
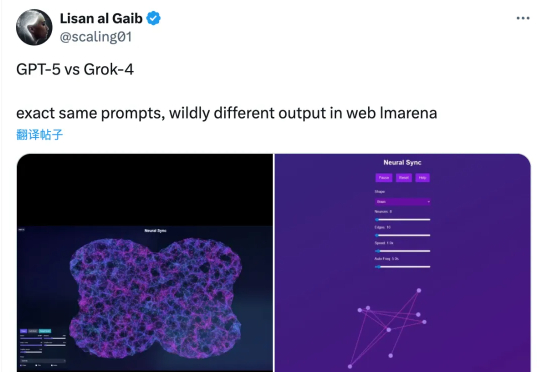
GPT-5实锤,悄悄上线代号「龙虾」!版本号曝光,实测编程惊人能改屎山代码
GPT-5实锤,悄悄上线代号「龙虾」!版本号曝光,实测编程惊人能改屎山代码就在刚刚,GPT-5悄悄身披马甲出道了?一个代号为「Lobster(龙虾)」的神秘模型在WebDev Arena横空出世,轻松吊打Grok-4,网友纷纷猜测:这就是GPT-5本尊!更有提前试用者曝出:GPT-5编程能力惊人,甚至能改屎山代码。
来自主题: AI资讯
10081 点击 2025-07-27 20:13
就在刚刚,GPT-5悄悄身披马甲出道了?一个代号为「Lobster(龙虾)」的神秘模型在WebDev Arena横空出世,轻松吊打Grok-4,网友纷纷猜测:这就是GPT-5本尊!更有提前试用者曝出:GPT-5编程能力惊人,甚至能改屎山代码。

据 AI 科技评论报道,前阿里通义实验室视觉负责人薄列峰已正式加盟腾讯混元大模型团队,直接向腾讯副总裁、混元项目负责人蒋杰汇报,主要负责多模态方向的技术攻坚。早在今年4月30日,薄列峰从阿里离职,外界曾一度传出他将赴美加入某大型科技公司,统筹多模态AI研发。如今尘埃落定,他最终选择落脚深圳,加入国内多模态竞争最激烈的战场之一。

AI教父Hinton中国首秀,在与周伯文教授的17分钟高密度对话中,他首次公开表示当今多模态大模型已具「意识」,并建议以不同技术训练「聪明」与「善良」AI。两人探讨AI主观体验、科学促进AI发展的路径,并寄语青年科研者:坚持怀疑与原创,突破才会发生。

在医学影像领域,AI的革命性进展已不稀奇——CT有了自动阅片系统,X光报告可由模型生成。但当聚光灯转向超声时,这一“最日常”的影像手段,却始终没有迎来真正的智能时代。为什么?

在大语言模型席卷全球的时代,坚持更接近生命本质的智能是少有人走的路。2025年7月初,一篇来自Numenta与Thousand Brains Project的论文,首次通过一个名为“Monty”的AI系统,实验性地验证了神经科学家杰夫·霍金斯(Jeff Hawkins)提出的“千脑智能理论”。
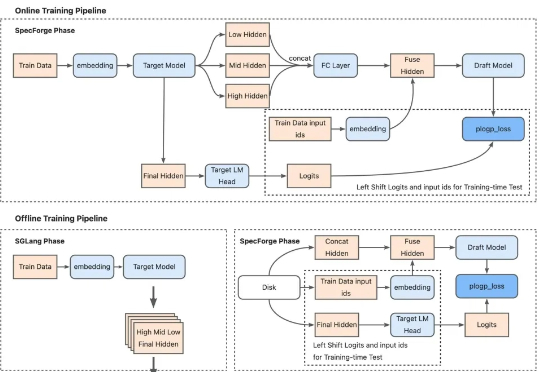
专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源! SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。
AI超级实用的落地,只有这家玩明白了。 前几天,奥特曼在采访中透露,亲自体验 GPT-5 后,被其强大的能力吓到。有个自己都搞不懂的问题,模型却能一下答出来,那一刻他甚至觉得自己在擅长的领域也有些「无力」。
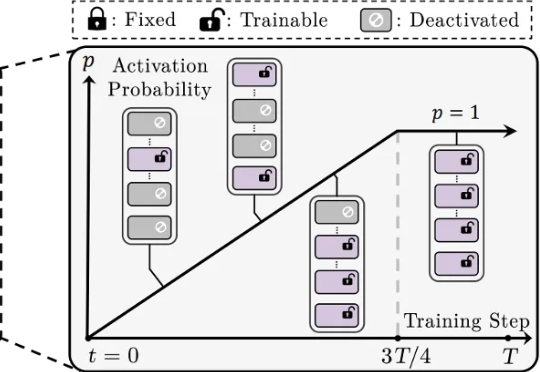
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。

这大概是大家玩得最开心的一届WAIC。在上海世博展览馆里,你能看到:机器狗托着AI眼镜“哒哒哒”走,机器人被绑了绳子“遛”机器狗,人们给自己绑上感应器,小心翼翼“遥操”着机器人搭积木、玩迷宫。
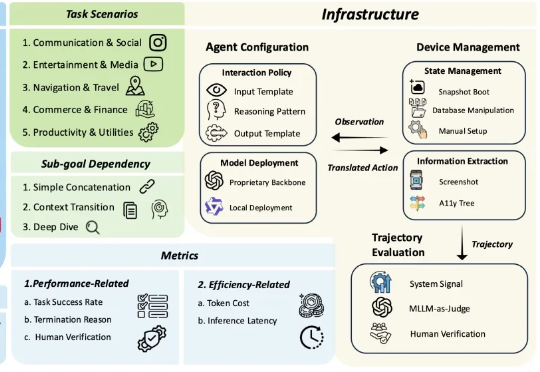
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。