近日,北京大学王选计算机研究所周嘉欢团队在人工智能重要国际期刊 IEEE TPAMI 发布了一项最新的研究成果:LSTKC++ 。
该框架引入了长短期知识解耦与动态纠正及融合机制,有效保障了模型在终身学习过程中对新知识的学习和对历史知识的记忆。目前该研究已被 IEEE TPAMI 接收,相关代码已开源。

- 论文标题:Long Short-Term Knowledge Decomposition and Consolidation for Lifelong Person Re-Identification
- 论文链接:https://ieeexplore.ieee.org/abstract/document/11010188/
- 代码链接:https://github.com/zhoujiahuan1991/LSTKC-Plus-Plus
- 接收期刊:T-PAMI(CCF A 类/中科院一区 Top)
- 单位:北京大学王选计算机研究所,华中科技大学人工智能与自动化学院
行人重识别(Person Re-Identification, ReID)技术的目标是在跨摄像头、跨场景等条件下,根据外观信息准确识别行人身份,并在多摄像头监控、智能交通、公共安全与大规模视频检索等应用中具有重要作用。
在实际应用中,行人数据分布常因地点、设备和时间等因素的变化而发生改变,使得新数据和训练数据呈现域差异,导致传统的「单次训练、静态推理」ReID 范式难以适应测试数据的长期动态变化。
这催生了一个更具挑战性的新任务——终身行人重识别(Lifelong Person Re-ID, LReID)。该任务要求模型能够利用新增域的数据进行训练,在学习新域数据知识的同时,保持旧域数据的识别能力。
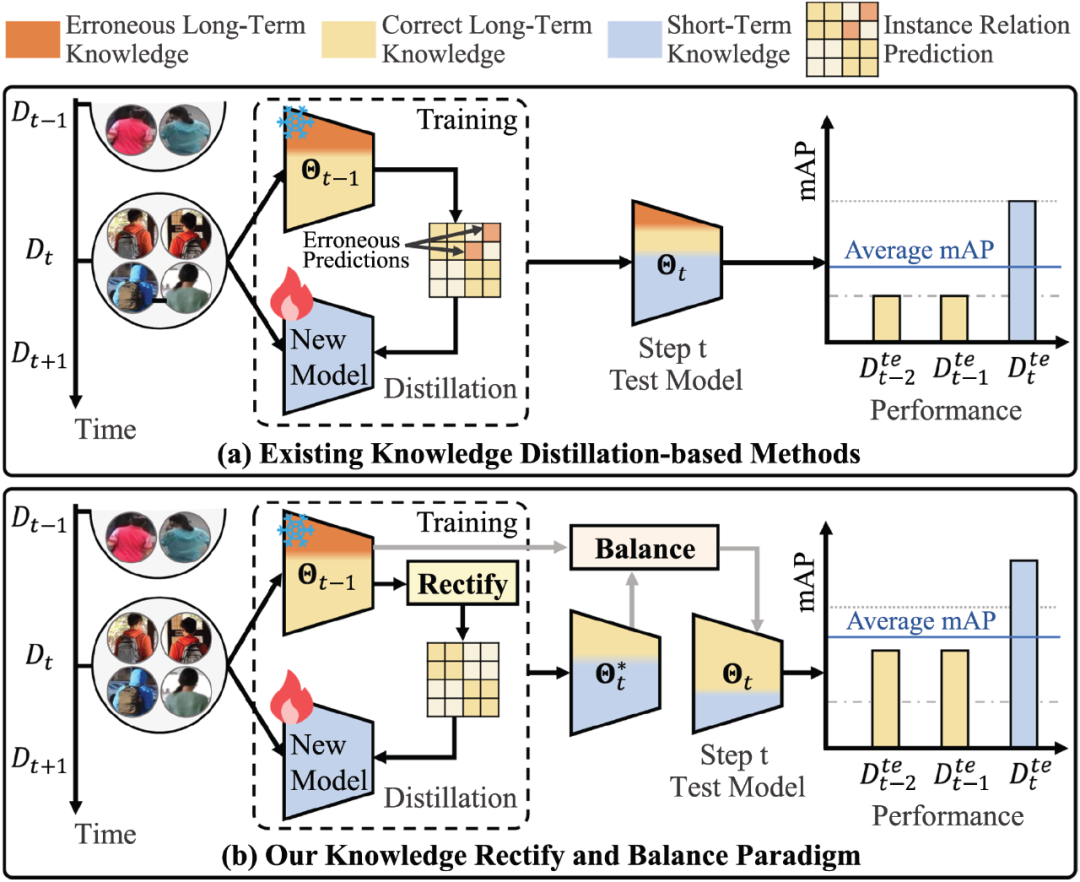
图 1 研究动机
LReID 的核心挑战是灾难性遗忘问题,即模型在学习新域知识后,对旧域数据的处理性能发生退化。为克服该问题,多数方法采用知识蒸馏策略将旧模型的知识迁移到新模型。然而,这些方法存在两个关键隐患:
