京东AI购抢先实测,一句话搞定吃喝穿用,背靠自研大模型
京东AI购抢先实测,一句话搞定吃喝穿用,背靠自研大模型第二款大厂出品的生活服务类AI原生应用来了!
来自主题: AI资讯
6572 点击 2025-12-30 11:19
 搜索
搜索
第二款大厂出品的生活服务类AI原生应用来了!
现有的AI视频生成模型虽然在短片上效果惊人,但面对一首完整的歌曲时往往束手无策——画面不连贯、人物换脸、甚至完全不理会歌词含义。
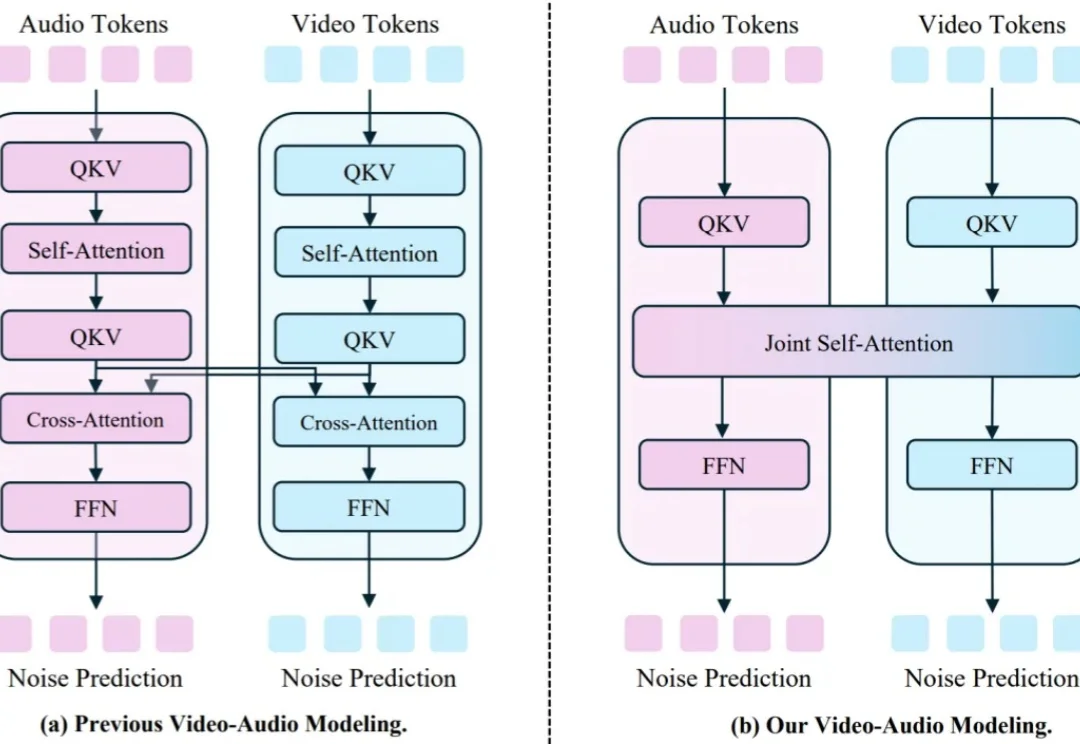
视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。
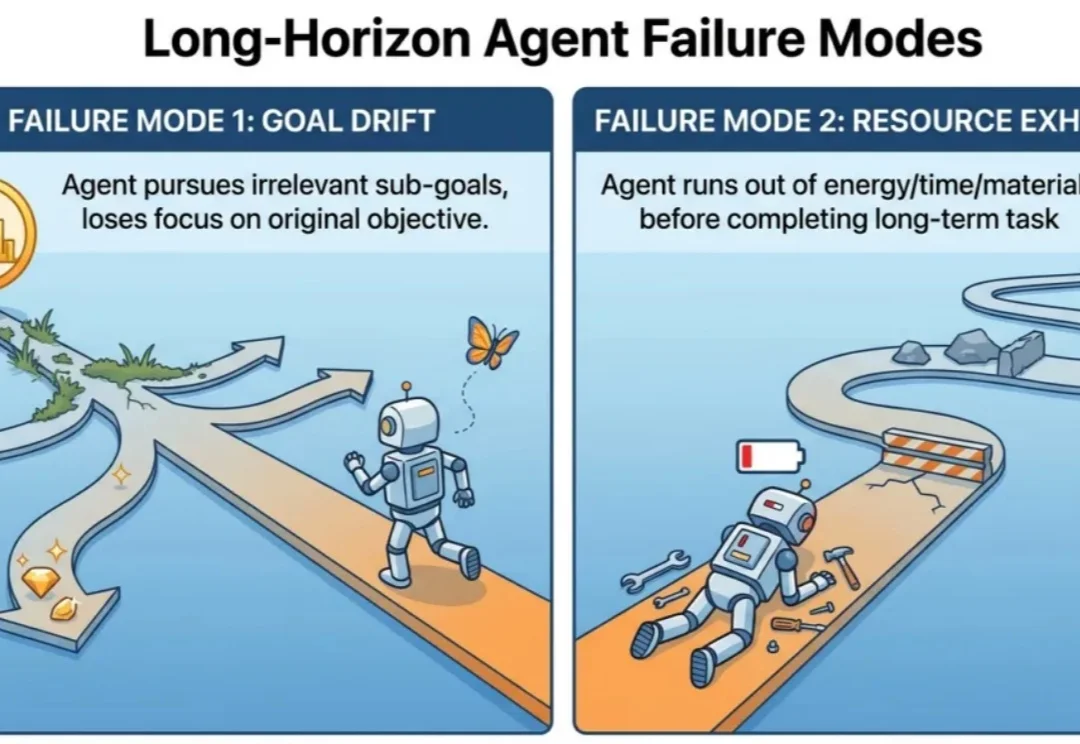
做agent简单,但是做能落地的agent难,做能落地的长周期agent更是难上加难!

