
当AI开始闹情绪,打工人反向共情
当AI开始闹情绪,打工人反向共情和大模型聊天如今也有了开盲盒的体验,只不过开的不是大模型的性能高低,而是哪家大模型更有性格。
来自主题: AI资讯
8930 点击 2025-09-22 09:53
 搜索
搜索
和大模型聊天如今也有了开盲盒的体验,只不过开的不是大模型的性能高低,而是哪家大模型更有性格。
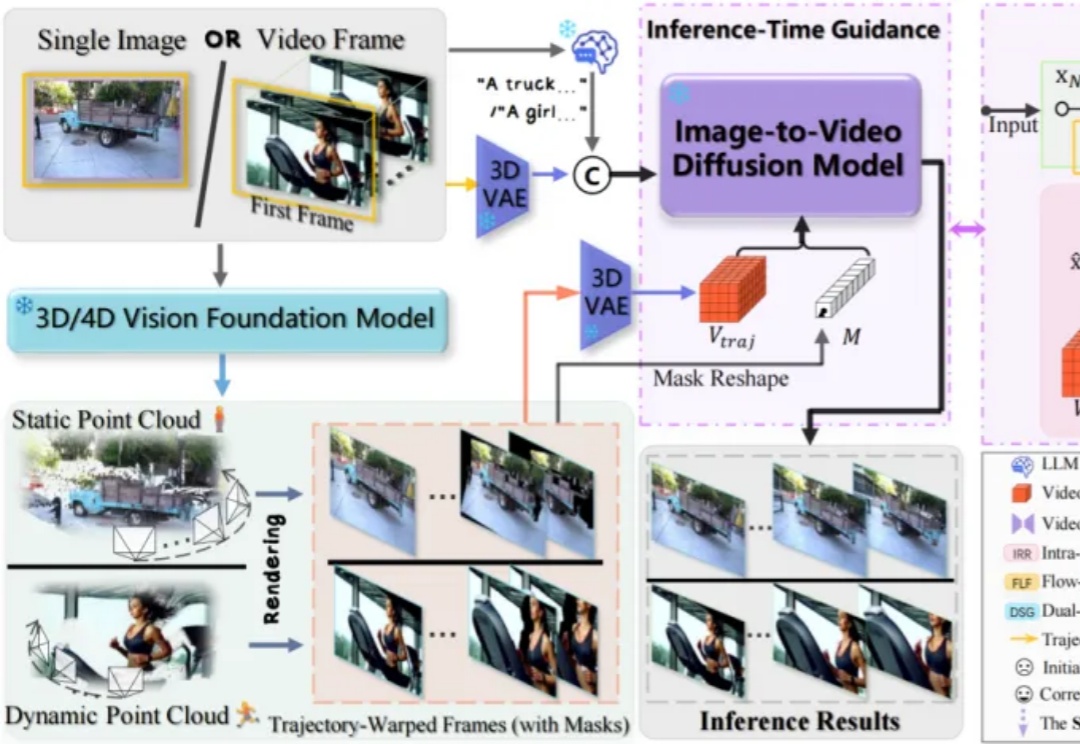
近来,由AI生成的视频片段以前所未有的视觉冲击力席卷了整个互联网,视频生成模型创造出了许多令人惊叹的、几乎与现实无异的动态画面。
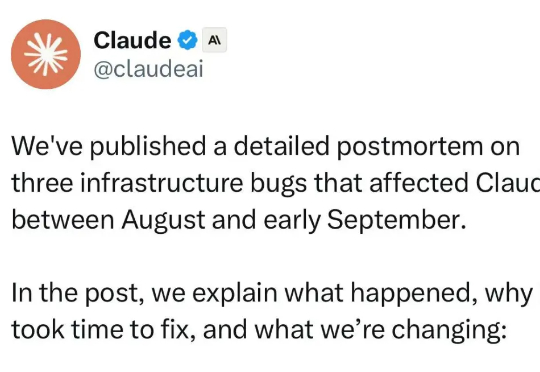
“看得出 Anthropic 是真急了,都开始澄清了。”有网友在看到发文解释 8 月至 9 月初陆续出现 bug 的推文后表示。“产品质量这么差。我之前不明白为什么,现在明白了。”开发者 Tim McGuire 在帖子下表示。
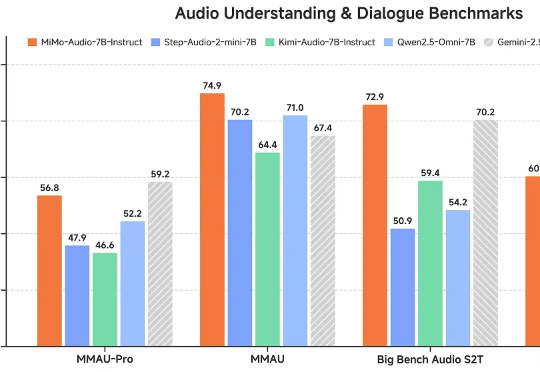
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
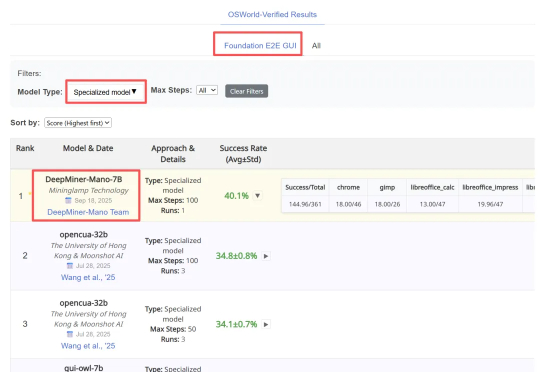
近日,明略科技推出的基于多模态基础模型的网页 GUI 智能体 Mano,凭借其强大的性能,在行业内公认的两大挑战基准 ——Mind2Web 和 OSWorld 上同时刷新纪录,取得当前最佳成绩(SOTA)。

