
AI Agent 距离真正替人「全自动办公」,还有多远?
AI Agent 距离真正替人「全自动办公」,还有多远?近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。
来自主题: AI技术研报
10090 点击 2026-05-25 10:13
 搜索
搜索
近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。

世界模型是个依然模糊和遥远的概念。
当前,测试时扩展范式普遍致力于增加推理长度。然而,已有研究表明,随着推理长度的持续增长,以垂直扩展为核心的计算范式容易陷入探索僵化等问题。因此,从另一维度拓展推理的宽度显得尤为重要。K2.5、Step3-VL 和 LongCat-Flash-Thinking 等模型已在推理宽度方面开展了有益的探索。

前谷歌DeepMind研究员离职并发表长文指出AI行业当前最被低估的瓶颈。他认为,现有的基准测试和安全评估都隐含假设下一代模型只是当前模型的增强版,但如果模型跨入全新能力区间,整个评估基础设施将悄然崩溃。

机器人操作正在从结构化工业场景走向更开放的真实环境。相比完成单个预设动作,真实任务往往包含更长的执行链条、更复杂的物体交互,以及更多不可控的外部扰动。一次抓取没有完全夹稳、目标物体被轻微碰偏、双臂交接时姿态出现偏差,都可能让后续步骤偏离原本计划。
FlashLabs 创始人石一,过去一年就活在这个问题里。他做了一系列在外人看来相当反常识的决定:推翻产品路线、主动缩减团队、放弃短期商业化指标,甚至把公司名字都改了。我们和他聊了聊,在通用模型进化的时代,曾经的垂类 AI 创企到底该怎么活下去。

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来

Anthropic实锤:Claude裸跑模型,9美元全废;但是套上Harness花200美元效果直接起飞。AI效果不好?别再纠结换模型了!OpenAI和Anthropic都在用的Harness工程,一文讲透。
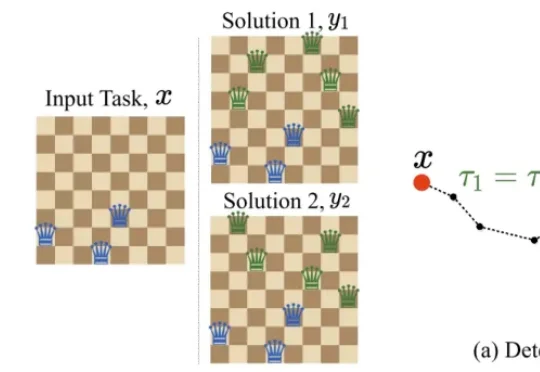
现在,图灵奖得主 Yoshua Bengio 给出了一份全新的并行方案。他们提出了 GRAM(Generative Recursive reAsoning Models,生成式递归推理模型),把确定性的递归潜在推理变成了概率性的多轨迹计算。模型在潜在空间中进行随机递归推理,每一步都可以采样不同的方向,最终形成对解空间的多路径探索。