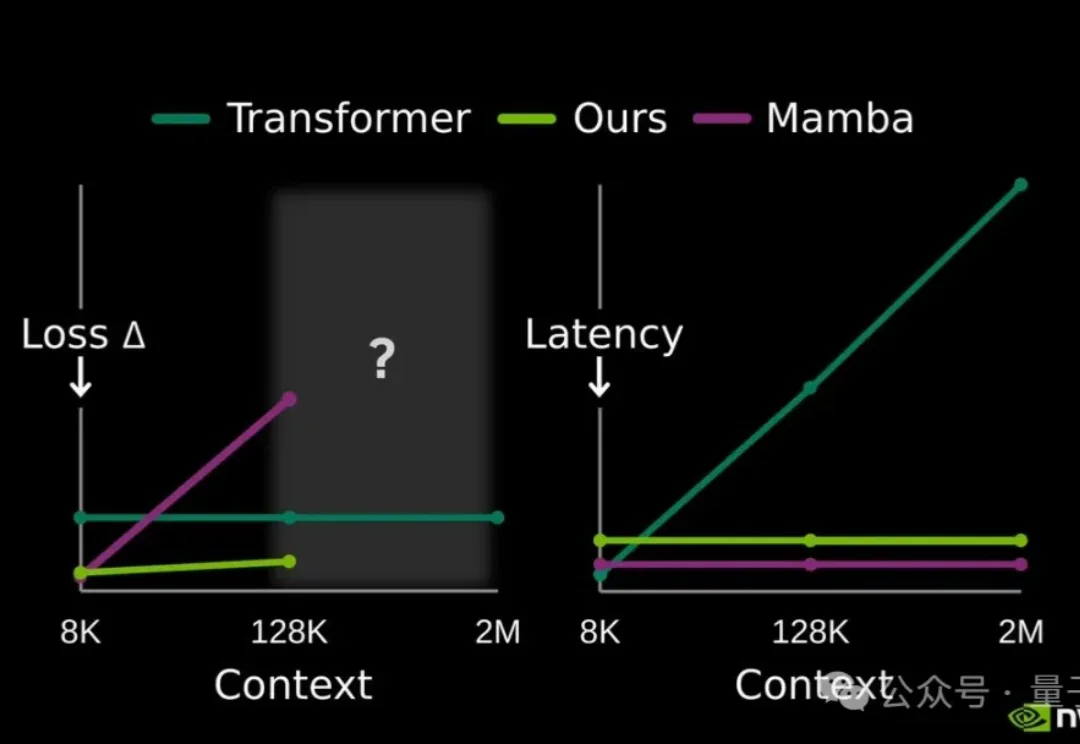
不用额外缓存!英伟达开源大模型记忆压缩方案,128K上下文提速2.7倍
不用额外缓存!英伟达开源大模型记忆压缩方案,128K上下文提速2.7倍提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
来自主题: AI技术研报
9154 点击 2026-01-14 15:29
 搜索
搜索
提高大模型记忆这块儿,美国大模型开源王者——英伟达也出招了。
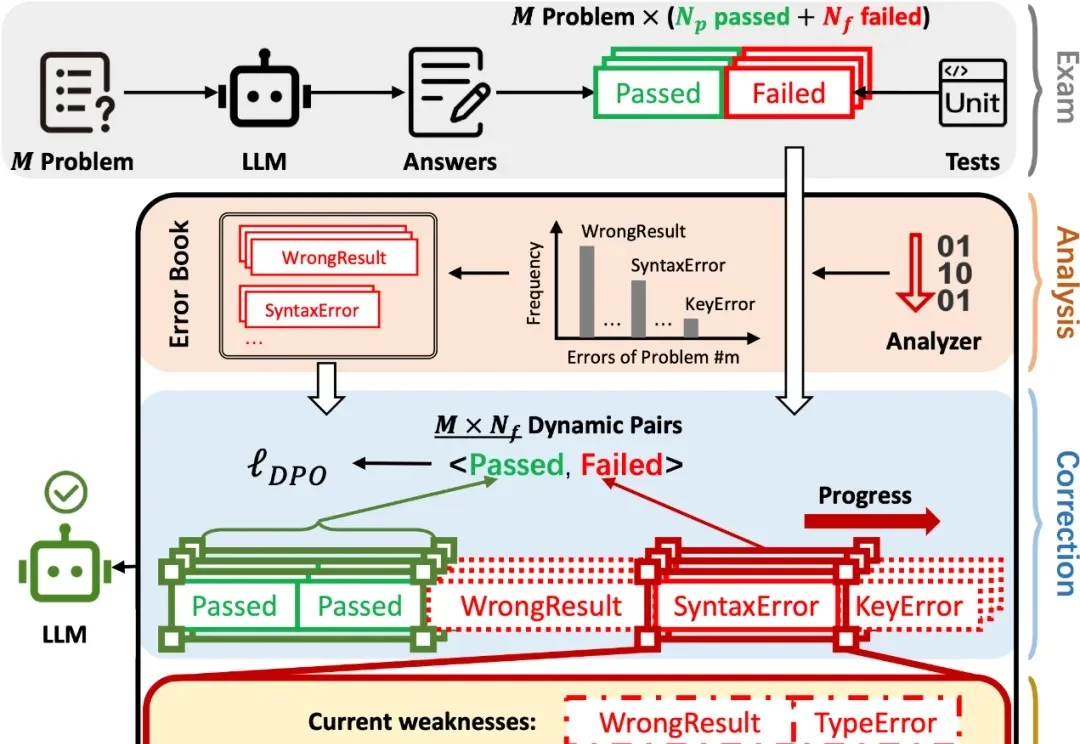
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
