
英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎
英伟达力荐,小团队两个月开源一款「光速级」智能体推理引擎智能体时代的核心是算力。
来自主题: AI技术研报
8993 点击 2026-05-08 10:23
 搜索
搜索
智能体时代的核心是算力。

不知道大家平时有没有这种经历。
本周四,Google DeepMind 宣布他们又要开始打游戏了。这次目标还是全世界最硬核的那一款:EVE Online。Google DeepMind 此次宣布收购著名科幻在线角色扮演游戏《EVE Online》(星战前夜)开发商的部分股权,并表示将利用该游戏研究「复杂、动态、玩家驱动的系统中的智能」。

Anthropic在四月初发布Mythos,距离现在已经近一个月。行业内对于它的讨论,更多的关注点在于“它有多强”,但我更想聊聊它的“发布方式”。
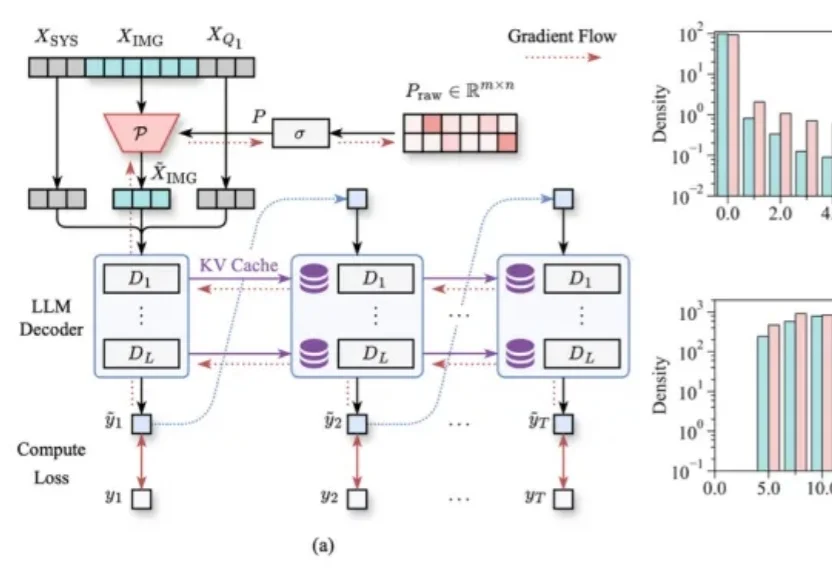
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
那个一句话生成完整物理世界、做出 GitHub 最大开源机器人项目的团队,又出手了。

据华峰资本消息,近日,北京AI大模型独角兽月之暗面(Kimi)完成新一轮约20亿美元(约合人民币136.22亿元)融资,为中国大模型圈目前最大额融资,投后估值突破200亿美元(约合人民币1362.25亿元)。
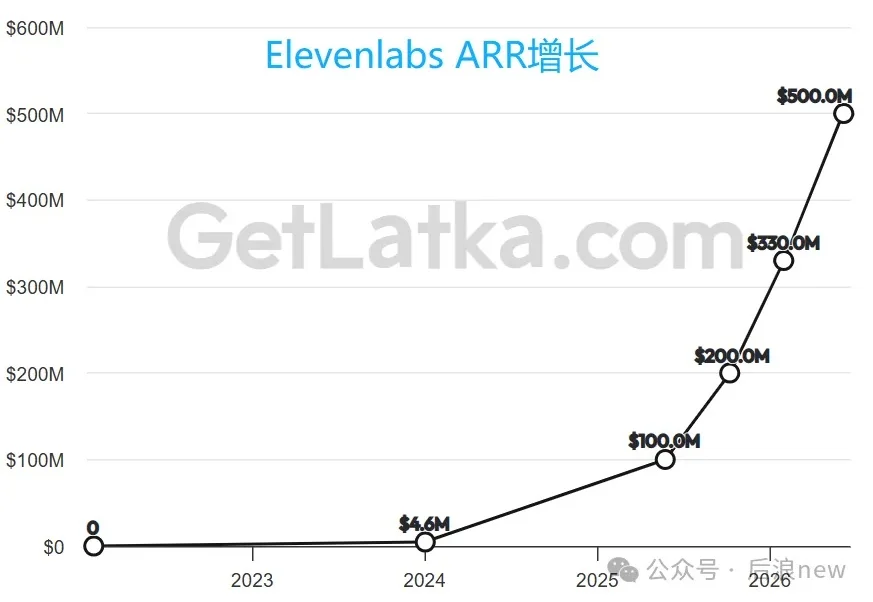
Noiz AI是一家低调务实的音频AI公司,由前Meta、字节员工,及清华、北大、港科大校友联合创立。团队大部分成员是00后,清北校友占据半数左右。

OpenAI,这次又真·Open了一下。

AI圈有个怪现象: 模型越来越强,确实是好事;但随着AI用法越发多样,用起来的门槛却越来越高。