# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我们发现真正的智能体(Agent)不仅仅需要强大的推理能力,还需要能够从经验中持续学习、适应新环境的能力。
近期,来自清华大学和上海AI实验室的研究者提出的测试时强化学习(Test-Time Reinforcement Learning,TTRL)
(https://arxiv.org/abs/2504.16084v)打开了一扇通往经验时代的大门,它允许模型在没有明确标签的情况下,通过自身的探索和尝试来提升能力。
随着David Silver和Richard Sutton在《Welcome to the era of experience》中所指出的,
我们正在从纯粹依赖人类标注数据的训练范式,转向一个模型能够通过真实世界交互生成和标注自己训练数据的新时代。
之前我曾写过一篇文章《谷歌联合强化学习之父:通过经验学习的4大核心,Agent将获得超人能力 |最新战略瞭望》介绍过这项研究。

测试时强化学习(TTRL)是一种突破性的方法,它允许模型在测试阶段使用无标签数据进行自我提升,解决了传统强化学习依赖明确奖励信号的局限。
在现实应用中,随着任务复杂度和数量的增长,为强化学习大规模标注数据变得越来越不切实际,
TTRL通过巧妙利用模型自身的预测来估计奖励,实现了在没有外部监督的情况下的持续学习。
你可以将TTRL理解为模型的"自我提升循环":它生成多个候选答案,通过多数投票等方式估计最优答案,然后使用这个估计来计算奖励,进而指导自身的进化。
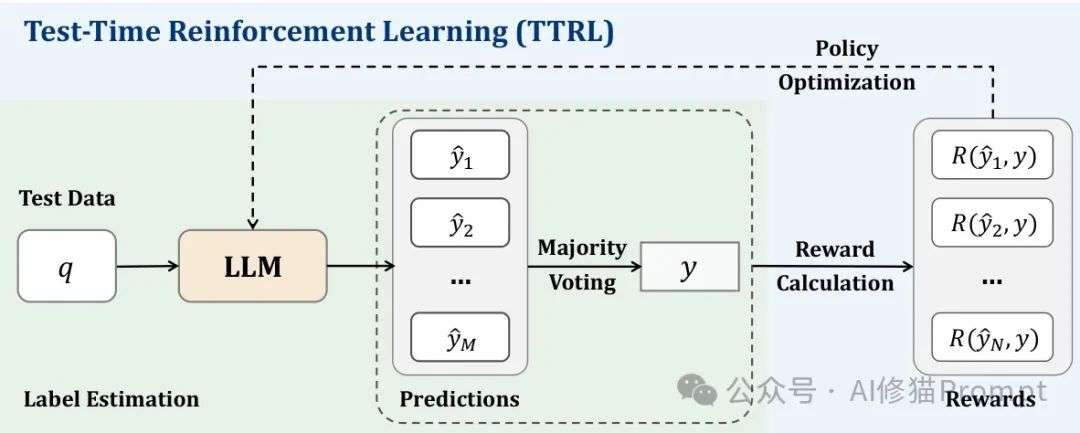
TTRL结合了测试时缩放(Test-Time Scaling, TTS)和测试时训练(Test-Time Training, TTT)的优势,创造出一种全新的学习范式。
传统的TTS方法主要关注在推理阶段增加计算资源,如并行生成多个答案然后选择最佳解答,但模型参数保持不变;
而TTT允许模型在测试时更新参数,但通常缺乏有效的奖励机制来指导这种更新。
TTRL弥补了这一鸿沟,它不仅在测试时更新模型参数,还通过创新的奖励估计方法实现了高效的强化学习,使模型能够在面对新数据时持续进化。
TTRL的核心创新在于,它找到了一种在无标注数据上估计奖励的有效方法,使强化学习成为可能。
给定一个问题作为状态x,模型从策略π_θ(y|x)中采样生成输出y,
然后通过多次采样生成多个候选输出{y₁,y₂,...,yₙ},并通过多数投票等聚合方法得出一个共识输出y作为最优行动的代理。
环境基于采样行动y与共识行动y之间的一致性提供奖励r(y,y*),强化学习的目标是最大化期望奖励:max_θ E_{y~π_θ(·|x)}[r(y,y*)]。
通过这种方式,模型可以在推理阶段适应分布偏移的输入,而无需标注数据。
测试时强化学习(TTRL)的具体实现需要精心设计才能达到最佳效果。以下是构建高效TTRL系统的关键实现策略:
生成多样化样本是TTRL的基础,关键步骤包括:
# 多数投票核心实现
defmajority_voting(samples):
# 提取关键答案,避免表述差异
answers = [extract_answer(sample) for sample in samples]
valid_answers = [ans for ans in answers if ans]
# 统计答案频率并找出最常见的
counter = Counter(valid_answers)
majority_answer, count = counter.most_common(1)[0]
# 计算一致性比例,用于评估可信度
majority_ratio = count / len(samples)
return majority_answer, majority_ratio
TTRL的奖励机制需要考虑多种因素:
在低置信度场景(如多数比例<0.5)下,可使用辅助指标(如问题解析完整性)来补充奖励信号,进一步提高系统鲁棒性。
多数投票奖励函数是TTRL中至关重要的组成部分,它提供了一种简单而有效的方式来估计标签并计算奖励。
具体来说,当给定一个问题x时,首先将其输入到LLM中生成一组输出,然后通过答案提取器处理这些输出得到对应的预测答案P={ŷᵢ}ᵢ₌₁ᴺ。
通过多数投票作为评分函数s(y,x),我们获得最频繁出现的预测y作为估计标签,然后使用这个估计的标签计算基于规则的奖励:
如果预测ŷᵢ等于估计标签y,则奖励为1,否则为0。这种简单的奖励机制在实践中表现出惊人的有效性,为模型提供了足够的信号来指导其自我改进。
def majority_voting(self, samples: List[str]) -> str:
"""
使用多数投票选择最佳回答
"""
# 提取答案
answers = [self.extract_answer(sample) for sample in samples]
# 确保至少有一个有效答案
valid_answers = [ans for ans in answers if ans]
ifnot valid_answers:
return"我无法生成有效答案。"
# 统计答案频率
counter = Counter(valid_answers)
# 获取最多数的答案
majority_answer, count = counter.most_common(1)[0]
# 计算多数比例
majority_ratio = count / len(samples)
print(f"{Fore.YELLOW}多数投票比例: {majority_ratio:.2f}{Style.RESET_ALL}")
return majority_answer
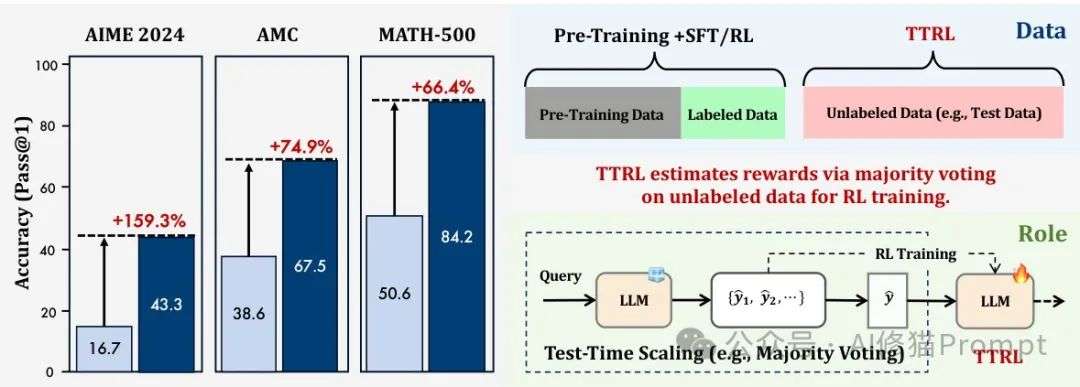
研究者在数学推理基准测试上进行的实验结果令人振奋,TTRL展示了其强大的自我进化能力。
