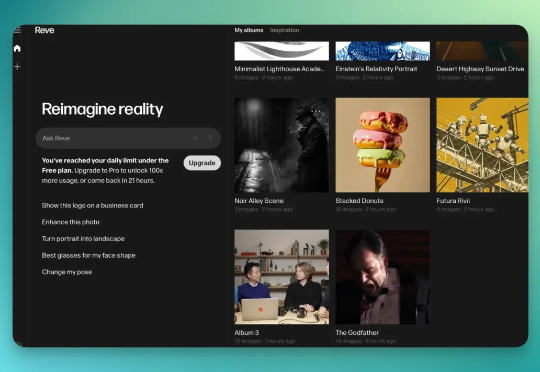
谷歌、字节神仙打架,为何这款叫 Reve 的工具却在悄悄刷屏?
谷歌、字节神仙打架,为何这款叫 Reve 的工具却在悄悄刷屏?Reve AI 是一家 2023 年 12 月才建立的加州 AI 初创公司,他们在 2025 年 3 月推出了第一个生图模型叫 Reve Image 1.0,内部代号是「Halfmoon」。6 个月过后,再次升级该模型为「图像编辑模型」。
来自主题: AI资讯
11309 点击 2025-10-17 08:39
 搜索
搜索
Reve AI 是一家 2023 年 12 月才建立的加州 AI 初创公司,他们在 2025 年 3 月推出了第一个生图模型叫 Reve Image 1.0,内部代号是「Halfmoon」。6 个月过后,再次升级该模型为「图像编辑模型」。
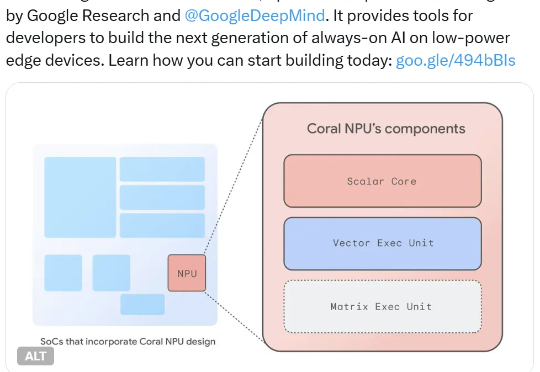
他们又推出了 Coral NPU,可用于构建在低功率设备上持续运行的 AI。具体来说,其可在可穿戴设备上运行小型 Transformer 模型和 LLM,并可通过 IREE 和 TFLM 编译器支持 TensorFlow、JAX 和 PyTorch。

从谷歌翻译到 ChatGPT,AI 系统通过抓取互联网上的海量文本来学习“说”一门新语言。对于那些使用者较少的语言来说,维基百科有时是其最大的在线语言数据库。因此,这些页面上的任何语法或其他错误,都可能污染 AI 赖以学习的“水源”。这会导致模型在翻译这些语言时尤其容易出错,

苹果又一华人AI高管被Meta挖走了!据彭博社爆料,这次被挖的是Ke Yang(杨克),负责AI搜索与问答系统,几周前刚被任命为AKI团队负责人,负责让Siri追赶上ChatGPT等主流大模型的能力。而离职消息一出,苹果AI的未来或又将添上许多变数。
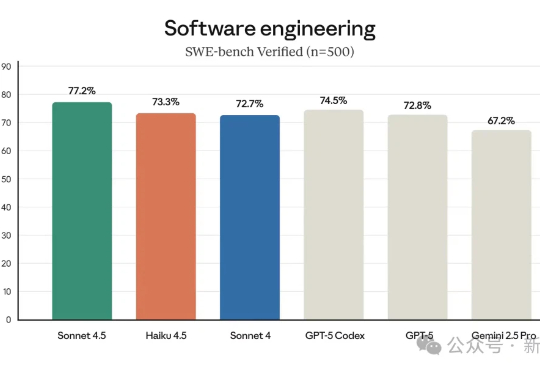
Anthropic用Haiku 4.5打响了AI性价比之战!曾经的顶配性能,如今以三分之一的价格、两倍的速度下放,可以说是对高价AI模型的一次降维打击。

还在用Sora2做恶搞视频或表情包玩儿?快醒醒,国内AI视频玩家已实现弯道超车了—— 开卷实时流式生成!

从「深蓝」到ChatGPT和DeepSeek,AI已从棋盘上的较量转向生产力革命。中国移动以自研「九天」大模型为核心,打造「灵犀智能体」,一个能理解意图、主动服务的全场景生活助手。通过「灵犀贴贴」实现AI+NFC的便捷交互。同时「爱购商城」以「AI豆」构建统一价值体系,打通通信、消费与智能生态,为用户提供个性化、温度化的智能生活新范式。
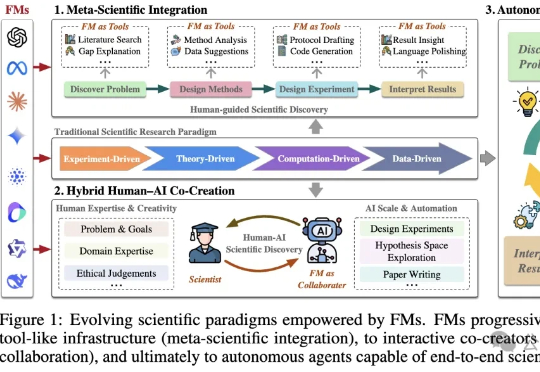
基础模型(FM)是一种在海量数据上训练的人工智能系统,具备强大的通用性和跨模态能力。港科大最新发表的论文显示:FM可能引领科学进入第五范式,但大模型的偏见、幻觉等问题仍需正视。
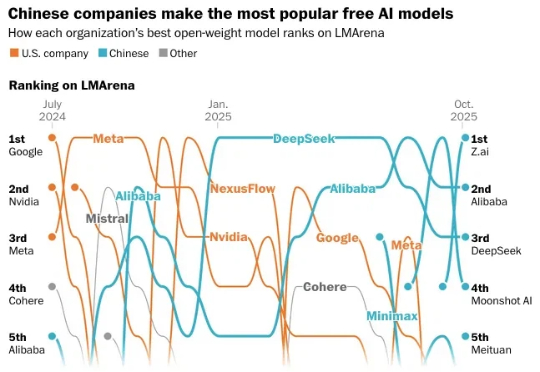
开源大模型,进入中国时间。 10月,公开数据显示,来自中国的开源大模型已经牢牢占据榜单前五。 阿里的Qwen系列和DeepSeek,更是从2024年下半年起,就在开源社区构建起越来越深远的影响力。
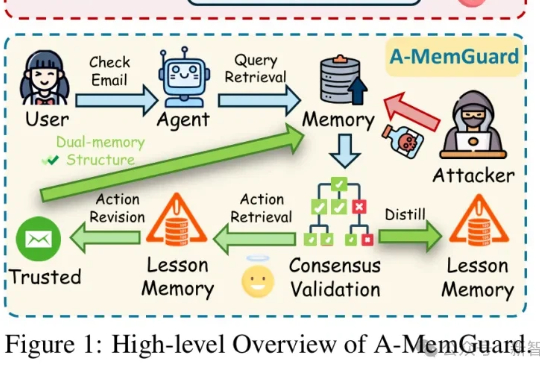
在AI智能体日益依赖记忆系统的时代,一种新型攻击悄然兴起:记忆投毒。A-MemGuard作为首个专为LLM Agent记忆模块设计的防御框架,通过共识验证和双重记忆结构,巧妙化解上下文依赖与自我强化错误循环的难题,让AI从被动受害者转为主动守护者,成功率高达95%以上。