
我手搓了一份 AI 版网易云年度报告,快来认领你的年度模型|附教程
我手搓了一份 AI 版网易云年度报告,快来认领你的年度模型|附教程网易云的年度听歌报告出来了,你的 2025 听歌关键词是什么。
来自主题: AI资讯
6036 点击 2025-12-29 14:09
 搜索
搜索
网易云的年度听歌报告出来了,你的 2025 听歌关键词是什么。
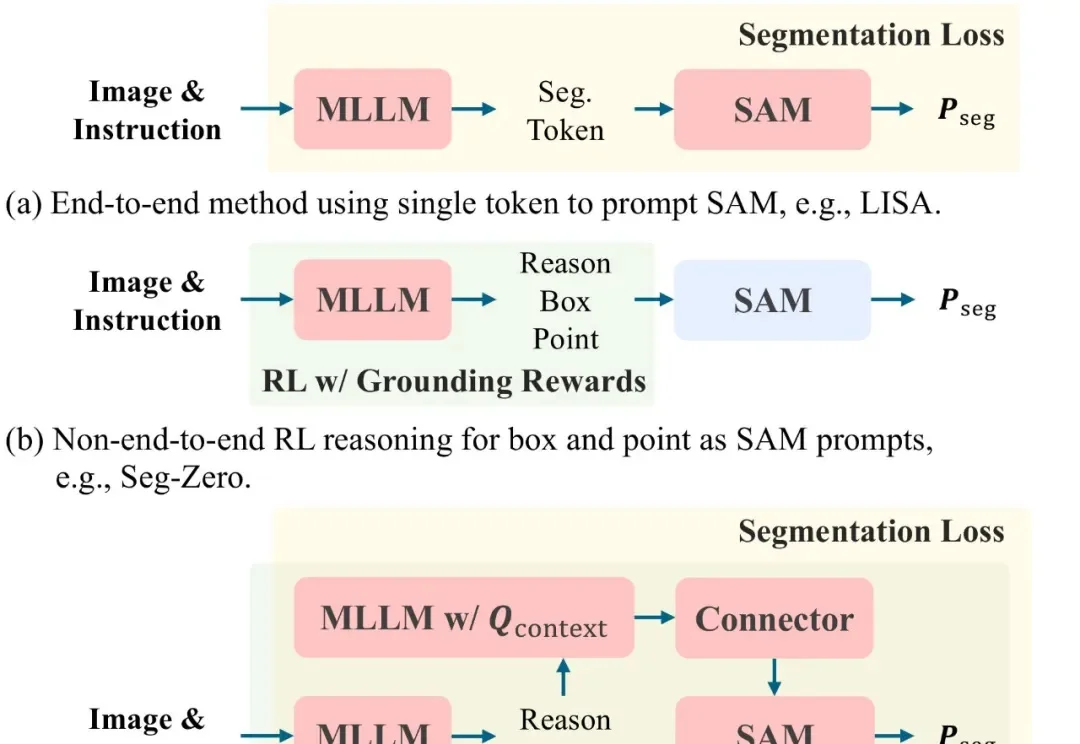
文本提示图像分割(Text-prompted image segmentation)是实现精细化视觉理解的关键技术,在人机交互、具身智能及机器人等前沿领域具有重大的战略意义。这项技术使机器能够根据自然语言指令,在复杂的视觉场景中定位并分割出任意目标。
两个月以来,我一直想写一篇给小白的 CC 入门指南,今天终于可以写了。