- 错误知识迁移:由于数据偏差等因素,旧模型中不可避免地包含一些错误知识。在知识蒸馏过程中,不仅会引发错误知识的累积,还会对新知识的学习产生干扰,造成模型的学习能力受限;
- 知识损失:新旧域之间的分布差异导致部分旧知识无法被新数据激活,使得这些知识无法通过知识蒸馏有效地迁移到新模型中。
为破解上述难题,北京大学王选计算机研究所团队在 T-PAMI 2025 上提出了 LSTKC++ 框架。该框架引入了长短期知识解耦与动态纠正及融合机制,在有效保障新知识学习的同时,增强了旧知识的保留能力。
一、基础框架:LSTKC 长短期知识纠正与巩固
LSTKC 是作者团队在 AAAI 2024 上提出的终身行人重识别框架。LSTKC 引入了「短期-长期模型协同融合」的思想,将终身学习所涉及的模型划分为短期模型和长期模型。前者指利用特定域数据训练得到的模型,后者指积累了所有历史域知识的模型。
在新域数据训练时,LSTKC 引入一个基于知识纠正的短期知识迁移模块(Rectification-based Short-Term Knowledge Transfer, R-STKT)。R-STKT 从长期模型中提取判别性特征,并基于新数据的标注信息识别并纠正其中的错误特征,进而利用知识蒸馏策略将校正后的正确知识迁移到新模型中。
在新域数据训练结束后,LSTKC 引入了基于知识评估的长期知识巩固模块(Estimation-based Long-Term Knowledge Consolidation, E-LTKC),根据长期模型和短期模型生成的特征,估计长期知识与短期知识之间的差异,进而实现长短期知识的自适应融合,实现了新旧知识的权衡。
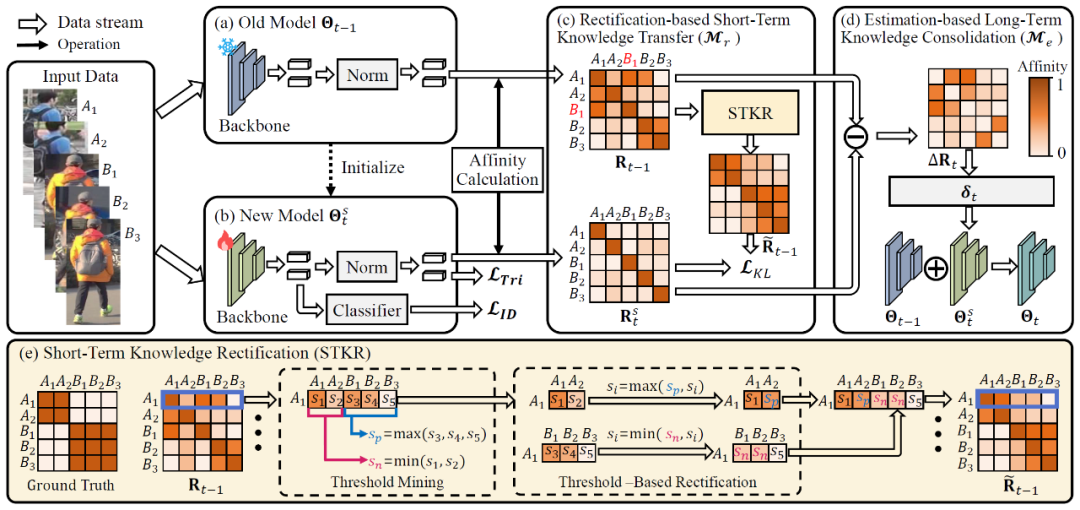
图 2 LSTKC 模型
二、升级框架:LSTKC++ 长短期知识解耦与巩固