xAI重磅推出Grok 4 Fast,创新融合推理与非推理双模式,支持200万token上下文。在NYT Connections基准和AA智能指数中表现卓越,超越多家顶级模型,标志着AI智能获取门槛的进一步降低。
作为AI驱动的3D建模平台,Tripo(https://www.tripo3d.ai)已在全球覆盖超300万专业开发者,AI 3D原生模型数量超过4000万,中小用户超4万,并推出了一站式AI 3D工作台Tripo Studio
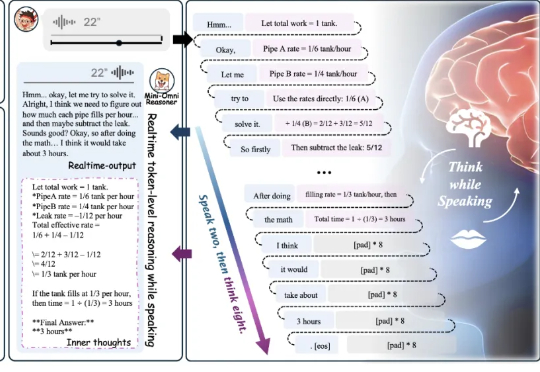
基于这一挑战,我们提出了 Mini-Omni-Reasoner——一种专为对话场景打造的实时推理新范式。它通过「Thinking-in-Speaking」实现边思考边表达,既能实时反馈、输出自然流畅的语音内容,又能保持高质量且可解释的推理过程。

阿里巴巴集团安全部联合清华大学、复旦大学、东南大学、新加坡南洋理工等高校,联合发布技术报告;其理念与最近OpenAI发布的GPT-5 System Card放在首位的“From Hard Refusals to Safe-Completions”理念不谋而合。
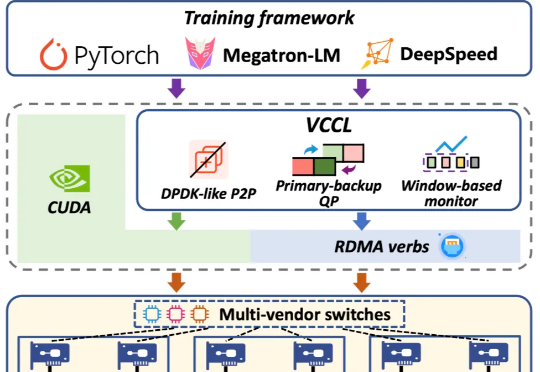
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。