ICLR 2026|多模态大模型真的理解情绪吗?MME-Emotion给出了系统答案
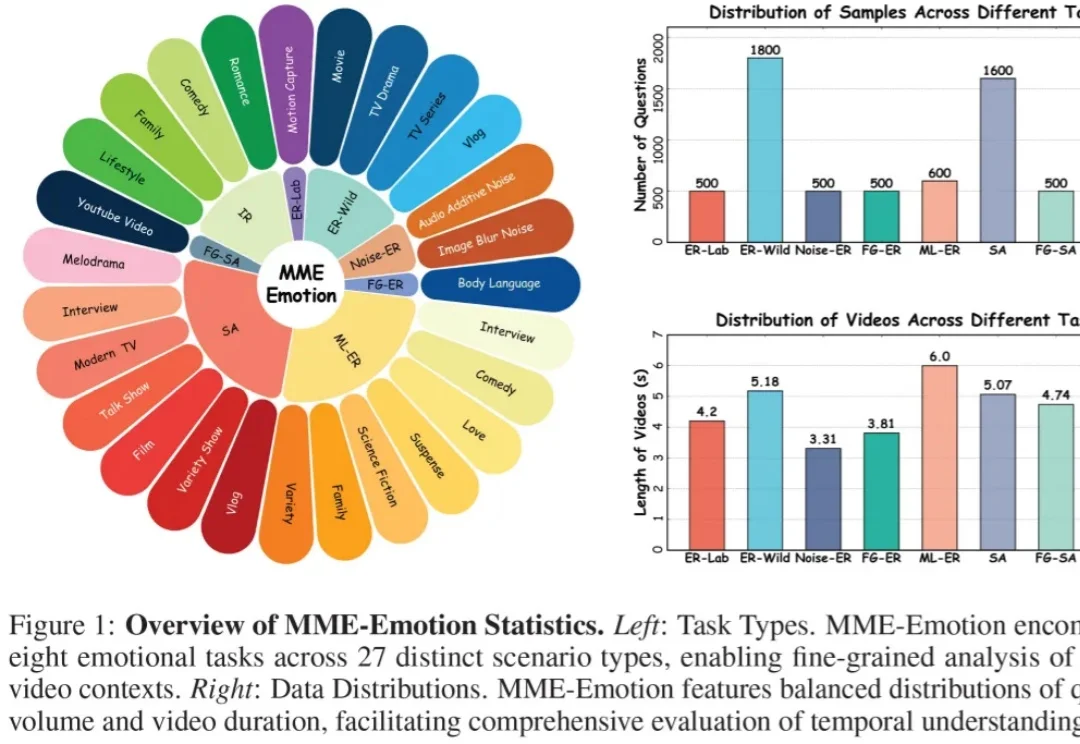
ICLR 2026|多模态大模型真的理解情绪吗?MME-Emotion给出了系统答案近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?
来自主题: AI技术研报
7117 点击 2026-03-16 14:27