vLLM团队官宣创业:融资1.5亿美元,清华特奖游凯超成为联创
vLLM团队官宣创业:融资1.5亿美元,清华特奖游凯超成为联创大模型推理的基石 vLLM,现在成为创业公司了。
来自主题: AI资讯
7244 点击 2026-01-23 11:24
 搜索
搜索
大模型推理的基石 vLLM,现在成为创业公司了。

AI爬取数据规模可提升5000倍。

最近 AI 编程界最火的事情,就是怎么把各种 coding 模型卷到极致了。

过去一年,AI圈的词语通货膨胀是不是有点太严重了?
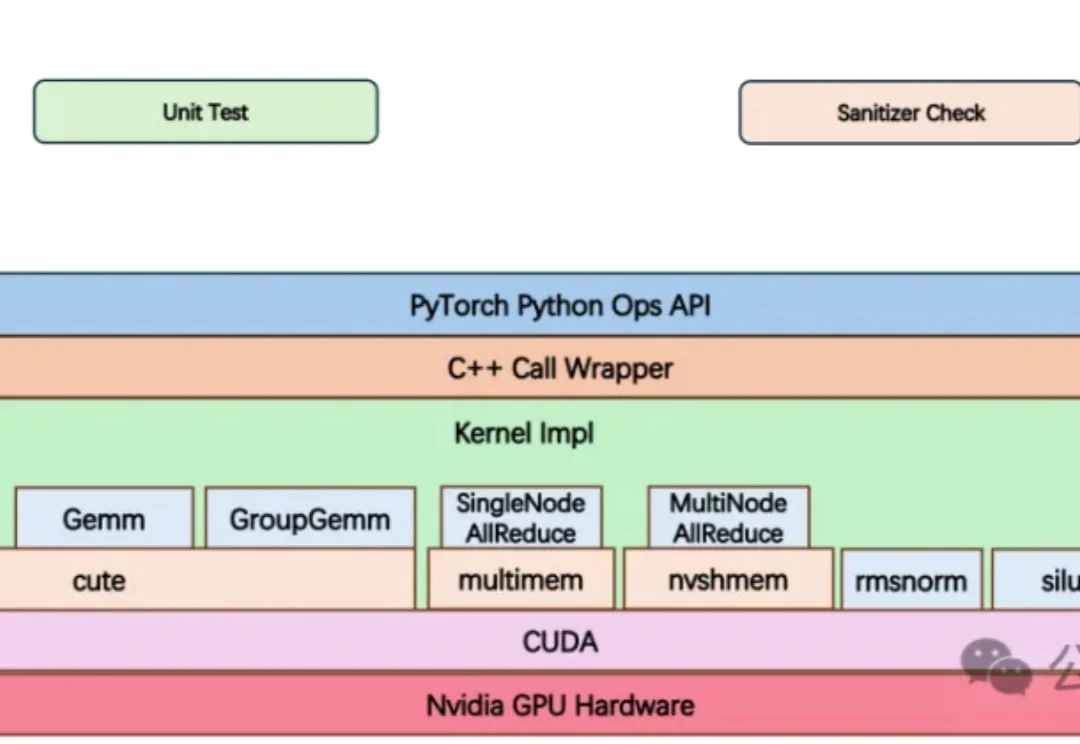
大模型竞赛中,算力不再只是堆显卡,更是抢效率。

GEM框架利用认知科学原理,从少量人类偏好中提取多维认知评估,让AI在极少标注下精准理解人类思维,提高了数据效率,在医疗等专业领域表现优异,为AI与人类偏好对齐提供新思路。

本周四,百川智能正式发布新一代大模型 Baichuan-M3 Plus,其面向医疗应用开发者,在真实场景下将医学问题推理能力推向了全新高度。新模型发布的同时,接入 M3 Plus 的百小应 App 与网页版也已同步上线。

今天,Anthropic 试图向世界展示它的灵魂。Anthropic 正式公布了一份长达 84 页的特殊文档——《Claude 宪法》(Claude's Constitution)。这份文件并非通常意义上的技术白皮书或用户协议,而是一份直接面向 AI 模型本身「撰写」的价值观宣言。

不er,这个世界还有什么是真的?反正我是已经分不清了...
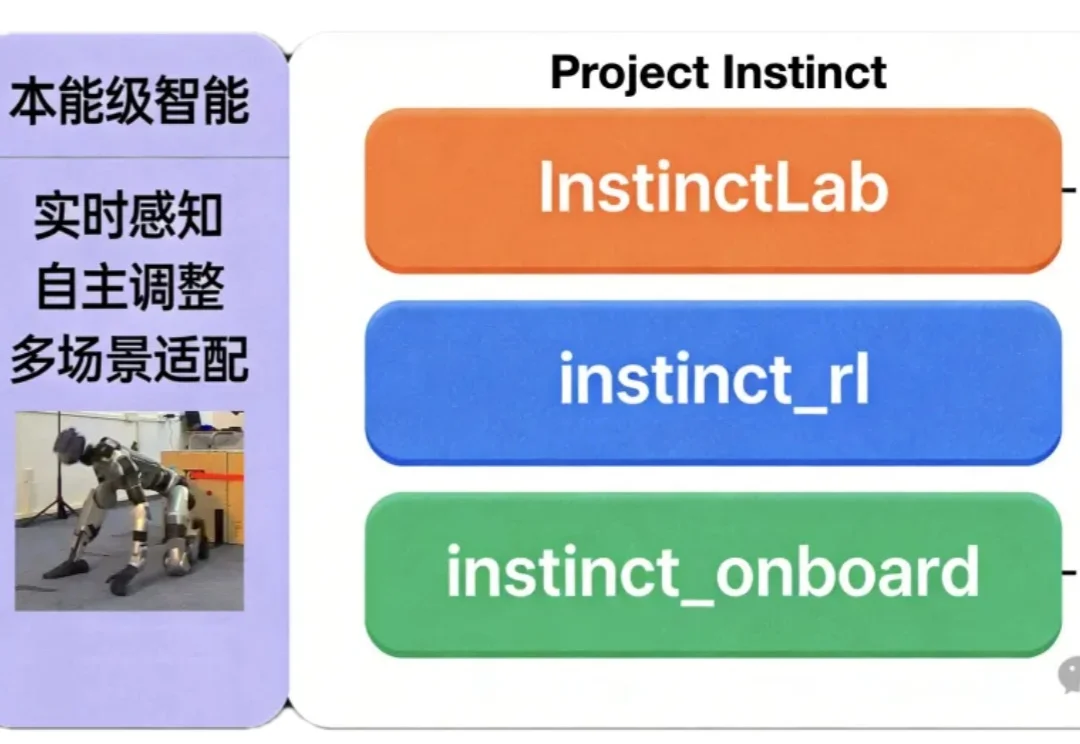
如何让机器人同时具备“本能反应”与复杂运动能力?