尽管 LSTKC 中基于知识差异的长短期知识融合策略在一定程度上促进了新旧知识权衡,但是由于模型间的知识差异无法直接反映融合模型的实际性能,导致 LSTKC 的模型融合策略难以实现新旧知识的最优权衡。
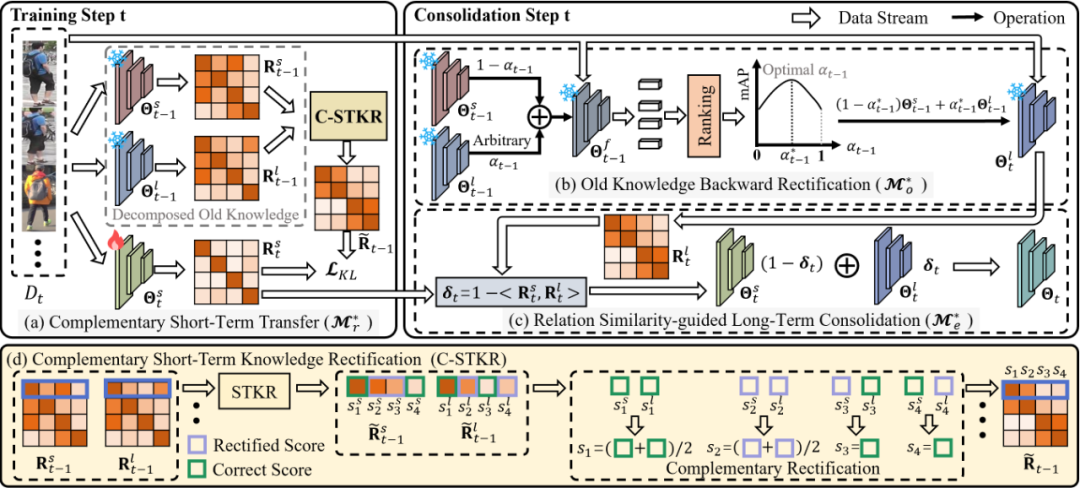
图 3 LSTKC++ 框架
为解决上述问题,作者在 T-PAMI 版本提出了 LSTKC++,从三个方面进行了方法升级:



三、实验分析
数据集与实验设置
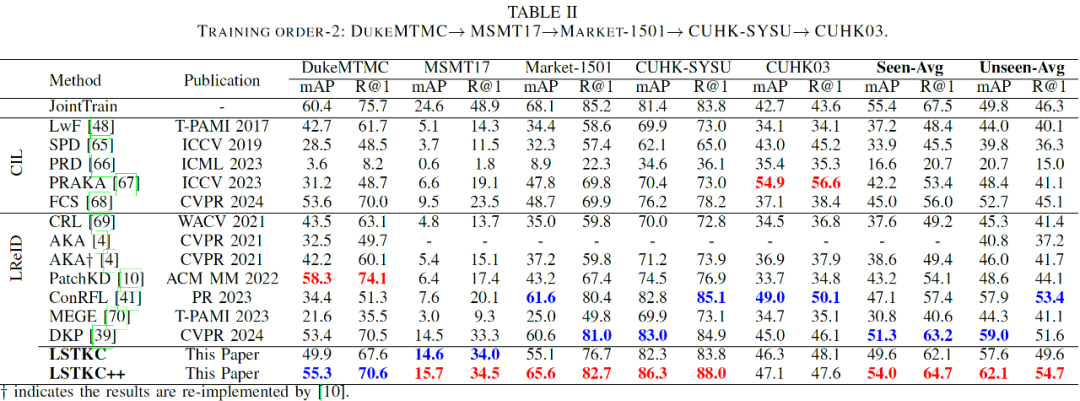
论文的实验采用两个典型的训练域顺序(Order-1 与 Order-2),包含五个广泛使用的行人重识别数据集(Market1501、DukeMTMC-ReID、CUHK03、MSMT17、CUHK-SYSU)作为训练域。分别评估模型在已学习域(Seen Domains)上的知识巩固能力和在未知域(Unseen Domains)上的泛化能力。评测指标采用行人 ReID 任务的标准指标:平均精度均值(mAP)和 Rank-1 准确率(R@1)。
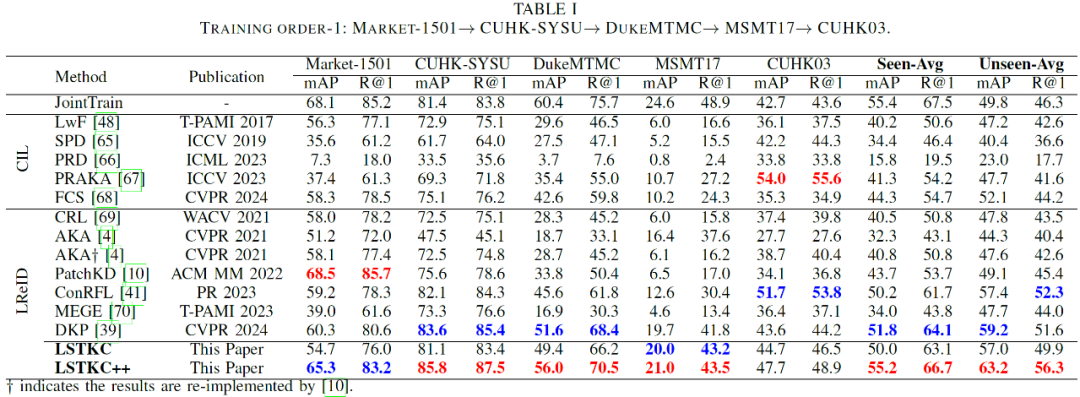
实验结果
- 综合性能分析: 在两种不同的域顺序设定下,LSTKC++ 的已知域平均性能(Seen-Avg mAP 和 Seen-Avg R@1)相比于 CVPR 2024 方法 DKP 提升 1.5%-3.4%。同时,LSTKC++ 在未知域的整体泛化性能(Unseen-Avg mAP 和 Unseen-Avg R@1)上相比于现有方法提升 1.3%-4%。
- 子域性能分析: 在不同的域顺序设定中,虽然 LSTKC++ 在第一个和最后一个域的性能并非最优,但是其在中间三个域的性能均显著优于现有方法。这是因为部分现有方法对模型施加较强的抗遗忘约束,因而有效保持了初始域的性能,但其对新知识的学习能力大幅受限。其次,部分方法则采用较弱的抗遗忘约束,增强了模型对新知识的学习能力,但其对历史域性能的保持能力受限。与上述方法相比,LSTKC++ 综合考虑了知识遗忘和学习的自适应平衡,因而在中间域呈现明显的性能优势,并在不同域的整体性能上实现稳定提升。
