Cursor 首度揭秘:"训练即产品",用强化学习让 AI 编程快 4 倍的秘密武器
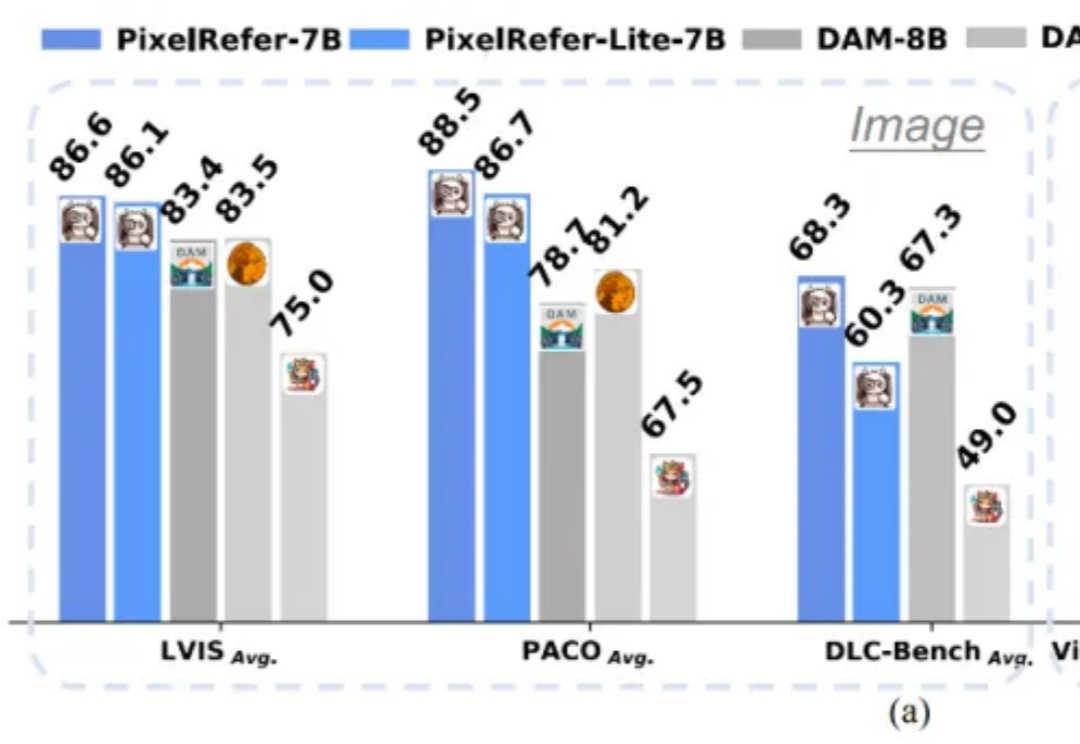
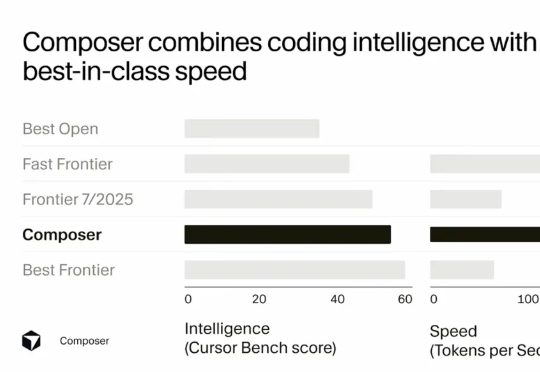
Cursor 首度揭秘:"训练即产品",用强化学习让 AI 编程快 4 倍的秘密武器Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。
来自主题: AI技术研报
9229 点击 2025-11-11 11:12