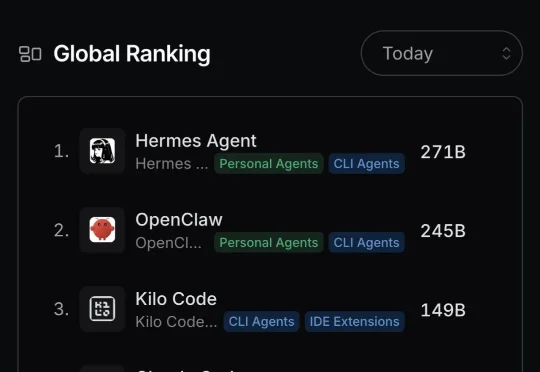
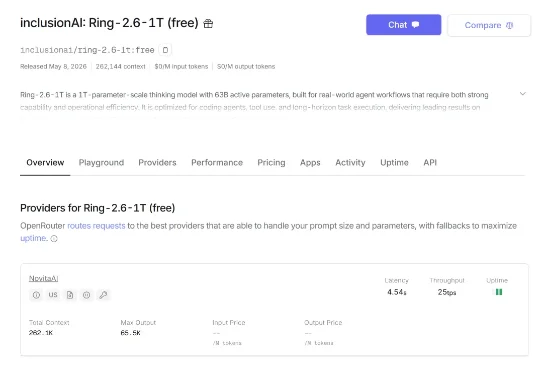
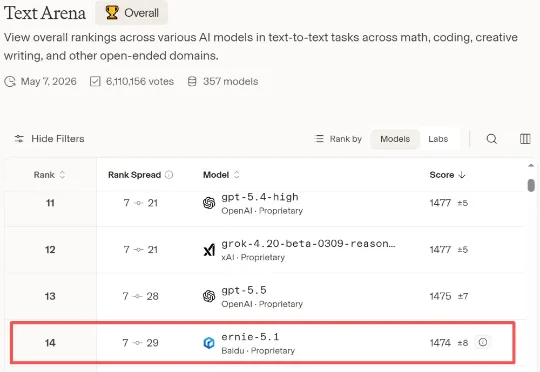
OpenClaw太贵?QuantClaw帮你挑精度,成本砍掉21%,还能提速15%
OpenClaw太贵?QuantClaw帮你挑精度,成本砍掉21%,还能提速15%华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。
来自主题: AI技术研报
8342 点击 2026-05-10 10:42