
豆包、Kimi等10个AI大模型勇闯美股,谁才是最猛的那个?
豆包、Kimi等10个AI大模型勇闯美股,谁才是最猛的那个?新乐子来了。 10个AI大模型,券商账户实时交易,勇闯美股。 除了老面孔GPT、Claude、Gemini、Grok、Qwen、DeepSeek,这次四个国产新玩家,豆包、Minimax、Kimi、文心也加入战场。昨晚,首战正式开赛,豆包已经一马当先,开始了开门红。
来自主题: AI资讯
10203 点击 2025-11-06 10:02
 搜索
搜索
新乐子来了。 10个AI大模型,券商账户实时交易,勇闯美股。 除了老面孔GPT、Claude、Gemini、Grok、Qwen、DeepSeek,这次四个国产新玩家,豆包、Minimax、Kimi、文心也加入战场。昨晚,首战正式开赛,豆包已经一马当先,开始了开门红。
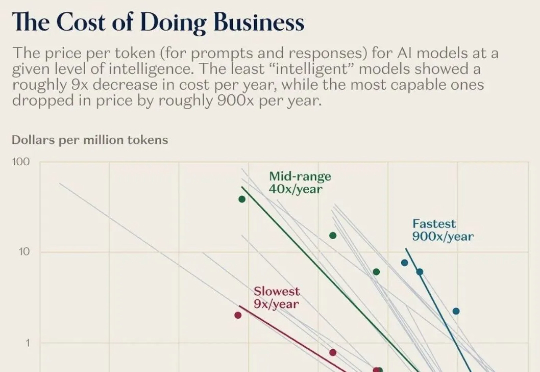
过去一年,AI模型的价格暴跌百倍!同样一句话,去年要10块,现在只要几分钱。可与此同时,家政、育儿、心理咨询、维修.....这些「手工活」越来越贵。科技正在疯狂通缩,生活却越来越通胀。这不是经济学笑话,而是Jevons与Baumol共同制造的现实:当机器更聪明,人工就更昂贵。

AI看视频也能划重点了!
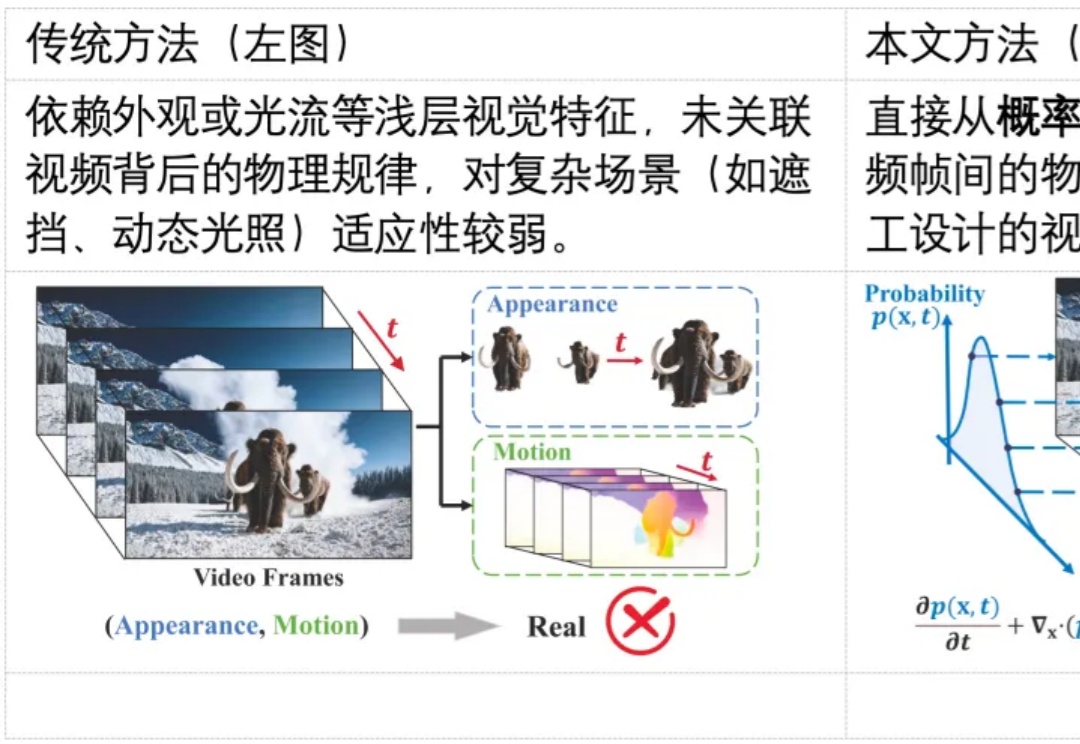
随着生成式 AI(如 Sora)的发展,合成视频几乎可以以假乱真,带来了深度伪造与虚假信息传播的风险。现有检测方法多依赖表层伪影或数据驱动学习,难以在高质量生成视频中保持较好的泛化能力。其根本原因在于,这些方法大都未能充分利用自然视频所遵循的物理规律,挖掘自然视频的更本质的特征。

静态编排 VS 动态编排,谁是多agent系统最优解?通常来说,面对简单问题,采用react模式的单一agent就能搞定。可遇到复杂问题,单一agent就会立刻出现包括但不限于以下问题:串行执行效率低:无法同时完成并行的子步骤(如 “同时爬取 A、B 两个网站的数据”)。
一直以来,关于人工生命(Artificial Life, ALife)的研究致力于回答这样一个问题:生命的复杂性能否在计算系统中自然涌现?

银河通用联合多所大学发布了全球首个跨本体全域环视导航基座大模型NavFoM,让机器人能自己找路,而不再依赖遥控,从而推动具身智能向规模化商业落地演进。

当前机器人领域,基础模型主要基于「视觉-语言预训练」,这样可将现有大型多模态模型的语义泛化优势迁移过来。但是,机器人的智能确实能随着算力和数据的增加而持续提升吗?我们能预测这种提升吗?

比Nano Banana更擅长P细节的图像编辑模型来了,还是更懂中文的那种。

谷歌遗珠与IBM预言:一文点醒Karpathy,扩散模型或成LLM下一步。