80万条数据揭示隐患:AI正在「污染」病历,你的诊疗数据可能越来越不靠谱
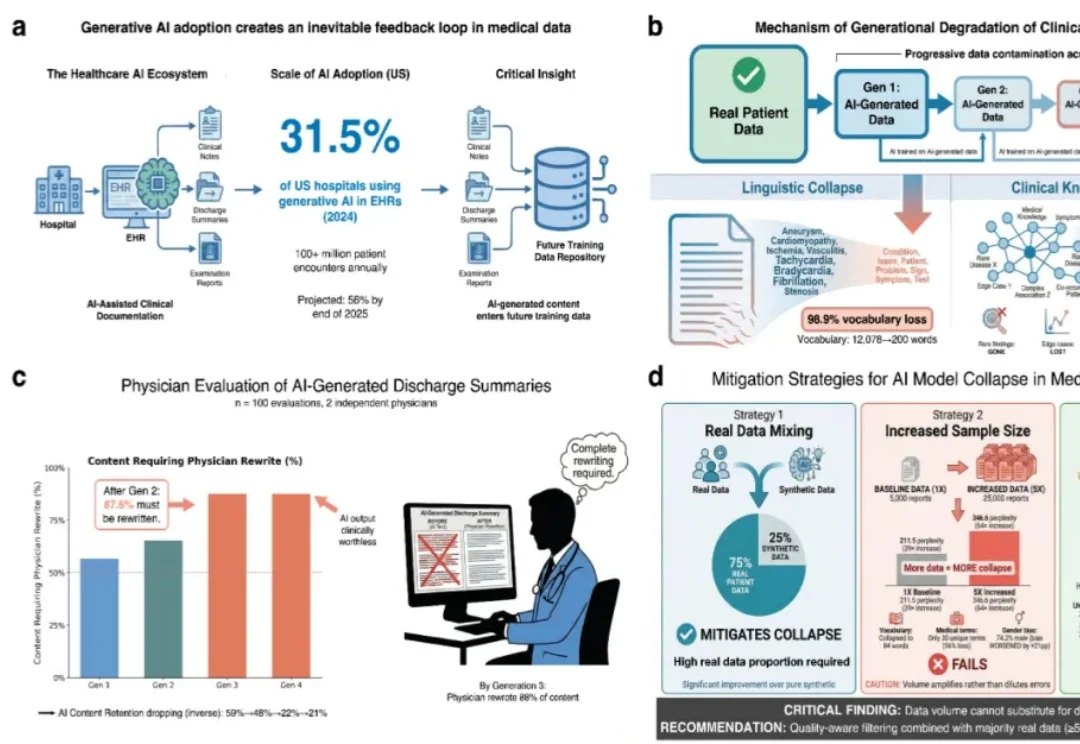
80万条数据揭示隐患:AI正在「污染」病历,你的诊疗数据可能越来越不靠谱随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
来自主题: AI技术研报
10478 点击 2026-03-17 09:25
 搜索
搜索
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。
最近几年,大模型赛道好不热闹。
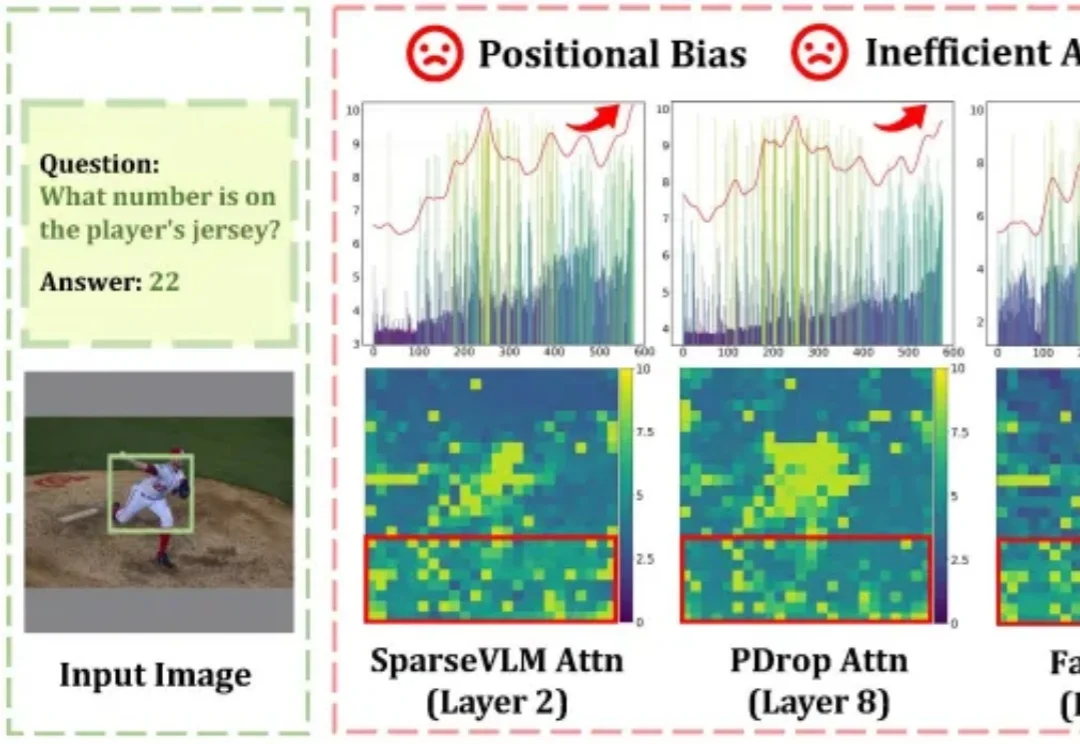
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
吉林大学&微软亚洲研究院等团队提出MindPower框架,让机器人像人一样理解他人想法并主动帮忙,构建了首个以机器人为中心的心智推理评测体系,通过六层推理链条,让AI不仅看懂场景,更能推断意图、做出决策、执行动作,显著提升助人能力。
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

