
刚刚,6000亿大模型股王智谱宣布重闯A股,拟募资150亿
刚刚,6000亿大模型股王智谱宣布重闯A股,拟募资150亿80%募资金额拟用于基座大模型研发。
来自主题: AI资讯
8092 点击 2026-06-02 11:59
 搜索
搜索
80%募资金额拟用于基座大模型研发。

华为天才少年被具身智能企业哄抢。AI 科技评论最新获悉,前华为天才少年李一同近期已加入具身智能明星公司吉翼智能,任吉翼大模型研发中心总工程师,将主导公司在大模型与系统测试等核心板块的攻坚工作。履历方面,李一同为上海交大ACM班毕业,墨尔本大学博士,曾是华为天才少年,华为终端云语言大模型技术负责人。华为期间,李一同主要负责基于生成式大模型和人机对话方向的研究。

1492 年,哥伦布驶向大西洋深处。远洋航行当然需要速度,但真正决定船队能否抵达彼岸的,是淡水、食物、船体、桅杆和帆索能否撑过漫长风暴。改写跨洋贸易的,正是这种并不浪漫的工程逻辑。 后来,荷兰人设计出

把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
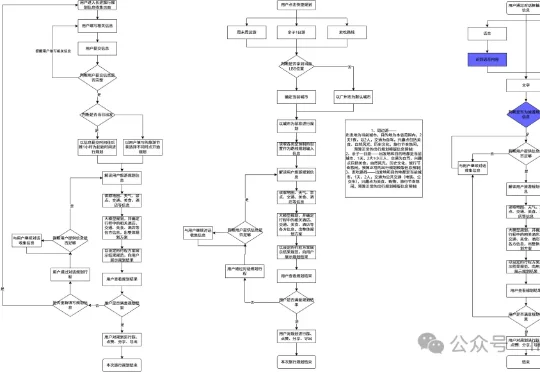
上一篇文章,和大家聊了一下这个项目,做了一个整体性的复盘,但主要是以业务和团队等方面说的,但是实现方案和大模型相关评估上,说的不多,这篇文章,我们就在产品实现方案和大模型这块来聊一下。
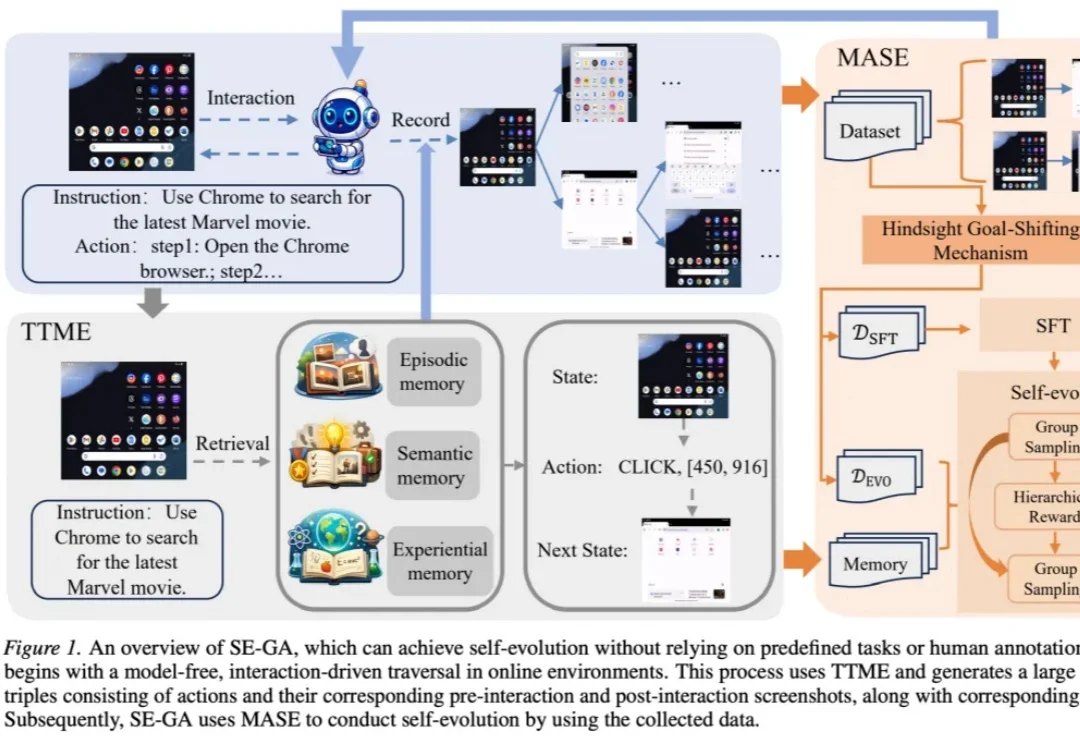
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

Mindverse 完成由美团领投的 A 轮融资,元禾璞华、韶音、变量资本和老股东追加跟投。Mindverse (心洲科技) 是少数把赌注押在模型「内部」的一家创企,它在通用大模型的基础上,用强化学习让它从复杂、多步骤的真实任务中学会如何把事做成,让模型从「知道很多」变为「能办好事」。

VAST近期完成合计近2亿美元的A+及A++轮融资,领投方为渶策资本、国寿长三角科创基金。拿到这笔钱的同时,VAST也带来了他们最新的世界模型进展:Project Eden。区别于业内「动作条件视频生成」与「静态3D场景生成」等常规路径,Project Eden创造性地将底层状态推演与视觉呈现进行了原生解耦。

卷更大的模型,不再是唯一答案。新问题是模型能不能在真实场景中越用越聪明。一家叫Trajectory的公司押注这一趋势,要把Cursor的成功秘密做成AI新基建。