在高度挑战性的数学推理基准AIME 2024上,TTRL使Qwen2.5-Math-7B的性能提升了惊人的159.3%,超越了所有在大规模标注数据集上训练的模型。
更令人印象深刻的是,仅仅通过在无标签测试数据上的自我进化,TTRL在三个基准测试上平均提升了84.1%的性能,这证明了它在实际应用中的巨大潜力。
你可以想象,这种自我进化的能力将如何改变我们构建持续学习Agent的方式:不再需要大量的人工标注,Agent可以在与环境交互的过程中不断提升自己。
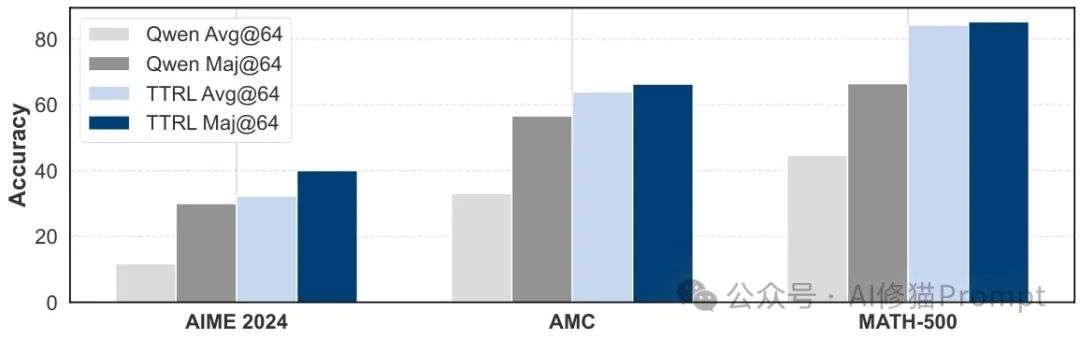
TTRL展示了令人印象深刻的扩展性和泛化能力,随着模型规模从1.5B增加到7B,在AIME 2024和AMC上的性能增益显著提高。
这种自然扩展行为的背后原理是:更大的模型能够在自我提升过程中产生更准确的多数投票奖励,从而导致对新数据的更有效学习。
研究结果还表明,TTRL不仅能提高目标任务的性能,还能泛化到其他基准测试,这意味着它不依赖过拟合,而是在自我提升过程中获得了可泛化的能力。
对于你正在开发的Agent产品来说,这意味着通过TTRL训练的Agent可以更好地适应未见过的场景和任务,而不会在遇到新环境时完全失效。
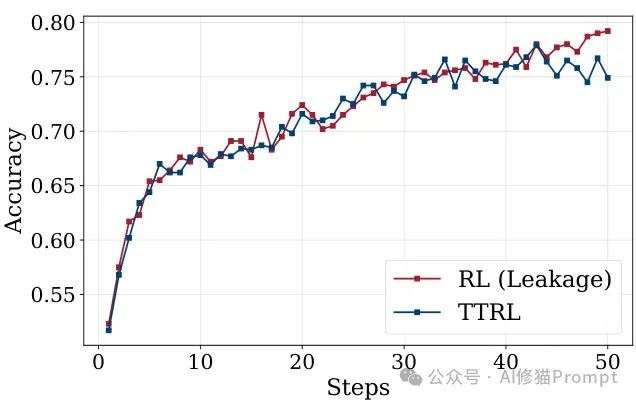
TTRL的一个惊人发现是,它能够突破理论上的性能上限。
由于TTRL使用模型自身的多数投票输出进行RL训练,这些投票性能(Maj@N)直观上应该是最终性能的上限,
然而实验表明:训练后的模型不仅匹配而且超越了这个预期上限,暗示它超越了自己的输出质量,这些输出构成了它的监督信号。
另一个天花板是在测试数据上直接进行RL训练(信息泄露场景),虽然这种设置由于信息泄露问题很少被研究,
但它代表了在特定数据集上提高性能的最有效方式。
令人费解的是,TTRL的性能曲线紧密接近信息泄露场景下的RL,证明了它在无监督设置下通过RL实现自我提升的效率。
你可能会好奇,即使在模型无法通过多数投票准确估计标签的情况下,为什么TTRL仍然有效?研究者通过分析发现了两个主要原因。
首先,奖励比标签更密集,即使估计的标签不准确,同一轮次内的其他输出仍可能产生正确或高质量的奖励,
这使得整体奖励信号对伪标签估计中的错误更具鲁棒性。
其次,一个有趣的现象是,当模型能力较弱时,TTRL给出的奖励可能更准确,
因为模型的响应高度多样且一致不正确,即使标签准确率在20%到50%之间波动,
奖励准确率也能达到令人印象深刻的92%,这为在测试数据上进行有效的自我提升提供了可靠基础。
虽然TTRL表现强大,但它并非万能的,在某些场景下可能会失效。研究者在初步实验中确定了两个潜在问题:目标任务上先验知识的缺乏和不适当的RL超参数。
先验知识在RL中起着至关重要的作用,通常决定TTRL学习过程的成功或失败,
这主要是因为测试数据通常具有更高的难度并引入新特征,而TTRL没有纳入数据过滤等机制来支持课程学习。
实验还发现,随着问题难度的增加,性能提升和长度减少比例都倾向于降低,这表明基准模型的可用先验知识不足以支持在更具挑战性的问题上学习。
