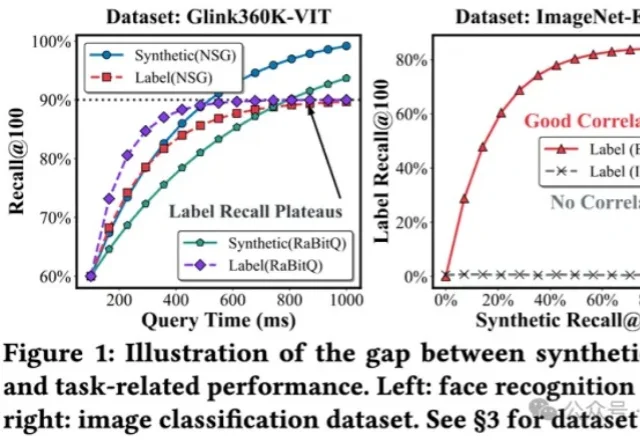
向量检索爆雷!傅聪联合浙大发布IceBerg Benchmark:HNSW并非最优,评估体系存在严重偏差
向量检索爆雷!傅聪联合浙大发布IceBerg Benchmark:HNSW并非最优,评估体系存在严重偏差将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。
来自主题: AI技术研报
7492 点击 2025-12-26 09:40
 搜索
搜索
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。
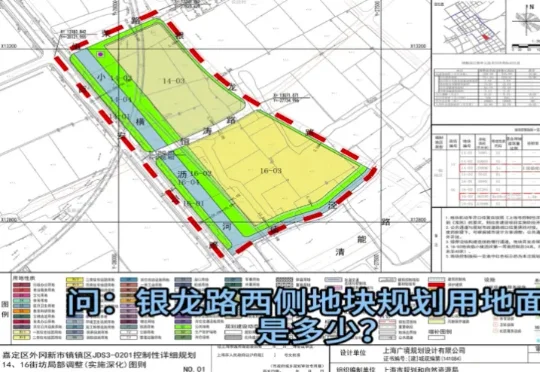
近日,由上海市规划资源局与商汤大装置联合打造的全国规划资源领域首个基础大模型“云宇星空大模型”(专业版)上线。这并非一个简单的对话机器人,而是一个6000亿参数、深度嵌入规资全业务系统的行业大模型:它能调取地图、做统计,能理解规划图纸、会写报告,覆盖从知识检索、空间分析到决策支撑的完整工作闭环。

“我其实天生就是一个适合创业的人。”

刚刚,由SciMaster团队推出的AI机器学习专家ML-Master 2.0,基于国产开源大模型DeepSeek,在OpenAI权威基准测试MLE-bench中一举击败Google、Meta、微软等国际顶流,刷新全球SOTA,再次登顶!目前该功能已在SciMaster线上平台开放waiting list,欢迎申请体验。

什么?决定 AI 上限的已不再是底座模型,而是外围的「推理编排」(Orchestration)。
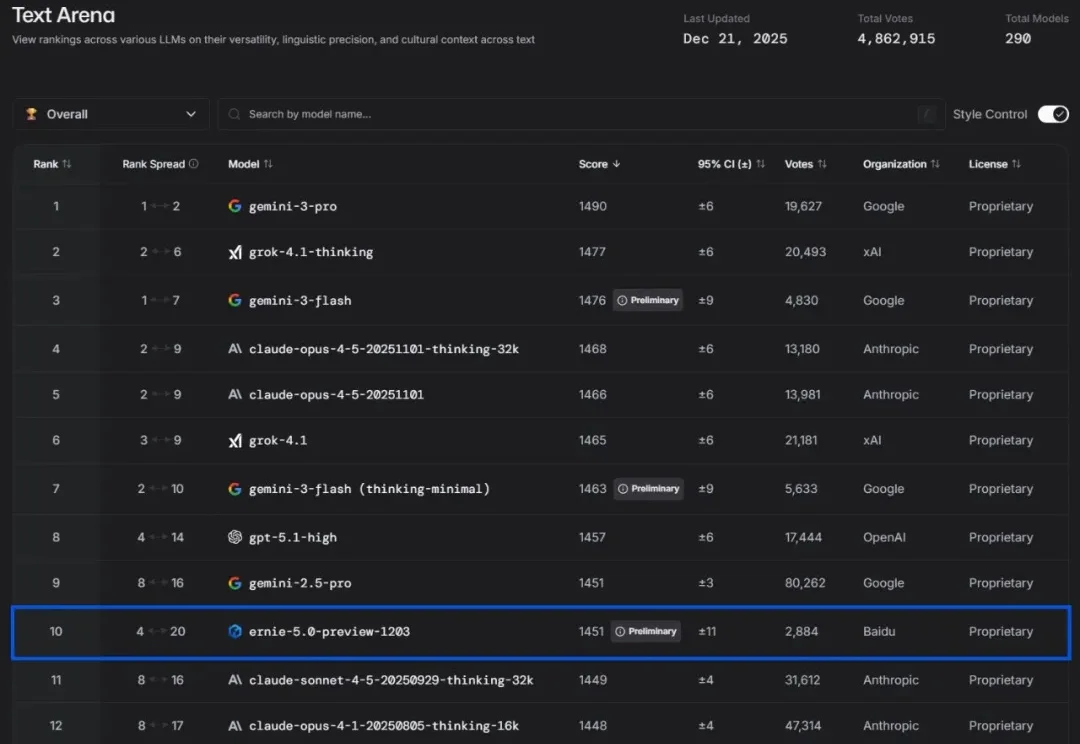
时间过得太快了,一转眼就来到了 2025 年的年底。我们距离 2026 年只剩下了 8 天。回看 AI 模型和产品突飞猛进这一年,中美两家 AI 阵营的行业发展路径有了挺大的区分,大家的关注度不再是单一模型、单一能力,而是“模型+工程+场景”的复合能力。这个变化在年底愈发明显。

