清北联合推出Motion Transfer,比肩Gemini Robotics,让机器人直接从人类数据中端到端学习技能
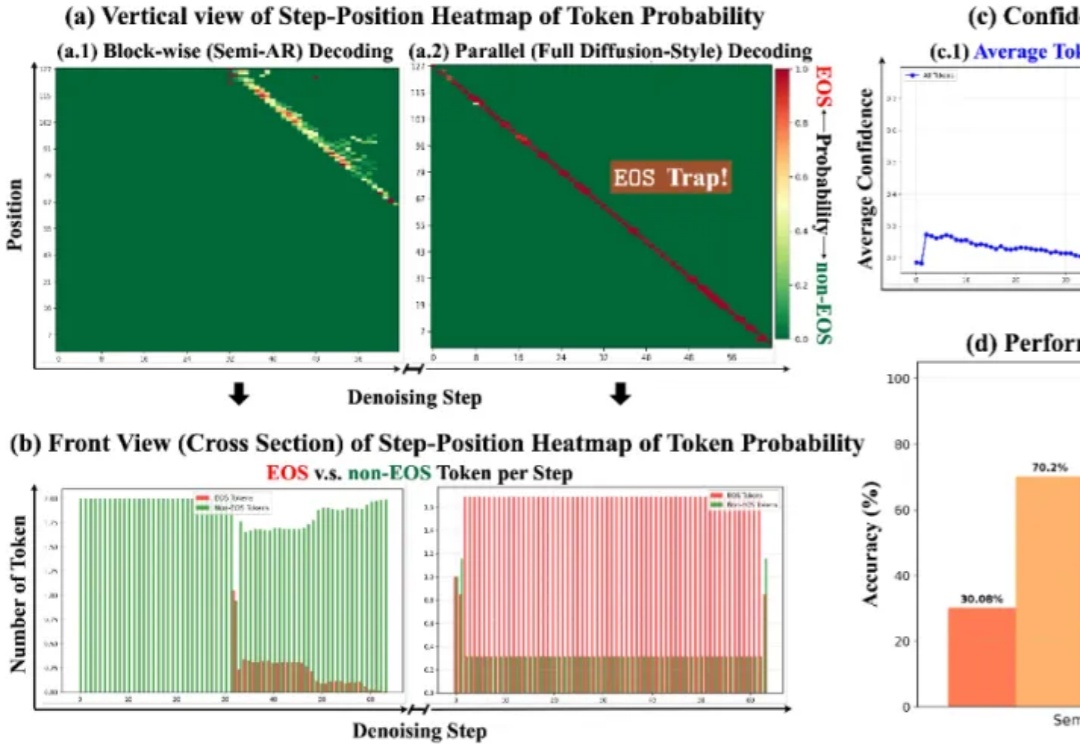
清北联合推出Motion Transfer,比肩Gemini Robotics,让机器人直接从人类数据中端到端学习技能近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。
来自主题: AI技术研报
9178 点击 2025-11-05 16:39