作为Agent开发者,你需要确保模型在进行TTRL之前已经具备了足够的基础知识来处理目标任务。
超参数设置在RL训练中起着至关重要的作用,并且由于奖励估计中的潜在噪声和测试数据的特性,这种影响在TTRL中被进一步放大。
研究者发现两个关键超参数可能严重影响训练的稳定性和成功率:温度和轮次。
将温度设置为1.0(而不是0.6)增加了模型的输出熵,这促进了更广泛的探索,
并允许模型更好地利用其先验知识进行自我提升,这在处理具有挑战性的基准测试时尤为重要。
鉴于数据集的规模和难度存在显著差异,较小和较困难的数据集需要更多的轮次来实现足够的探索。
作为一个实用技巧,当你在自己的Agent上实现TTRL时,应该仔细监控训练过程中的熵变化,确保它随着训练的进行而适当减小。
TTRL解决了在无标签数据上进行强化学习的难题,但真正强大的Agent还需要一个关键组件:
记忆(Memory)。通过将TTRL与长期记忆机制结合,我们可以创建能够从过去经验中学习并将这些知识应用到新任务的Agent。
一个配备了TTRL和长期记忆的Agent不仅能在当前任务上自我提升,还能将获得的知识存储起来,
在未来面对相似问题时快速调用,实现真正的经验积累和知识迁移。
这种结合将使Agent能够在连续的、开放式的环境中茁壮成长,不断积累经验并提升自身能力,这正是经验时代所需要的Agent应具备的核心特质。
长期记忆是经验时代Agent的基础设施,它使Agent能够从经验中进化,而不只是记住训练数据。以下是设计高效记忆系统的关键架构:
一个完整的记忆系统应包含以下层次:
class MemorySystem:
def__init__(self):
self.short_term = {} # 用户ID -> 短期记忆
self.episodic = {} # 用户ID -> 情景记忆
self.semantic = {} # 用户ID -> 语义记忆
self.procedural = {} # 用户ID -> 程序性记忆
defadd(self, content, memory_type, user_id="default_user"):
# 根据记忆类型添加到不同存储
memory_entry = {
"content": content,
"timestamp": time.time(),
"importance": self._calculate_importance(content),
"access_count": 0
}
if memory_type == "short_term":
self.short_term.setdefault(user_id, []).append(memory_entry)
# 定期将短期记忆转移到长期记忆
self._consolidate_memories(user_id)
elif memory_type == "episodic":
self.episodic.setdefault(user_id, []).append(memory_entry)
