
Gemini 3.5 Flash 实测:当模型速度进入 4G 时代,Agent 的游戏规则变了 | AI上新
Gemini 3.5 Flash 实测:当模型速度进入 4G 时代,Agent 的游戏规则变了 | AI上新天下武功,唯快不破。
来自主题: AI产品测评
7396 点击 2026-05-26 10:03
 搜索
搜索
天下武功,唯快不破。

一个 8B 参数的大模型,通常需要约 16GB 显存。参数越多,越吃显存,这就是为什么,内存价格一天比一天高。

没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。

多模态训练狠狠烧钱,世界模型公司也都在疯狂融资。

即将结束博士生涯的童晟邦,正站在另一个起点上。
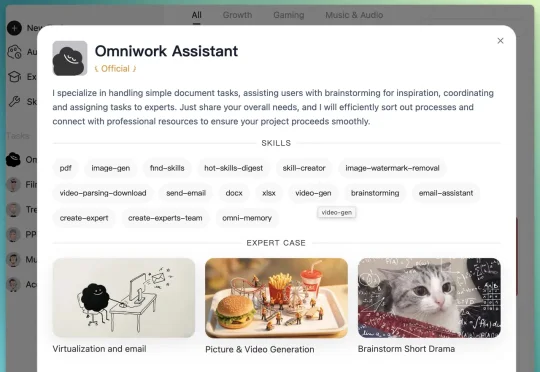
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。

具身智能(Embodied AI)正在快速从实验室走向真实世界。

刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑

刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。
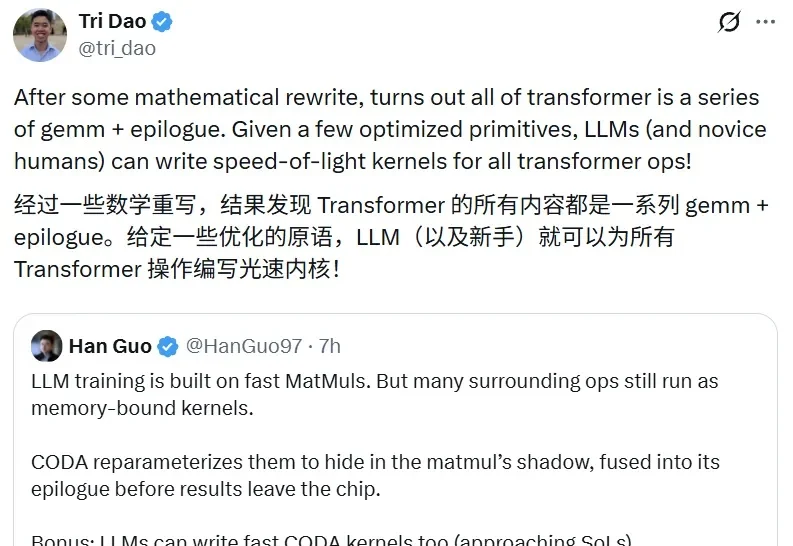
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」