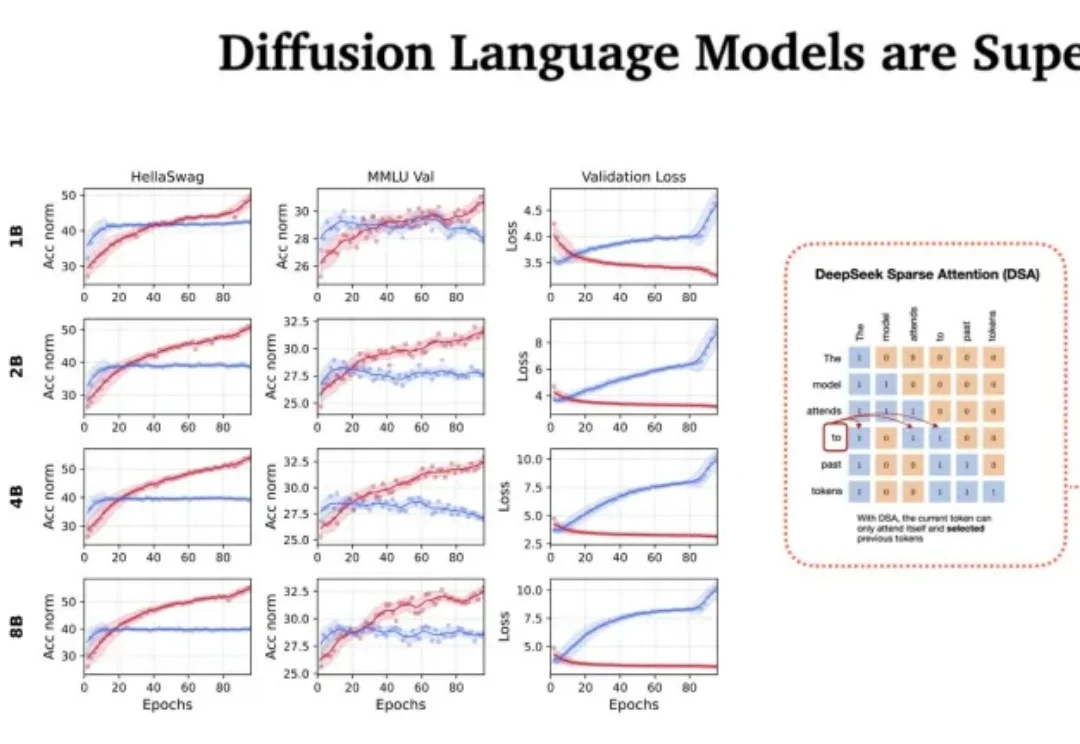
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。
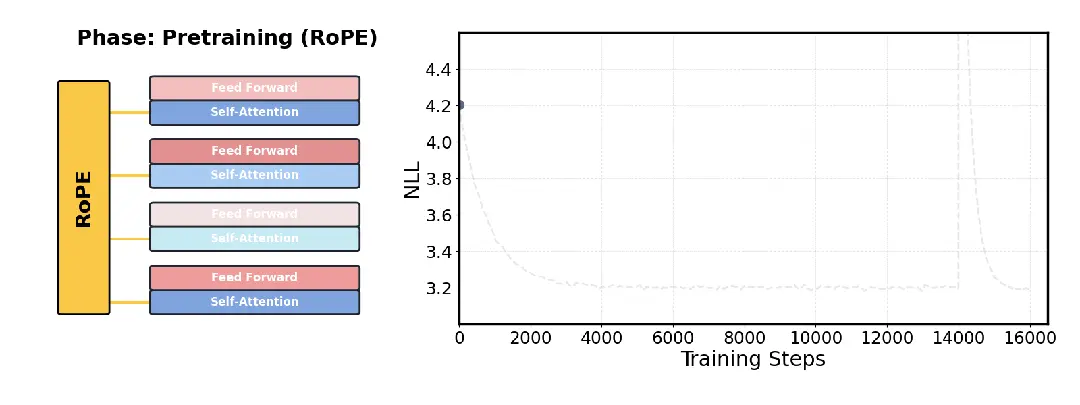
针对大模型长文本处理难题,Transformer架构的核心作者之一Llion Jones领导的研究团队开源了一项新技术DroPE。
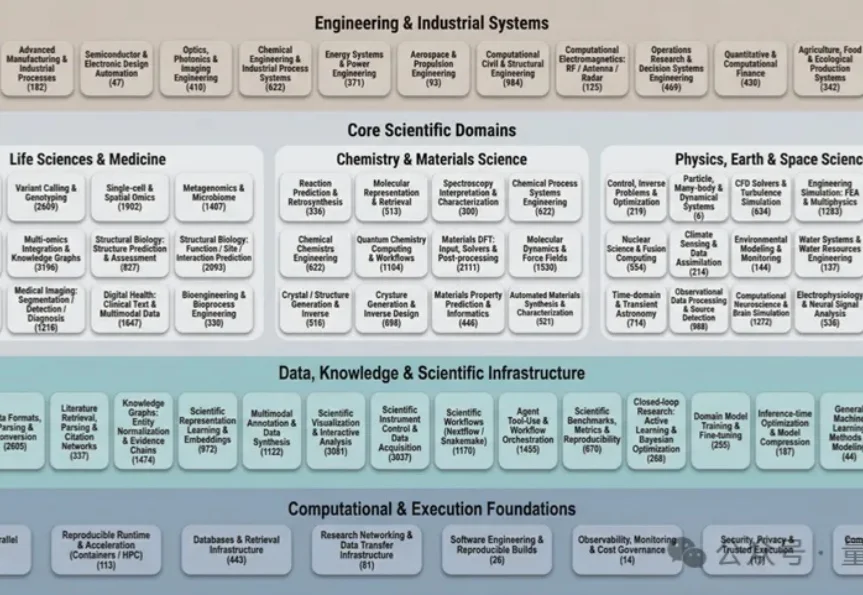
过去几十年里,科学计算领域积累了数量空前的开源软件工具。