在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。
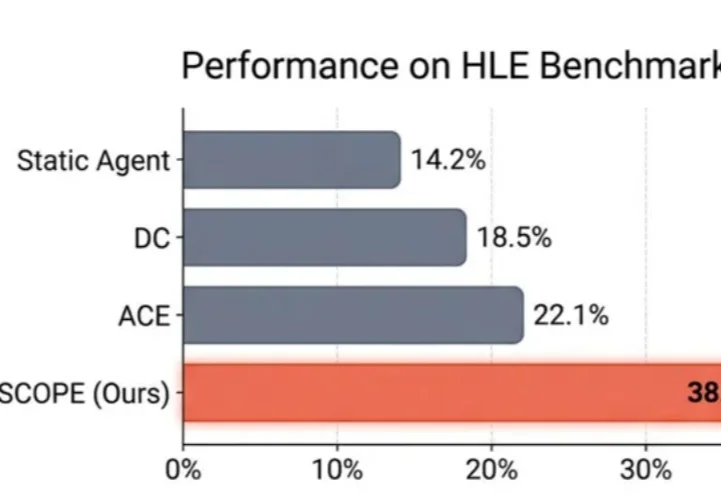
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

在电影与虚拟制作中,「看清一个人」从来不是看清某一帧。导演通过镜头运动与光线变化,让观众在不同视角、不同光照条件下逐步建立对一个角色的完整认知。然而,在当前大量 customizing video generation model 的研究中,这个最基本的事实,却往往被忽视。

世界模型的场景,不止在自动驾驶方面。 极客公园近期接触到的 Deep Optica,刚刚完成由 BV 百度风投、零以创投参与的种子轮融资,正试图从「判断方式」本身入手,为这一高度不确定的过程提供一种更加结构化的路径。

组织调整后的模型答卷,将对腾讯至关重要。《智能涌现》从多名独立信源处获悉,近日,出于个人发展原因,原腾讯 AI Lab副主任俞栋将从腾讯离职。截至发稿前,腾讯官方暂未回复。
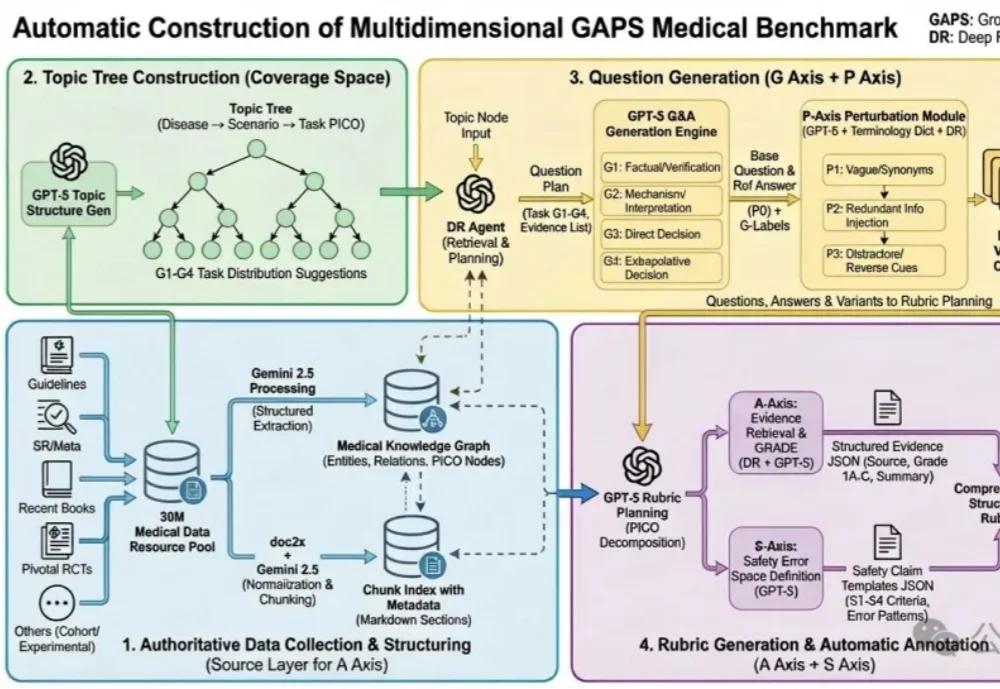
蚂蚁健康与北京大学人民医院王俊院士团队历时6个多月,联合十余位胸外科医生共同打磨,发布了全球首个大模型专病循证能力的评测框架—— GAPS(Grounding, Adequacy, Perturbation, Safety),及其配套评测集 GAPS-NSCLC-preview。