英伟达让AI仅靠「看直播」就学会了通用游戏操作。虚拟世界已成为物理智能的黑客帝国,看4万小时直播学会几乎所有游戏!
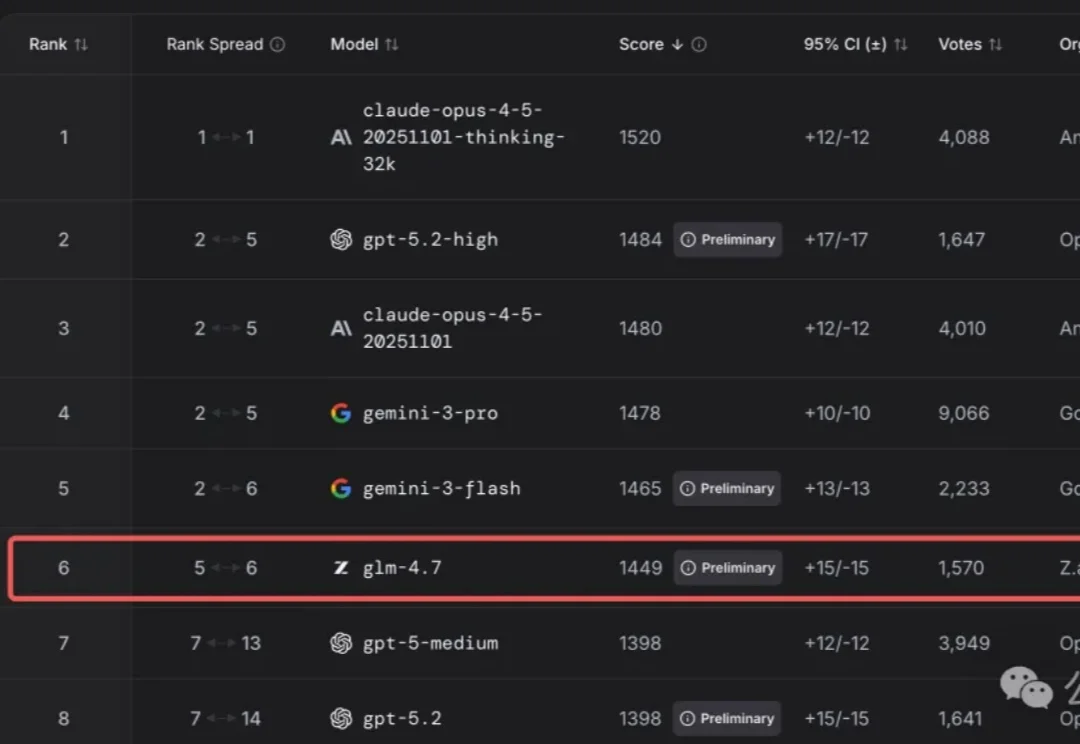
真是越到年底,越是神仙打架。
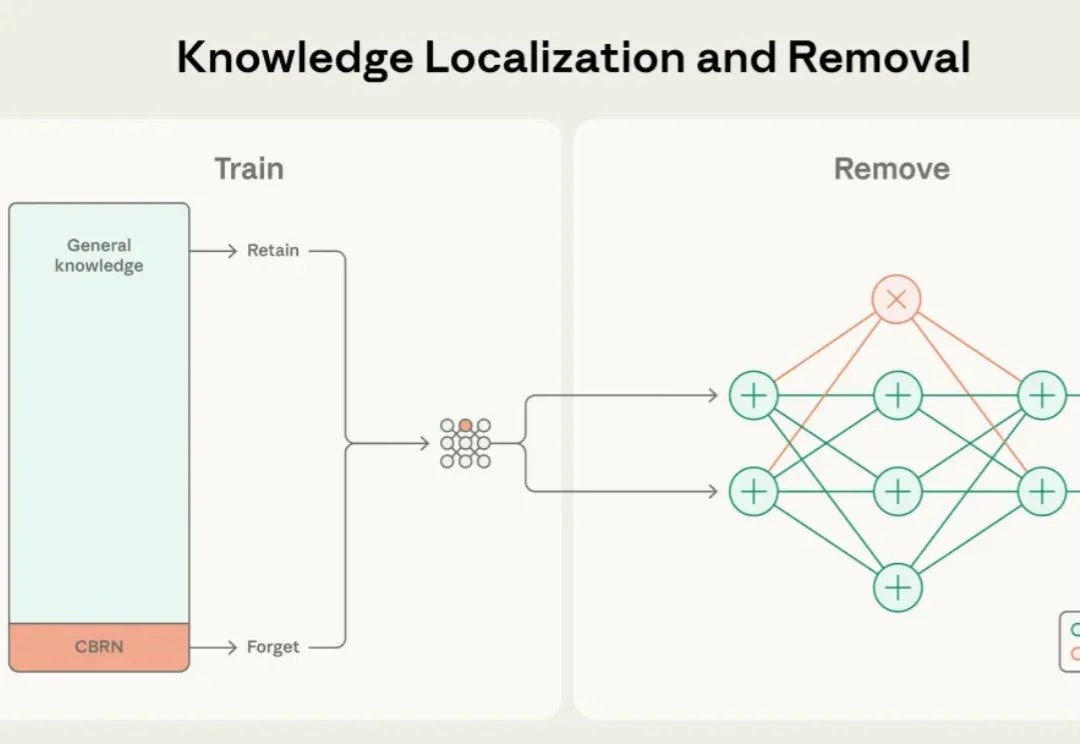
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。

智谱作为「大模型第一股」赴港上市前夕,直接掏出了旗舰模型GLM-4.7并开源!