我们经常在一些对比 AI 性能的测试中,看到宣称基础模型在自然语言理解、推理或编程任务等性能超人类的相关报道。
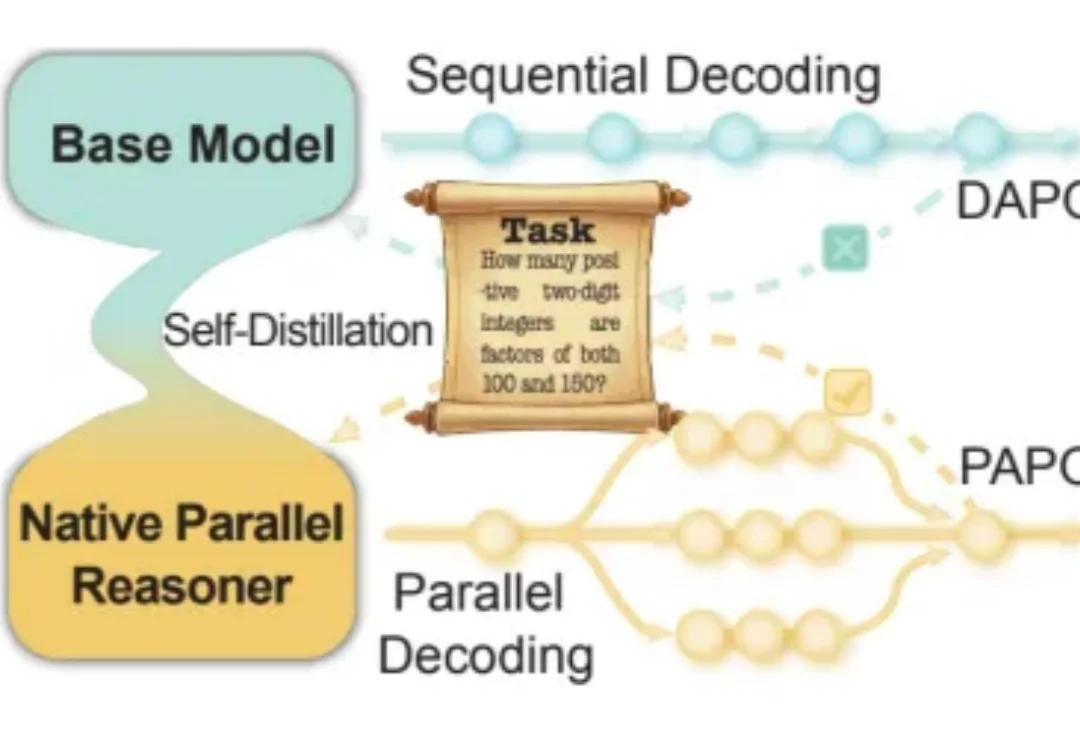
近年来,大语言模型在「写得长、写得顺」这件事上进步飞快。但当任务升级到真正复杂的推理场景 —— 需要兵分多路探索、需要自我反思与相互印证、需要在多条线索之间做汇总与取舍时,传统的链式思维(Chain-of-Thought)往往就开始「吃力」:容易被早期判断带偏、发散不足、自我纠错弱,而且顺序生成的效率天然受限。
硅谷宠物情感智能公司Traini宣布已完成超5000万元人民币融资,资金将主要用于多模态情感模型研发、软硬件产品迭代及海外市场扩张。老股东Tao Foundation及小米联合创始人洪峰继续跟投。

近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。