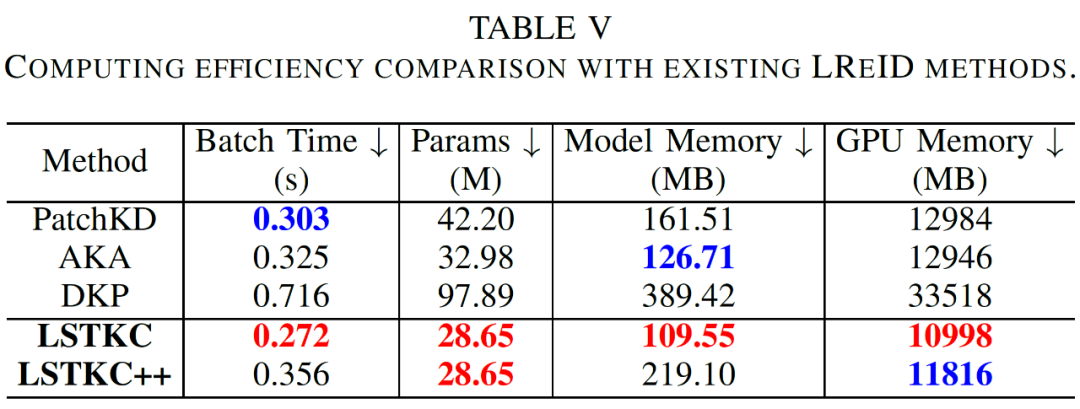
- 计算与存储开销分析: 现有方法(如 PatchKD、AKA、DKP)通常通过引入额外的可学习模块来提升抗遗忘性能,这些模块往往会增加额外的训练时间、模型参数量、存储空间占用和 GPU 显存消耗。与之相比,LSTKC 和 LSTKC++ 仅在特征提取器和身份分类器中包含可学习参数,因此在模型参数量(Params)上具有明显优势。其次,LSTKC 在训练时间(Batch Time)、模型存储(Model Memory)和 GPU 显存消耗(GPU Memory)方面均最为高效。尽管 LSTKC++ 引入了一个额外的旧模型,但由于该旧模型被冻结且不参与梯度计算,其带来的额外开销仅为约 30% 的训练时间和约 818MB(占总显存的~7.4%)的 GPU 显存。总体而言,与最新的 CVPR 2024 方法 DKP 相比,LSTKC++ 在综合性能(TABLE I 和 TABLE II)以及计算和存储效率方面均展现出明显优势。
四、总结与展望
技术创新
本项被 T-PAMI 2025 接收的工作聚焦于终身行人重识别(LReID)任务,面向新知识学习和历史知识遗忘的挑战,提出了以下创新性设计:
- 解耦式知识记忆体系: 提出将终身学习中的知识解耦为长期知识和短期知识,通过长短期知识的针对性处理保障短期新知识学习和促进长期历史知识与短期新知识间的平衡;
- 语义级知识纠错机制: 将知识筛选与纠正机制引入基于知识蒸馏的持续学习,有效克服错误历史知识对新知识学习的干扰;
- 长短期互补知识提炼: 挖掘并融合长短期模型间的互补知识,提升知识蒸馏过程中知识表达的鲁棒性,提升历史知识在新知识学习中的引导作用。
- 遗忘-学习主动权衡: 摒弃固定抗遗忘损失的策略,提出主动搜索最优的新旧知识权衡参数的方法。
应用价值
LSTKC++ 所提出的终身学习机制具备良好的实用性和推广潜力,特别适用于以下典型场景:
- 适应动态开放环境,构建「终身进化」的识别系统。 在实际应用中,摄像头部署环境常常发生变化,例如视角变换、光照变化、图像分辨率波动等,传统静态训练的模型难以持续适应。LSTKC++ 具备长期知识保持与新知识快速整合能力,可持续应对环境迁移,适用于智慧城市、边缘计算终端、无人安防等场景,助力构建「可持续演进」的识别系统。
- 满足隐私保护需求,避免历史样本访问。 在公共安全、交通监控、医疗影像等高度敏感的应用场景中,受限于数据安全与隐私法规,系统通常禁止长期存储历史图像或身份数据。LSTKC++ 在整个持续学习过程中无需访问任何历史样本或缓存数据,具备天然的隐私友好性。
- 高效学习,快速部署。 LSTKC++ 无需保存图像或额外身份原型等,在多轮更新中也不会引入显存负担或冗余参数。同时,相比现有方法(如 DKP),该方法大幅减少了参数规模与显存占用,训练过程高效,可快速完成模型更新,满足资源受限设备上的持续学习需求。
未来展望
LSTKC++ 为无样本持续学习提供了结构化解决方案,未来仍具备多维度的研究与拓展空间:
- 向预训练视觉大模型拓展。 当前终身学习方法多数基于 CNN 架构设计,然而预训练视觉大模型在视觉任务中已展现出强大表达能力。如何将 LSTKC++ 的知识解耦与巩固机制迁移至大模型框架,并结合其先验语义进行持续学习,是一个具有理论深度与实际价值的重要方向。
- 研究多模态感知下的持续学习机制。 现有终身行人重识别研究主要基于可见光图像,尚未充分考虑红外、深度图、文本描述等多模态信息。在传感设备普及的背景下,融合多模态数据以提升持续学习的稳定性、抗干扰能力,将是推动算法实用化的重要路径。
- 推广至通用类别的域增量识别任务。 LSTKC++ 当前聚焦于「跨域+跨身份」的行人检索问题,然而在现实应用中,物品、交通工具、动物等通用类别同样面临动态领域变化现象。将本方法推广至通用类别的域增量学习场景,有望提升大规模视觉系统在开放环境下的适应性与扩展能力。
文章来自微信公众号“机器之心”。


