

如何教AI学会反思?
如何教AI学会反思?论文提出一种AI自我反思方法:通过反思错误原因、重试任务、奖励成功反思来优化训练。
来自主题: AI技术研报
8890 点击 2025-07-10 10:34
论文提出一种AI自我反思方法:通过反思错误原因、重试任务、奖励成功反思来优化训练。
我们先给不知道剧情的朋友回归一下事件事件线:2025年6月30日,华为宣布开源盘古7B稠密和72B混合专家模型。然而发布会后,网络上出现华为盘古大模型抄袭的言论。7月5日,诺亚方舟实验室发布《关于盘古大模型开源代码相关讨论的声明》。本以为官方已经出来站台,这件事到此为止。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。
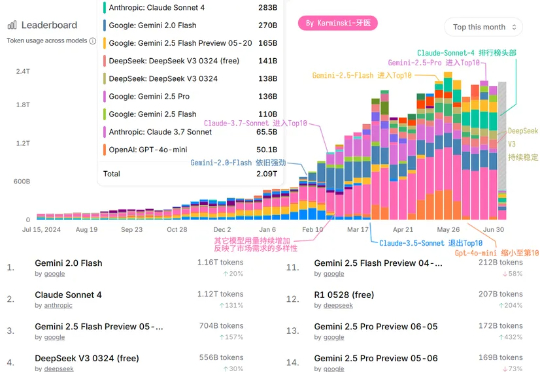
2025 年已经过半, 文本生成大模型是否已经进入下半场了? OpenAI 完全不重视 API 市场? Grok3 根本没人用? 「大模型战」未来的走向如何?
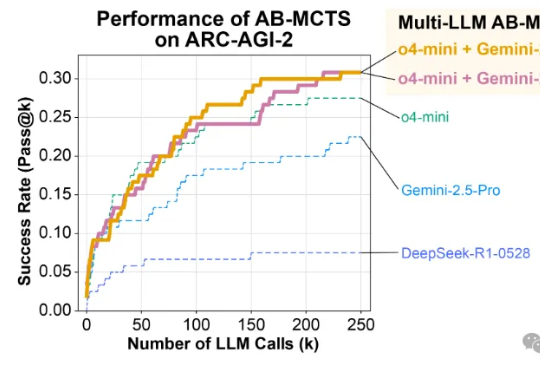
ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……

NCAL是一种新的个性化学习方法,它通过优化文本嵌入的分布来解决教育数据中常见的长尾分布问题,从而提高模型对少数类别的处理能力。
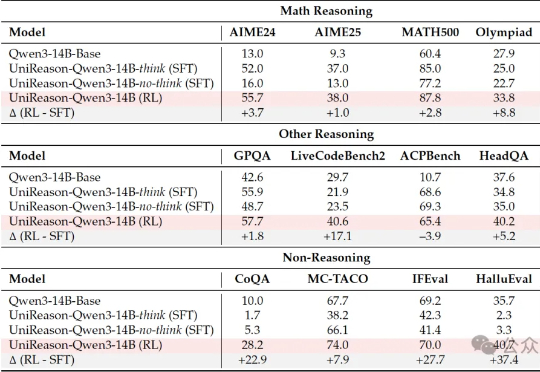
学好数理化,走遍天下都不怕! 这一点这在大语言模型身上也不例外。
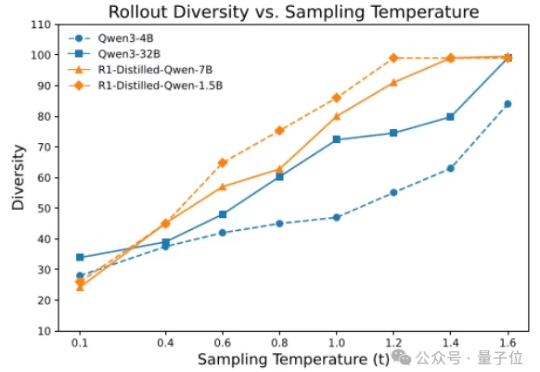
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
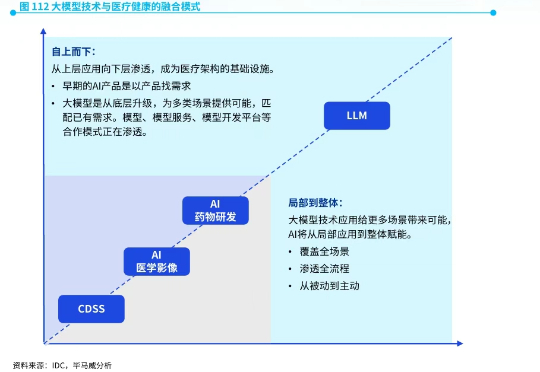
近日,全球四大会计师事务所之一毕马威中国发布了《首届健康科技50》报告。

2025年,全球具身智能赛道爆火,VLA模型成为了绝对的C位。从美国RT-2的开创性突破,到中国最新FiS-VLA「快慢双系统」,VLA正以光速硬核进化。