
苹果提出新型反向传播:一台iPhone 15 Pro Max就能微调LLM
苹果提出新型反向传播:一台iPhone 15 Pro Max就能微调LLM用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?
来自主题: AI技术研报
10232 点击 2025-10-30 17:27
 搜索
搜索
用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
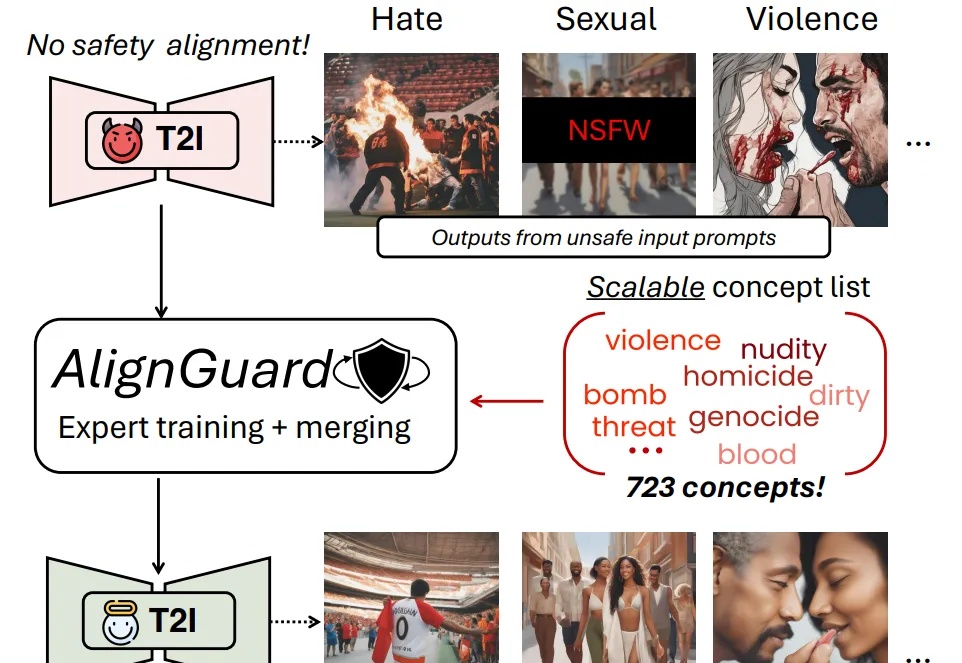
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
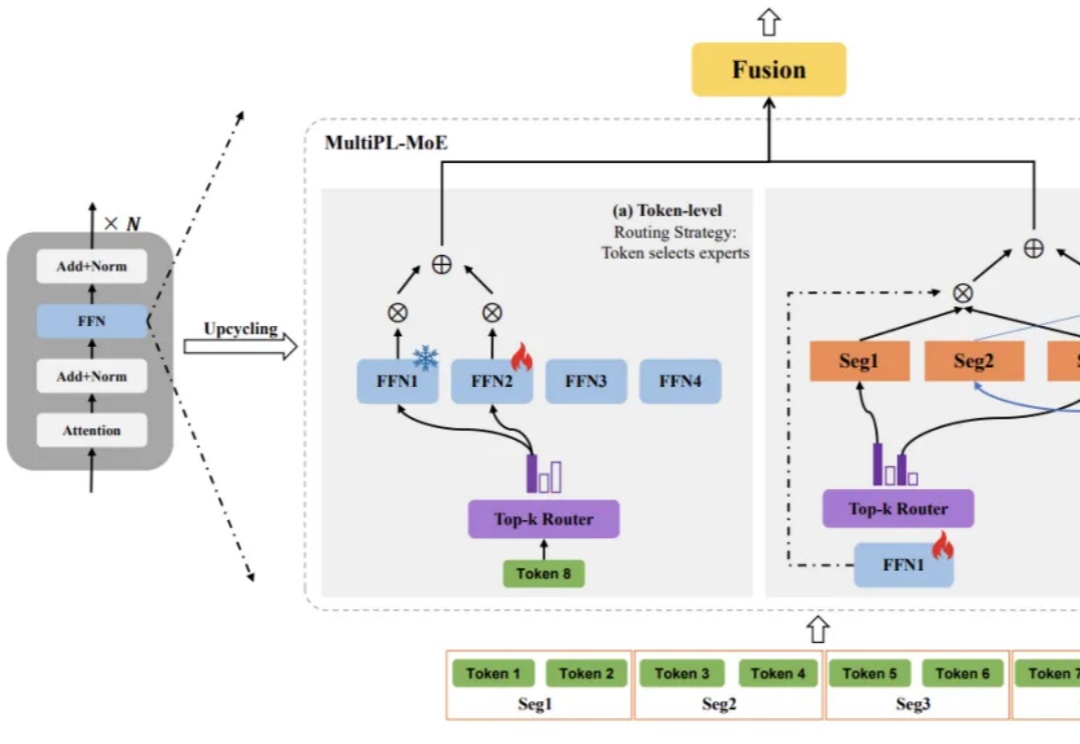
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

这次不仅发布自研编码模型Composer,还重构了IDE交互逻辑,可以最多8个智能体同时跑,早期测试和开发者都说Cursor 2.0真的太快了。Composer的速度是同等模型的4倍。Cursor说这是一款专门为低延迟智能编码打造的模型,大部分任务都可以在30秒以内完成。

