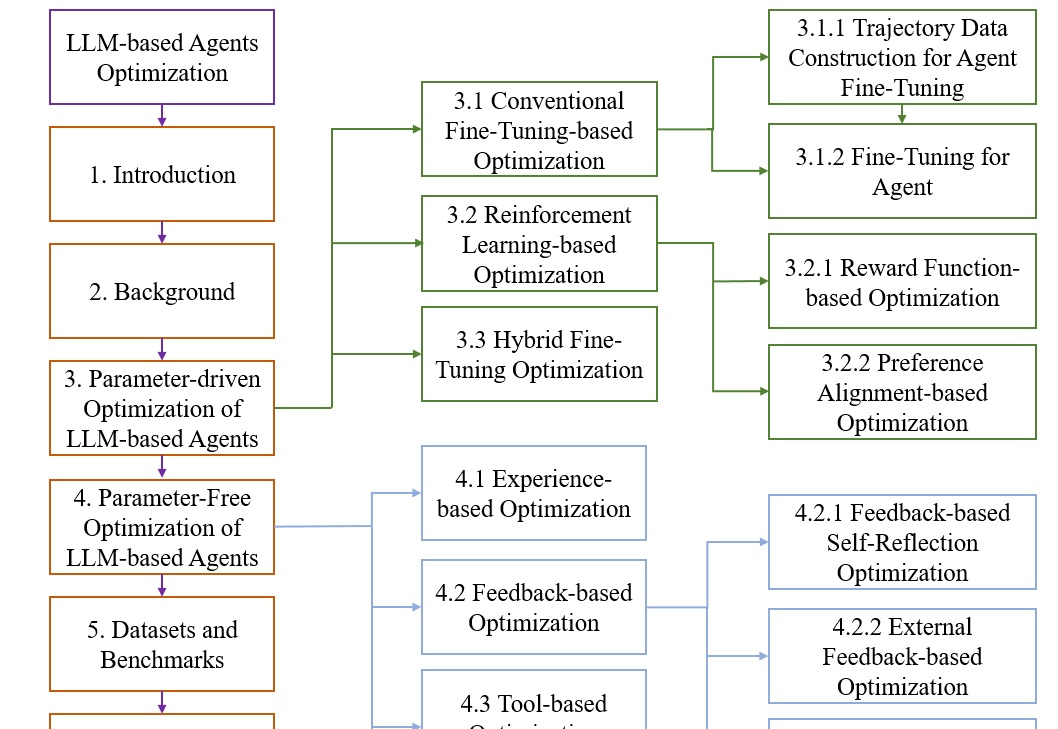
简单吧,Agent优化就两种路径,有参数优化和无参数优化,你选哪种 | 最新综述本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。
来自主题: AI技术研报
6527 点击 2025-03-25 16:33