
材料版AlphaFold来了!40个工业任务全方位SOTA,AI4S迎来行业大突破
材料版AlphaFold来了!40个工业任务全方位SOTA,AI4S迎来行业大突破AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
来自主题: AI技术研报
7539 点击 2026-06-01 14:58
 搜索
搜索
AI模型在电脑上预测精度爆表,一到实验室就各种出错用不了?
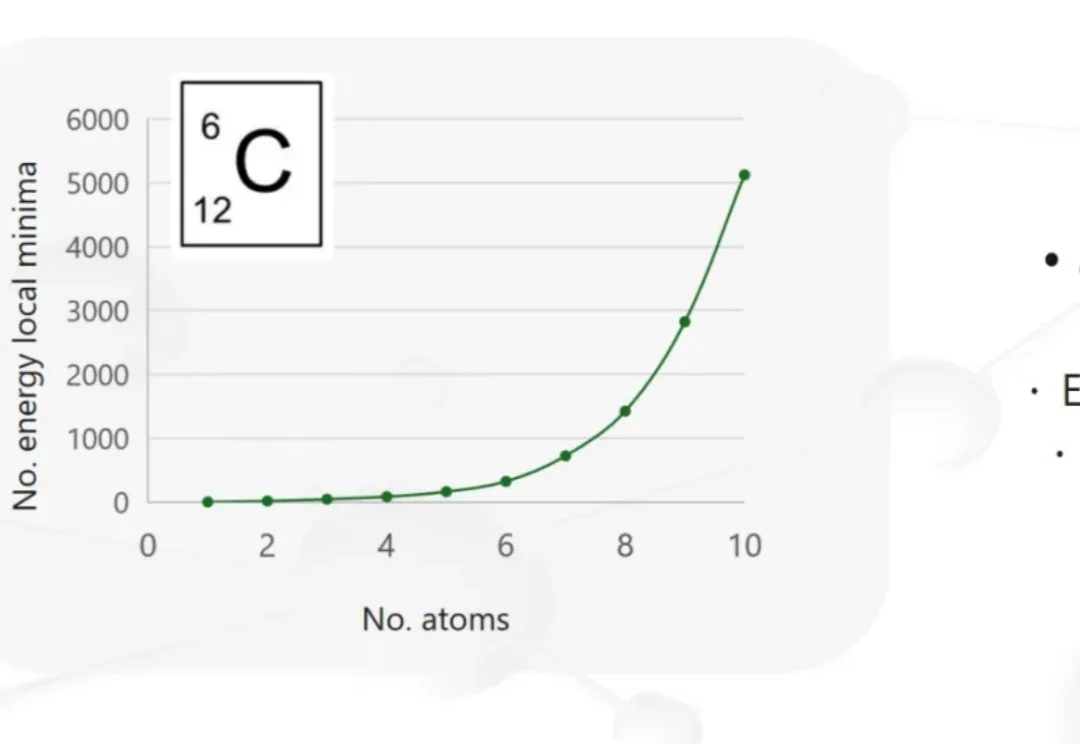
材料研发的“试错时代”,正在被AI加速改变。5月21日,未来光锥「AI for Science 创变者说」第二期沙龙“AI+材料的千亿级机会”,邀请了三位学界与产业一线嘉宾,共同探讨AI+材料科学的前沿与实践。

对于 Seedance 视频生成模型,大家都不陌生了。

紧跟DeepSeek价格战,小米掏出技术底牌!

连续创业的 York 开启了又一段新征程。过去十几年里,他几乎一直在做软硬一体系统:从计算机视觉、嵌入式,到后来的机器人。他的上一个创业项目——智能购物车 Caper AI,在 2021 年被 Instacart 以 3.5 亿美元收购。

“我们有点处在自己的科技泡沫里。”
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。
核心观点:由前Apple Vision Pro两位技术负责人联合创办的Reactor,近期完成5900万美元种子轮及A轮融资,由Lightspeed Venture Partners领投,WndrCo
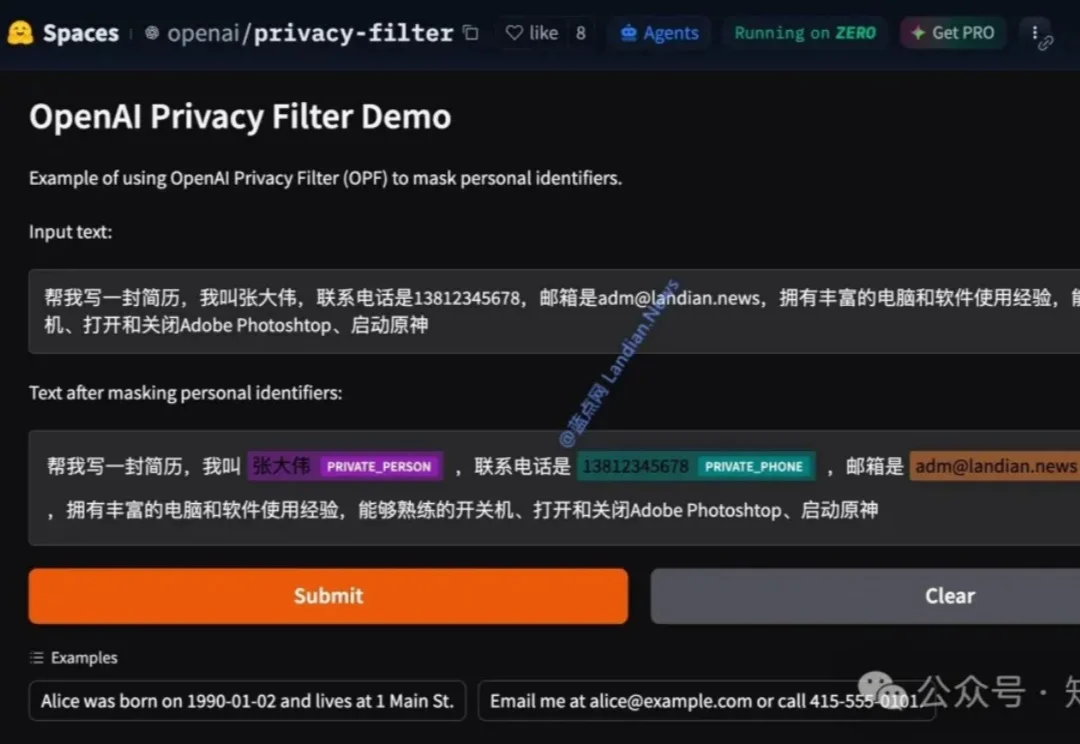
你有没有过这样的经历:把聊天记录、用户反馈或内部文档丢给大模型时,总担心里面夹杂着真实姓名、手机号、邮箱甚至 API key,最后只能手动一条条删?或者团队在处理海量数据时,规则写的正则永远漏掉那些“藏在句子里的隐私”。

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。