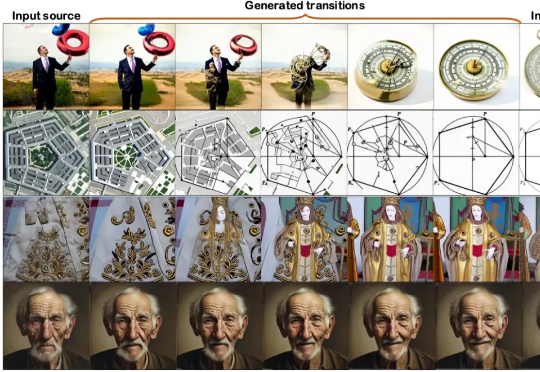
普林斯顿团队领衔发布最强开源数学定理证明模型:32B性能大幅超越前代SOTA DeepSeek 671B
普林斯顿团队领衔发布最强开源数学定理证明模型:32B性能大幅超越前代SOTA DeepSeek 671B近日,由普林斯顿大学牵头,联合清华大学、北京大学、上海交通大学、斯坦福大学,以及英伟达、亚马逊、Meta FAIR 等多家顶尖机构的研究者共同推出了新一代开源数学定理证明模型——Goedel-Prover-V2。
来自主题: AI资讯
9080 点击 2025-07-18 11:17