杨红霞要走一条和阿里、字节截然不同的模型训练之路。

具身智能赛道的想象力,远比眼前的机器人要辽阔。

读者,您好!今天想跟您聊一个硬核又极具启发性的项目——HGM(Huxley-Gödel Machine)。我刚刚一起花了几个小时,从环境配置的坑,一路“打怪升级”到让它最终跑完,相信您可能已经从别的公众号上看到了这篇文章。
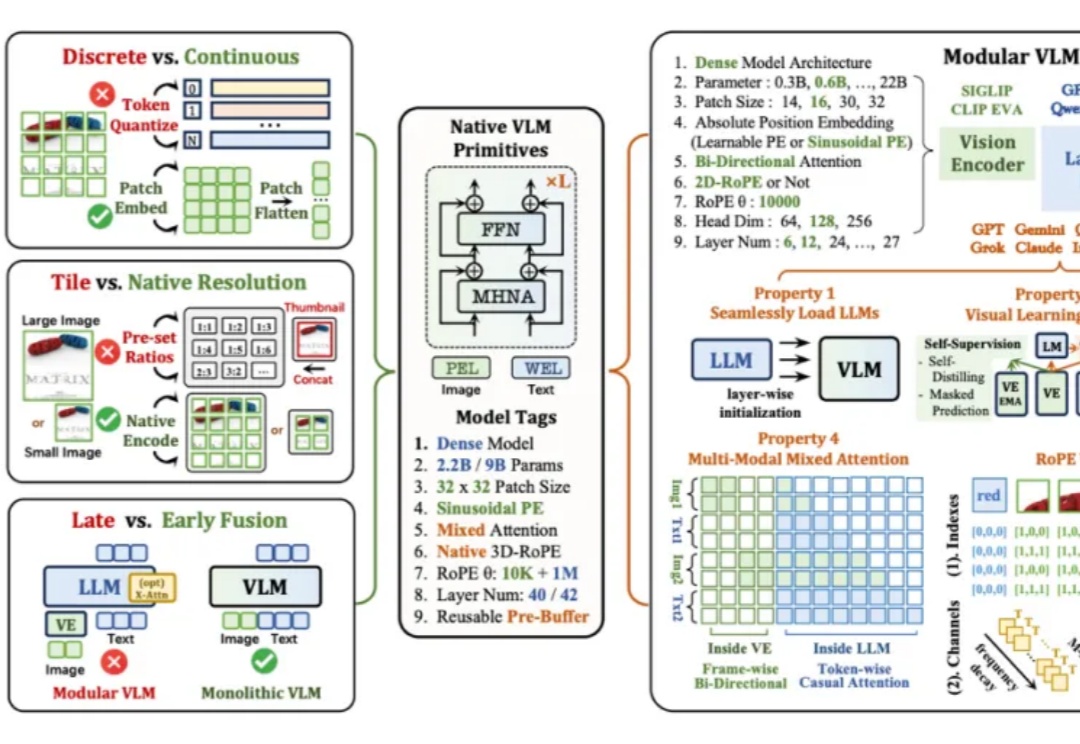
当下主流的视觉语言模型(Vision-Language Models, VLM),通常都采用这样一种设计思路:将预训练的视觉编码器与大语言模型通过投影层拼接起来。这种模块化架构成就了当前 VLM 的辉煌,但也带来了一系列新的问题——多阶段训练复杂、组件间语义对齐成本高,不同模块的扩展规律难以协调。
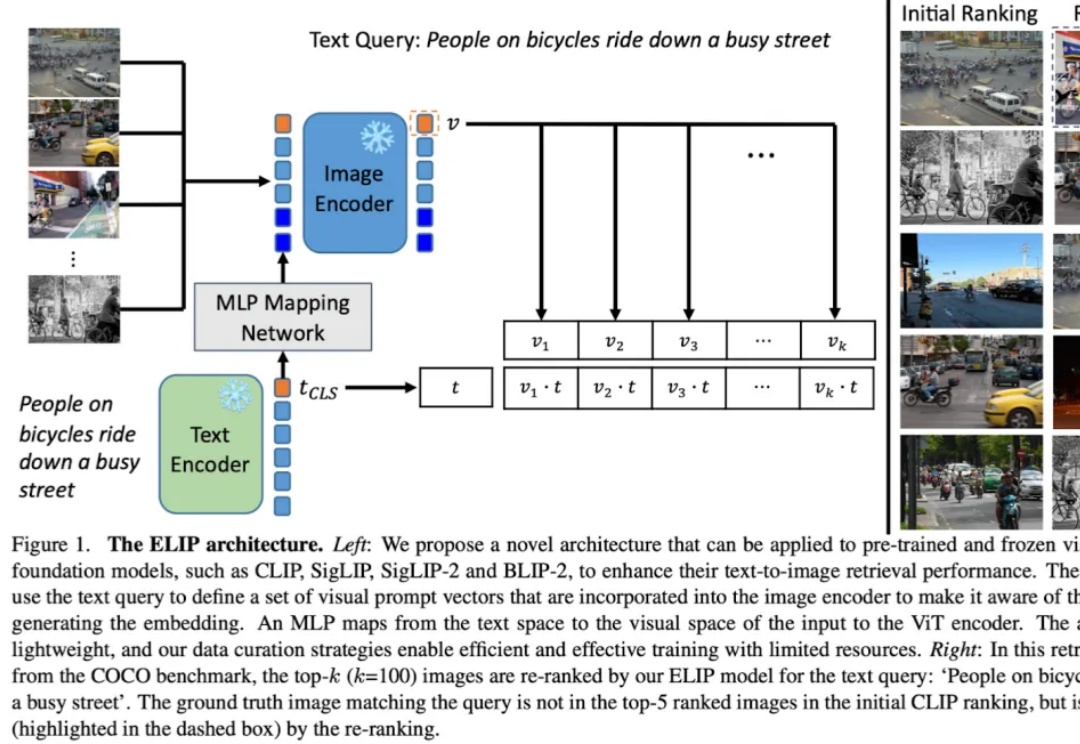
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。