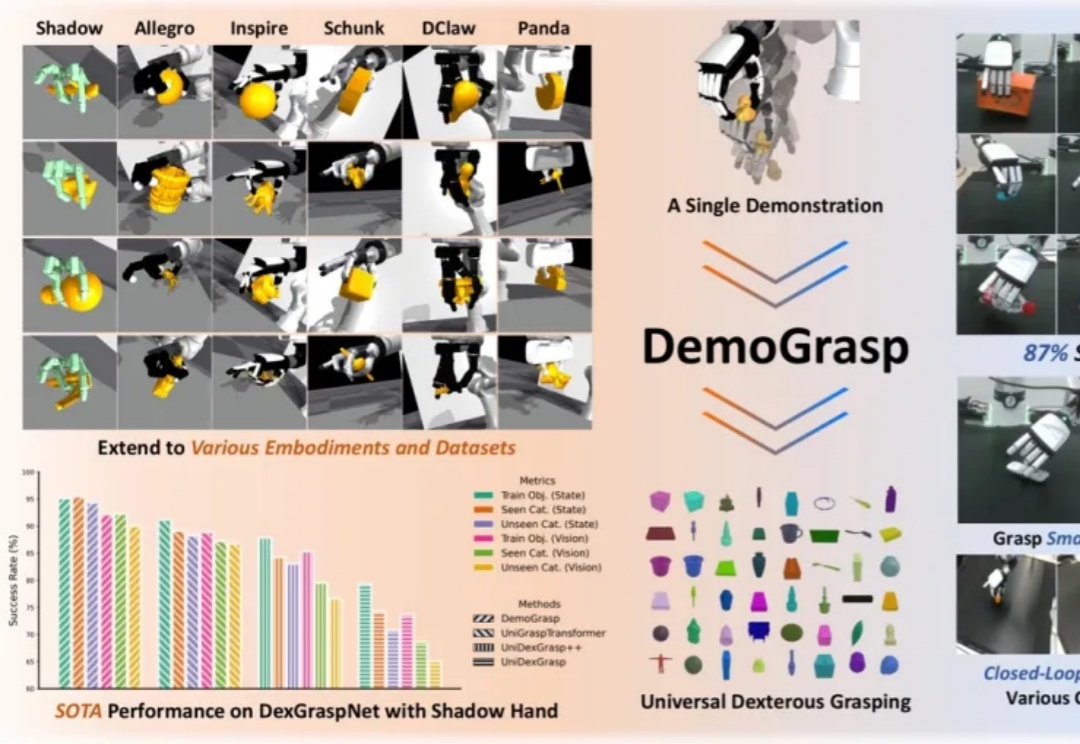
单条演示即可抓取一切:北大团队突破通用抓取,适配所有灵巧手本体
单条演示即可抓取一切:北大团队突破通用抓取,适配所有灵巧手本体在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。
来自主题: AI技术研报
6927 点击 2025-10-30 10:26
 搜索
搜索
在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%
国内首个利用世界模型生成数据实现真机泛化的端到端VLA具身基础模型GigaBrain-0重磅发布。
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。