# 其他记忆类型类似...
高效的记忆检索是关键:
有效管理记忆库的规模和质量:
在TTRL+Memory系统中,记忆不仅是存储过去对话的被动仓库,而是主动参与奖励估计和学习过程的关键组件。
通过与记忆内容对比验证多数投票结果,系统可以进一步提高奖励估计的准确性,实现真正的"经验学习"而非简单的"记忆回放"。
基于以上研究和核心代码我实现了一个具有简单记忆功能的Agent,以下是存储过多轮聊天之后,重新运行的截图:
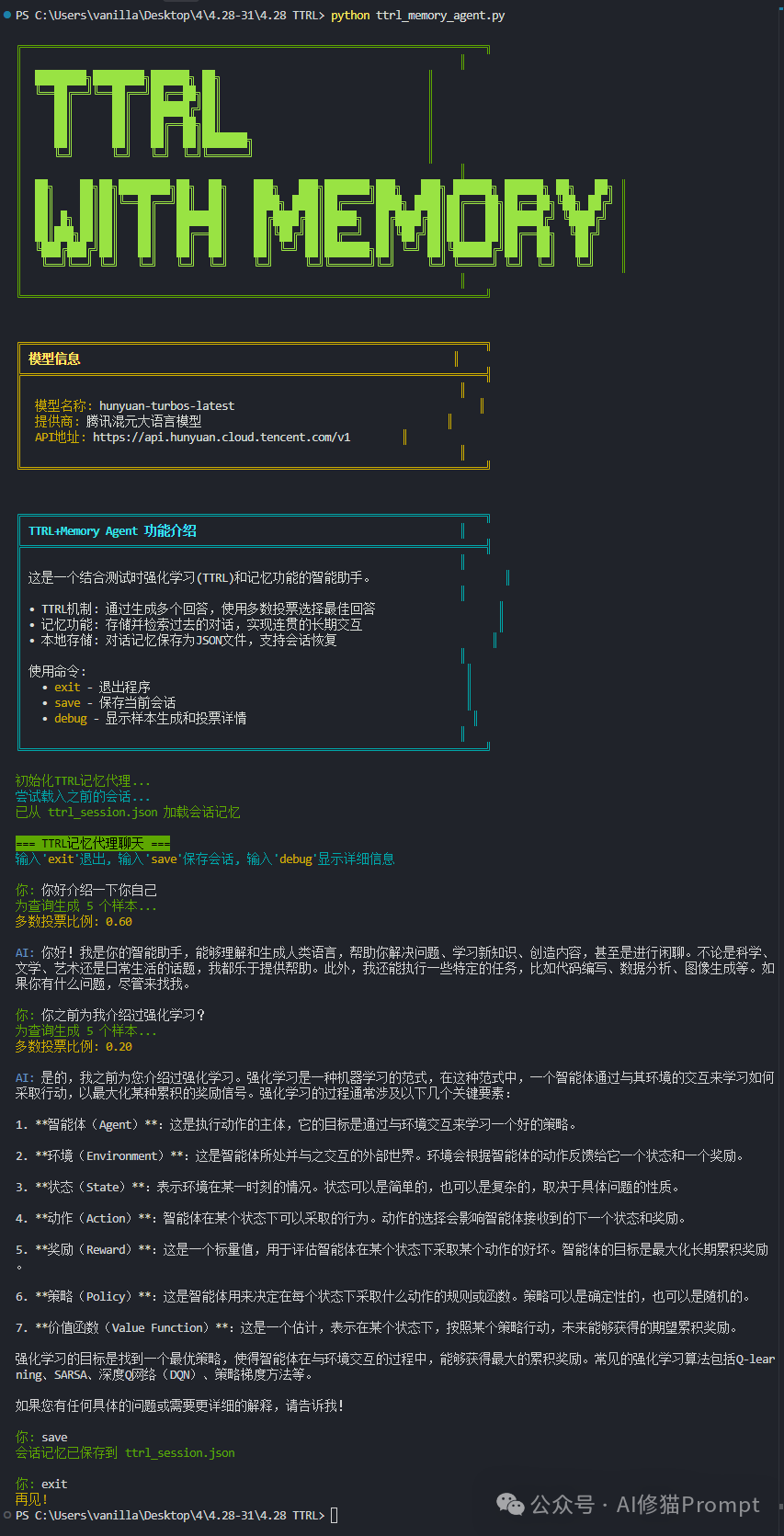
初始化TTRL记忆代理...
尝试载入之前的会话...
已从 ttrl_session.json 加载会话记忆
=== TTRL记忆代理聊天 ===
输入'exit'退出, 输入'save'保存会话, 输入'debug'显示详细信息
你: 你好介绍一下你自己
为查询生成 5 个样本...
多数投票比例: 0.60
AI: 你好!我是你的智能助手,能够理解和生成人类语言,帮助你解决问题、学习新知 识、创造内容,甚至是进行闲聊。不论是科学、文学、艺术还是日常生活的话题,我都 乐于提供帮助。此外,我还能执行一些特定的任务,比如代码编写、数据分析、图像生 成等。如果你有什么问题,尽管来找我。
你: 你之前为我介绍过强化学习?