就在刚刚,Moonshot AI(月之暗面)发布了一项足以撼动 Transformer 底层的研究:《Attention Residuals》。海外科技大 V,谷歌高级AI产品经理 Shubham Saboo 直接开启了“高赞”模式:“他们触碰了那个十年没人敢碰的部分。”

一睁眼!陈天桥带队的大模型黑马MiroMind再度满血归来—— 正式发布新一代重型推理智能体:MiroThinker-1.7和MiroThinker-H1。

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。

Google 最近发了 Gemini Embedding 2,他们第一个原生多模态向量模型。文本、图像、视频、音频、文档,全部映射到同一个 3072 维向量空间。这是 Omni Embedding(全模态向量模型)的大趋势:一个架构吃下所有模态,从 jina-embeddings-v4 到 Omni-Embed-Nemotron 再到 Omni-5,大家都在往这个方向收敛。
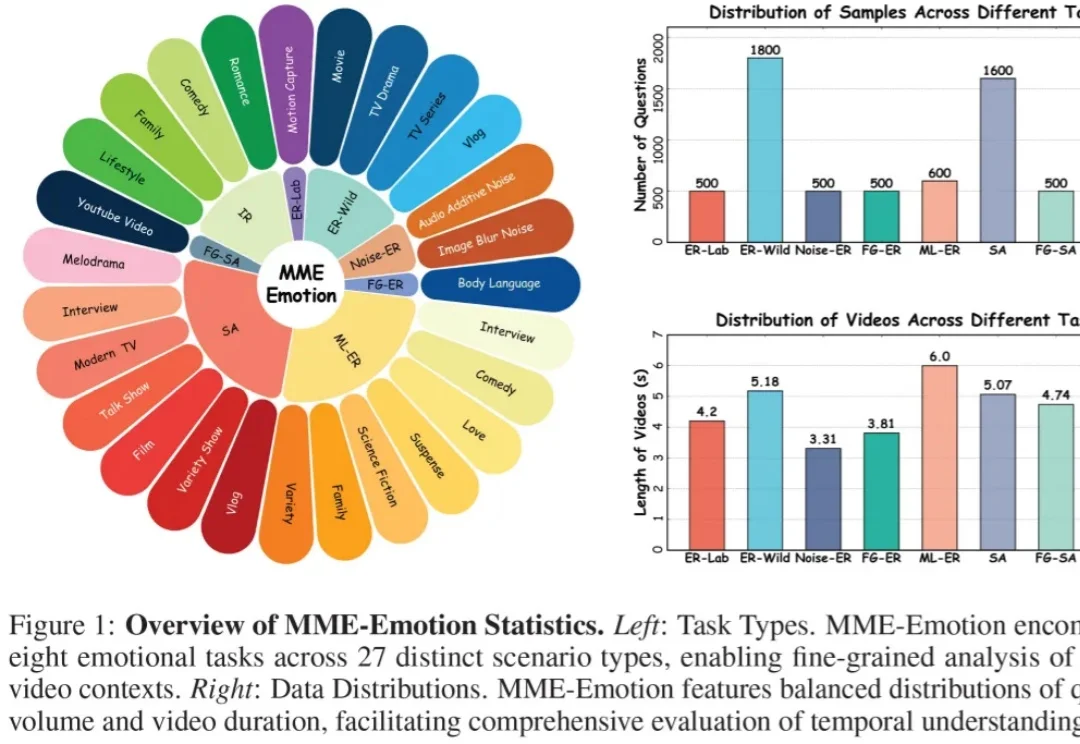
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?