当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
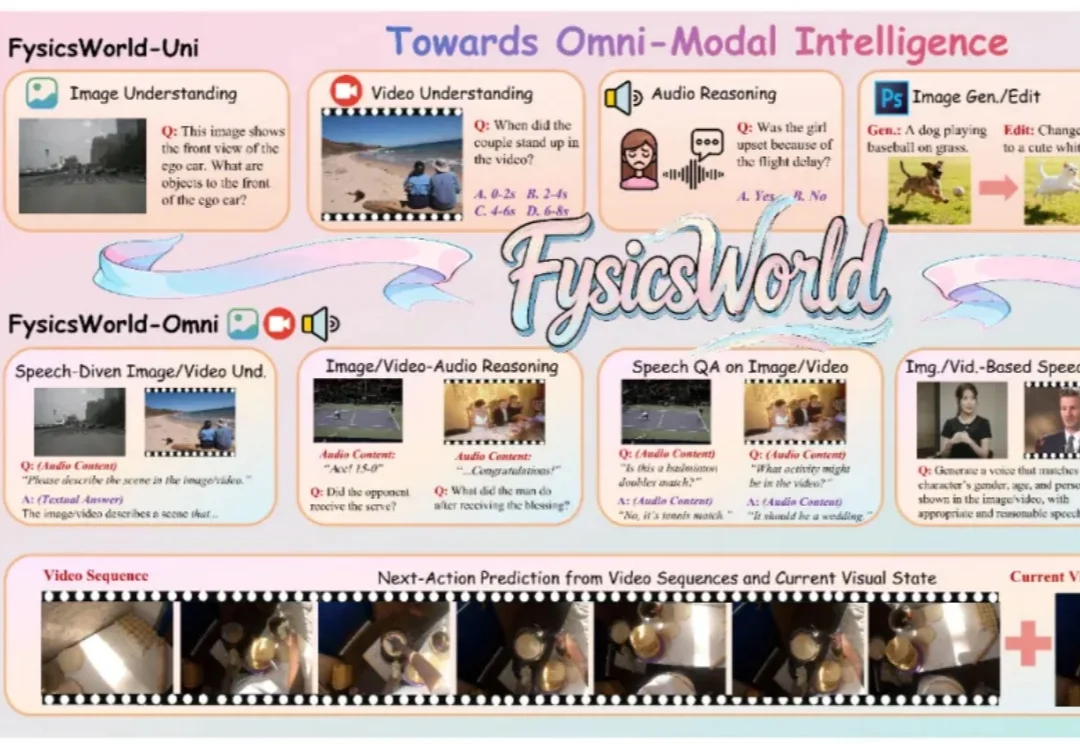
近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。
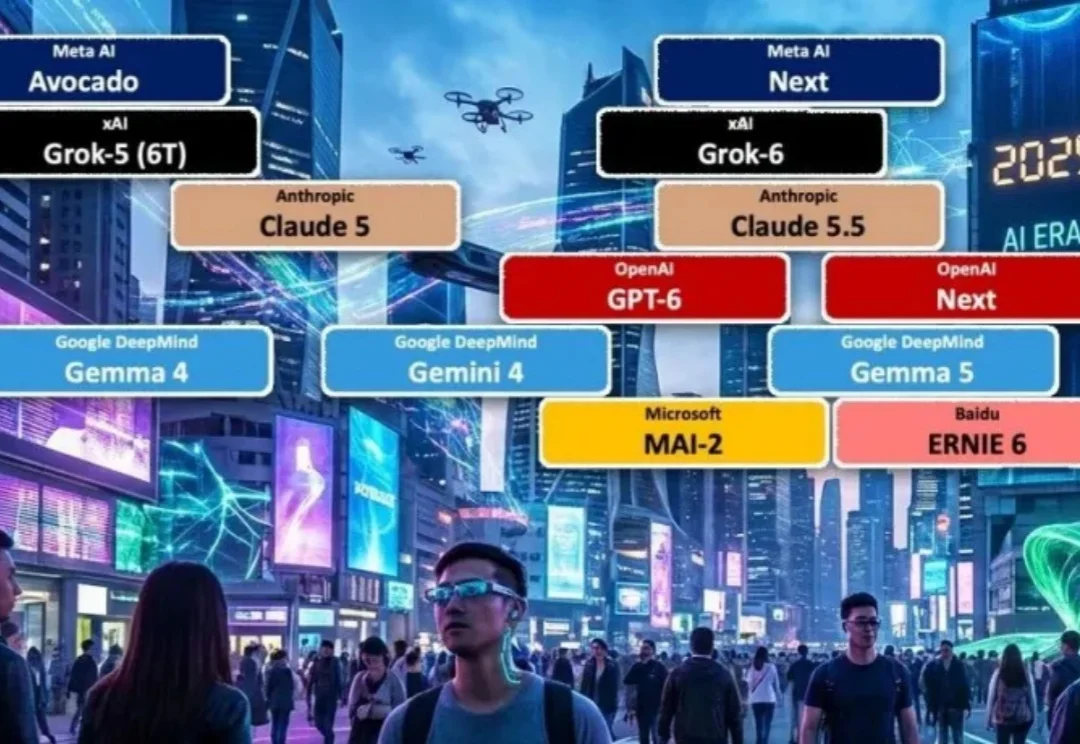
别被 2025 年的模型乱战骗了!这可能是一个巨大的误判。 LifeArchitect在上帝视角复盘:当下的喧嚣不过是爆发前的「基建期」。 到2026年,从6T规模的Grok-5到消失在后台的GPT-6,全行业正迎来一场蓄谋已久的「集体解锁」。 真正的换代不再是变聪明,而是像iPhone焊死iOS那样,让AI彻底成为文明的基础设施。