为查询生成 5 个样本...
多数投票比例: 0.20
AI: 是的,我之前为您介绍过强化学习。强化学习是一种机器学习的范式,在这种范式 中,一个智能体通过与其环境的交互来学习如何采取行动,以最大化某种累积的奖励信 号。强化学习的过程通常涉及以下几个关键要素:
1. **智能体(Agent)**:这是执行动作的主体,它的目标是通过与环境交互来学习一 个好的策略。
2. **环境(Environment)**:这是智能体所处并与之交互的外部世界。环境会根据智 能体的动作反馈给它一个状态和一个奖励。
3. **状态(State)**:表示环境在某一时刻的情况。状态可以是简单的,也可以是复 杂的,取决于具体问题的性质。
4. **动作(Action)**:智能体在某个状态下可以采取的行为。动作的选择会影响智能体接收到的下一个状态和奖励。
5. **奖励(Reward)**:这是一个标量值,用于评估智能体在某个状态下采取某个动作的好坏。智能体的目标是最大化长期累积奖励。
6. **策略(Policy)**:这是智能体用来决定在每个状态下采取什么动作的规则或函数。策略可以是确定性的,也可以是随机的。
7. **价值函数(Value Function)**:这是一个估计,表示在某个状态下,按照某个策略行动,未来能够获得的期望累积奖励。
强化学习的目标是找到一个最优策略,使得智能体在与环境交互的过程中,能够获得最 大的累积奖励。常见的强化学习算法包括Q-learning、SARSA、深度Q网络(DQN)、策略梯度方法等。
如果您有任何具体的问题或需要更详细的解释,请告诉我!
你: save
会话记忆已保存到 ttrl_session.json
你: exit
再见!
将TTRL与记忆系统相结合代表了对Silver和Sutton所倡导的"经验时代"理念的具体实践。这种融合带来了几个关键创新:

在经验时代,Agent不仅需要记住经验,还需要评估这些经验的可靠性。TTRL的多数投票机制与记忆系统相结合,使Agent能够:
传统TTRL在样本生成时缺乏有效的探索指导,而记忆系统可以提供这种指导:
经验时代的一个核心特性是能够从不同领域的经验中学习。TTRL+Memory实现了:
这种创新融合使Agent能够充分发挥"经验时代"的潜力,实现从交互中持续学习、从经验中不断进化的能力。
与传统依赖人类标注数据的系统相比,TTRL+Memory或许能为构建真正自主进化的智能系统带来曙光。
如果你想在自己的Agent项目中实现TTRL,这里有一些实用建议。
首先,选择一个合适的基础模型,确保它对目标任务有足够的先验知识,研究表明更大的模型(如7B参数量的模型)通常能获得更好的TTRL效果。
我这里选择的是hunyuan-TurboS,官方推荐使用 的混元旗舰大模型最新版本,具备更强的思考能力,更优的体验效果。
其次,配置适当的超参数,特别是温度(建议设为1.0以增加探索)和训练轮次(根据数据集大小和任务复杂度调整)。
在实现多数投票奖励函数时,建议采样多个响应用于基于投票的标签估计,
然后从每个提示中下采样16个响应用于训练,这种投票后采样策略有效地降低了计算成本,同时仍能达到强大的性能。
最后,密切监控训练动态,特别是熵、多数投票奖励和多数比率,这些指标可以帮助你评估TTRL的有效性并选择最佳检查点。
TTRL代表了强化学习领域的重要突破,它解决了在无标注数据上进行有效学习的关键挑战,为构建能够持续自我进化的Agent带来了曙光。
通过巧妙利用多数投票等简单机制来估计奖励,TTRL实现了在测试时对模型进行训练,使其能够适应新环境和任务,而无需大量人工标注。
实验结果表明,TTRL不仅能显著提升模型性能,还能超越其自身的训练信号上限,接近直接在测试数据上训练的模型性能。
作为一个正在开发Agent产品的工程师,你现在拥有了一个强大的工具,可以使你的Agent不断从经验中学习和成长,这正是经验时代所需要的核心能力。
文章来自于微信公众号 “Al修猫Prompt”,作者 :Al修猫Prompt



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
