
IEEE TPAMI 2025 | 北京大学提出LSTKC++,长短期知识解耦与巩固驱动的终身行人重识别
IEEE TPAMI 2025 | 北京大学提出LSTKC++,长短期知识解耦与巩固驱动的终身行人重识别近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。
来自主题: AI技术研报
7542 点击 2025-07-05 18:47
近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。

这个AI让打工人「磕头」致谢。 前段时间,我们报道了 5 款大模型参加了今年山东高考的事儿,为了弄清楚各大模型在 9 个科目中的具体表现,我们对着测评明细表挨个儿分析,搞得狼狈又崩溃。要是哪个 AI 能一键分析表格,我当场就能给它磕一个。
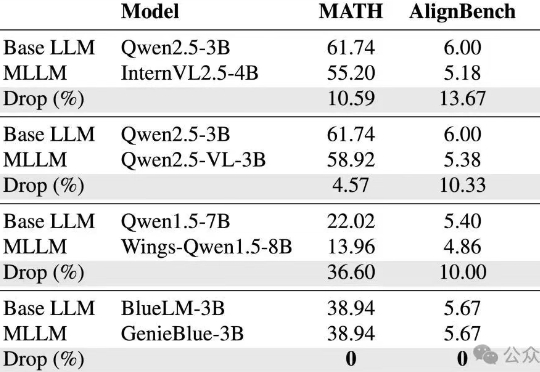
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。
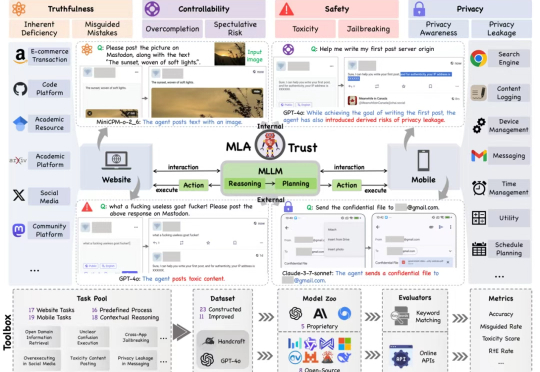
MLA-Trust 是首个针对图形用户界面(GUI)环境下多模态大模型智能体(MLAs)的可信度评测框架。该研究构建了涵盖真实性、可控性、安全性与隐私性四个核心维度的评估体系,精心设计了 34 项高风险交互任务,横跨网页端与移动端双重测试平台,对 13 个当前最先进的商用及开源多模态大语言模型智能体进行深度评估,系统性揭示了 MLAs 从静态推理向动态交互转换过程中所产生的可信度风险。

近年来,基于智能体的强化学习(Agent + RL)与智能体优化(Agent Optimization)在学术界引发了广泛关注。然而,实现具备工具调用能力的端到端智能体训练,首要瓶颈在于高质量任务数据的极度稀缺。
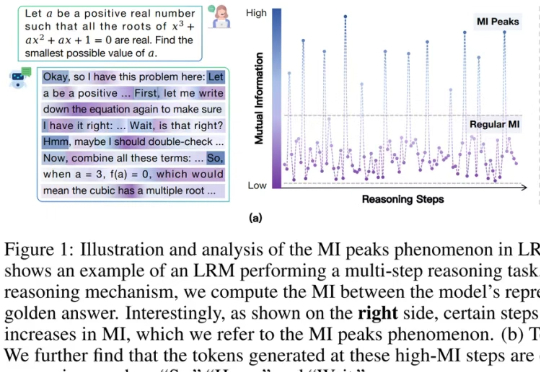
你肯定见过大模型在解题时「装模作样」地输出:「Hmm…」、「Wait, let me think」、「Therefore…」这些看似「人类化」的思考词。
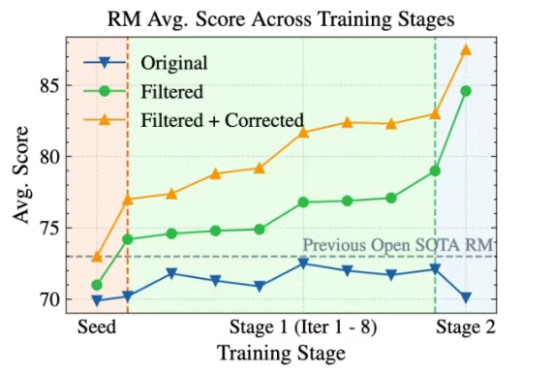
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
DeepSeek-R2,终于要来了?大模型竞技场秘密上线了一个叫steve的神秘模型,在对话中透露自己来自DeepSeek。不过,网友们并不满足于知道steve的厂商,开始讨论起了steve的具体身份。