ICML 2026 Spotlight | AI隐私训练时,那个最难控制的「阀门」能自动调节吗?
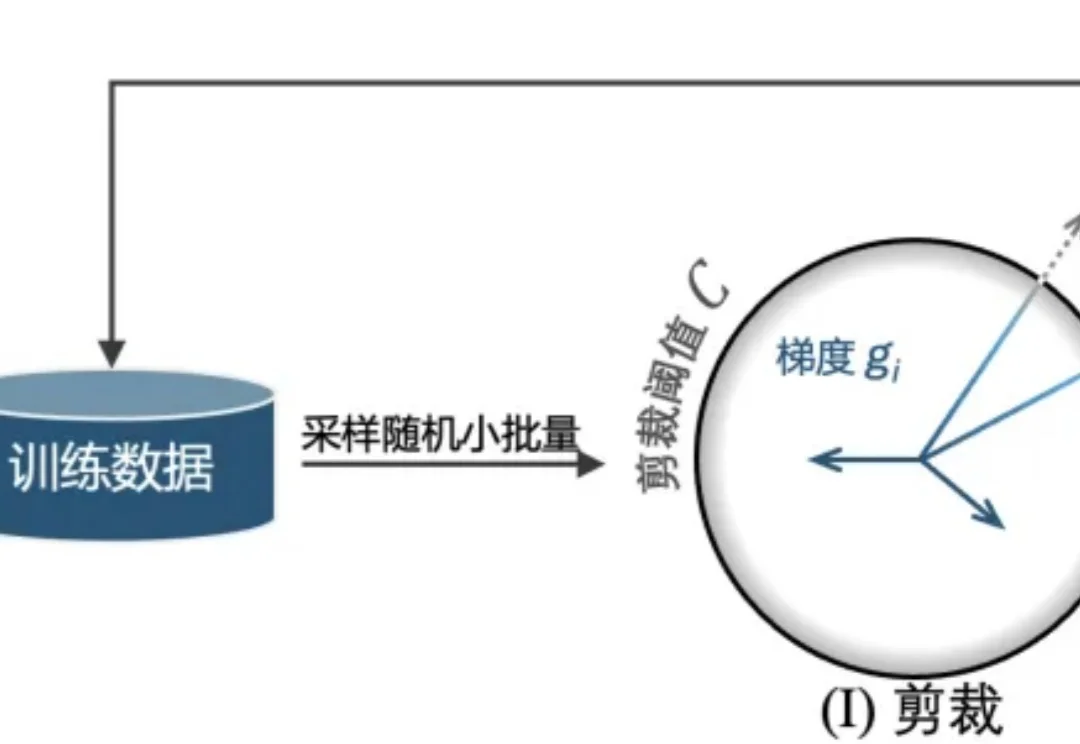
ICML 2026 Spotlight | AI隐私训练时,那个最难控制的「阀门」能自动调节吗?近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
来自主题: AI技术研报
7592 点击 2026-06-19 09:24
 搜索
搜索
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
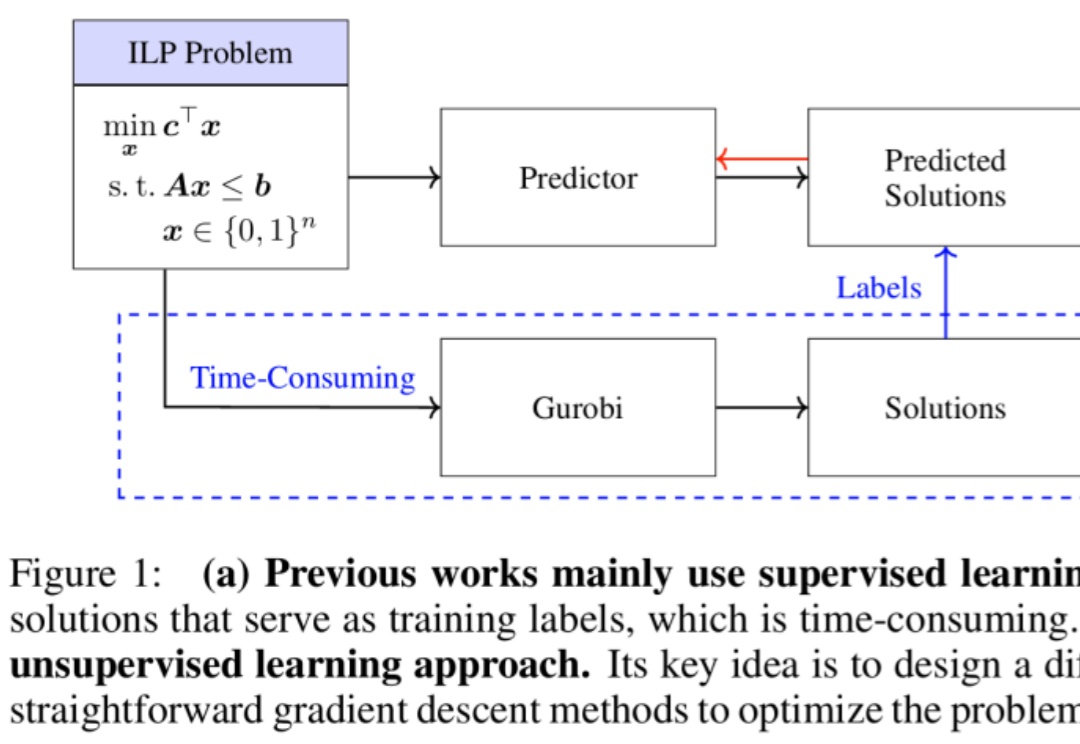
无监督学习训练整数规划求解器的新范式来了。

过去十年间,基于随机梯度下降(SGD)的深度学习模型在许多领域都取得了极大的成功。与此同时各式各样的 SGD 替代品也如雨后春笋般涌现。在这些众多替代品中,Adam 及其变种最受追捧。无论是 SGD,还是 Adam,亦或是其他优化器,最核心的超参数非 Learning rate 莫属。因此如何调整好 Leanring rate 是炼丹师们从一开始就必学的技能。

4年前的开源项目突然在Hacker News爆火,通过可视化的「小球下山」,帮助非专业和专业人士,更好地理解AI训练中梯度下降的过程。