百川智能表示今年上半年,将陆续发布两款 to C 的医疗产品。 作者|Li Yuan 编辑|郑玄 你有没有向 AI 助手问过你的健康问题? 如果你和我一样是一个 AI 的深度用户,大概率你也试过。 O
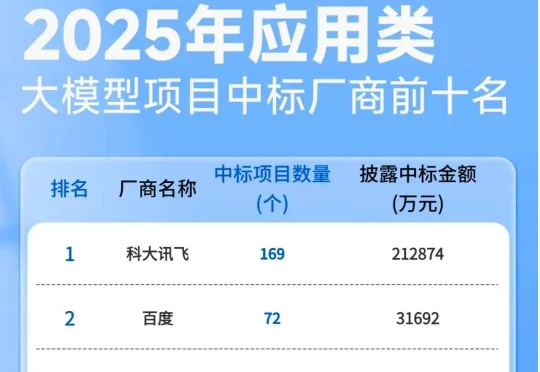
一份大模型中标数据报告,揭示了产业重心转移的清晰轨迹:应用类项目占比近六成,市场用真金白银为 “落地” 投票。2025 年,中国大模型产业在招投标市场上演了一场令人瞠目的 “狂飙”。智能超参数的监测数据显示,全年大模型相关中标项目数量达到 7539 个,披露金额 295.2 亿元,较 2024 年分别激增 396% 与 356%。市场正以前所未有的速度,将技术潜力兑换为商业订单。
发现一个很有意思的现象,模型能力已经不是瓶颈了。