AI风起云涌,数据隐私如履薄冰。华南理工大学联手深圳北理莫斯科大学,推出FedMSBA与FedMAR,筑成联邦学习的安全堡垒,守护个人隐私!
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。
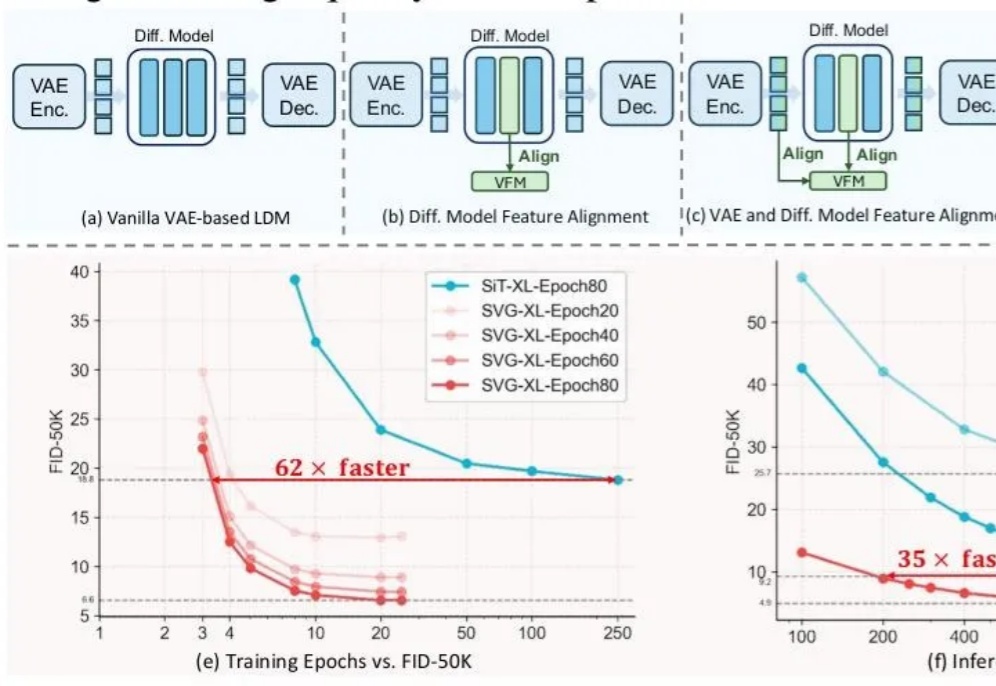
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
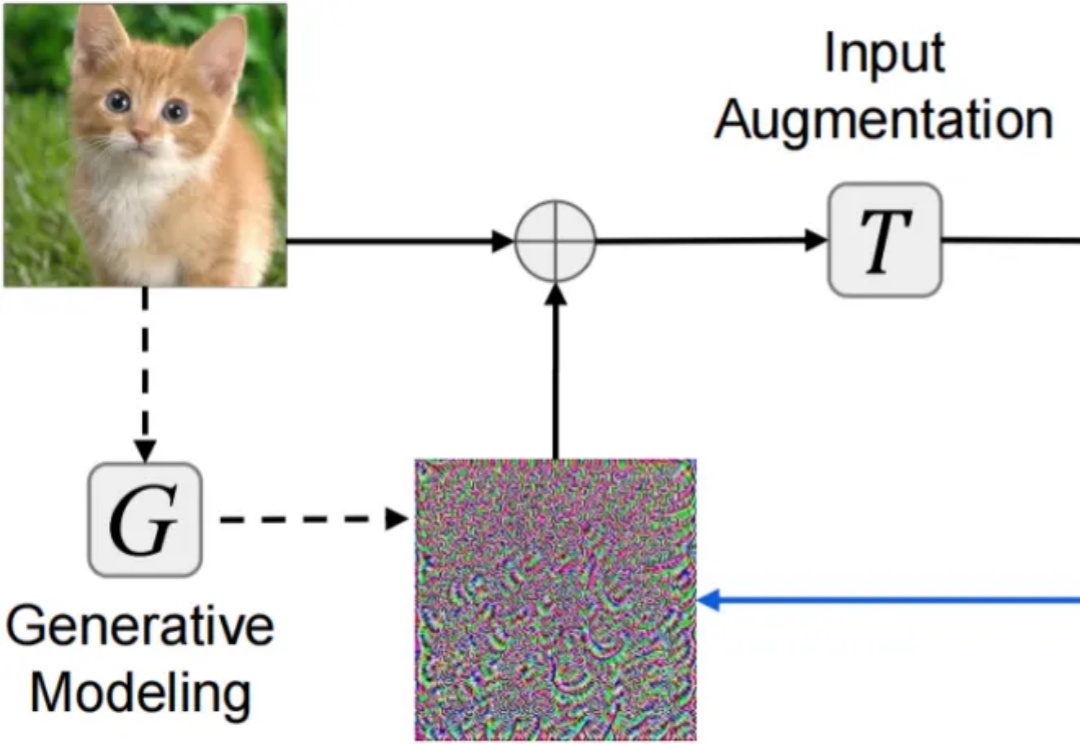
对抗样本(adversarial examples)的迁移性(transferability)—— 在某个模型上生成的对抗样本能够同样误导其他未知模型 —— 被认为是威胁现实黑盒深度学习系统安全的核心因素。尽管现有研究已提出复杂多样的迁移攻击方法,却仍缺乏系统且公平的方法对比分析:(1)针对攻击迁移性,未采用公平超参设置的同类攻击对比分析;(2)针对攻击隐蔽性,缺乏多样指标。

今天要讲的On-Policy Distillation(同策略/在线策略蒸馏)。这是一个Thinking Machines整的新活,这个新策略既有强化学习等在线策略方法的相关性和可靠性;又具备离线策略(Off-policy)方法的数据效率。

刚刚,这样一个消息在 Reddit 上引发热议:硅谷似乎正在从昂贵的闭源模型转向更便宜的开放源替代方案。