
手把手教你预训练一个小型 LLM|Steel-LLM 的实战经验
手把手教你预训练一个小型 LLM|Steel-LLM 的实战经验随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。
来自主题: AI技术研报
8728 点击 2024-11-22 09:44
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。

人类离电影《黑客帝国》的场景,似乎又近了一步。
5年,5000万个神经网络,这个世界从未被扫描过的角落,我们都能看到了。宝可梦GO团队,竟然抢先实现了李飞飞的「空间智能」?而「Pokémon Go」的玩家可能没想到,自己居然在训练着一个巨大的AI模型。
11月16日,陷入前投资人仲裁风波的主角杨植麟突然出现,并对外发布了一款数学模型。 杨植麟将自己的数学模型k0-math对标OpenAI o1系列,主打深入思考。

在2024年的AI领域,我们正在见证一个有趣的转折。 OpenAI的进展节奏明显放缓,GPT-5迟迟未能问世,“Scaling Law”成了天方夜谭,即便是年初震撼业界的视频生成模型Sora,也未能如期实现“全面开放”的承诺。
2024年世界互联网大会领先科技奖揭晓,文心智能体技术获奖!至此,百度大模型技术已连续两年获得该奖。
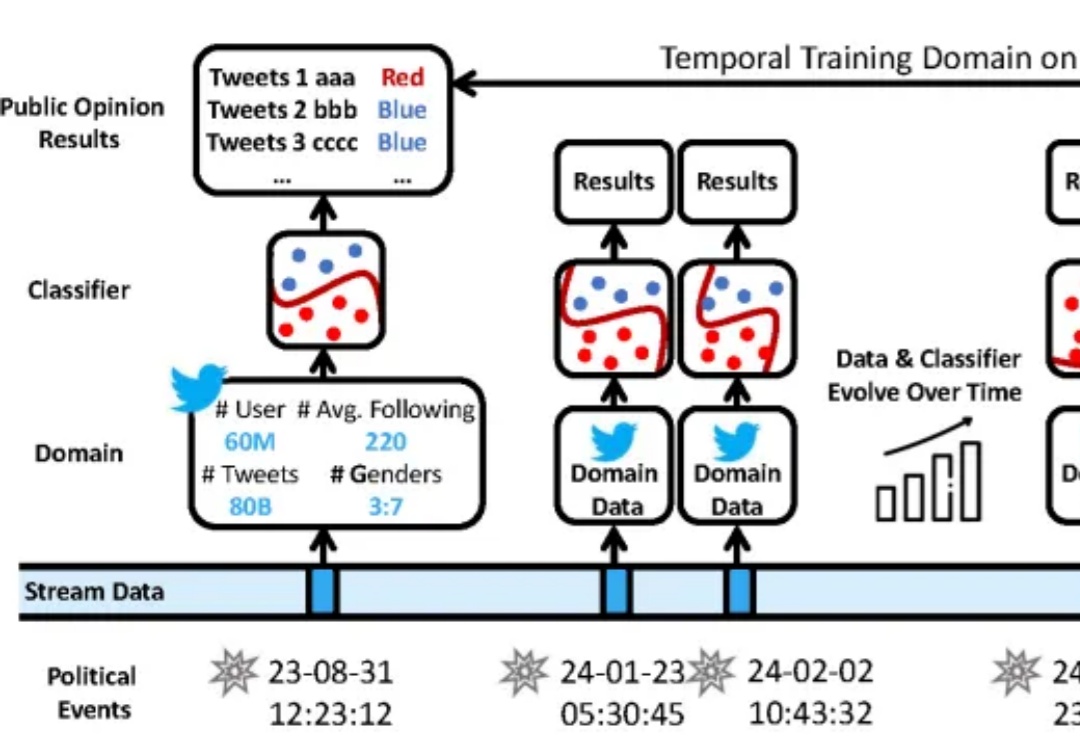
在数据分布持续变化的动态环境中,如何进行连续模型泛化?
在「全球最难LLM评测榜单」上,国产万亿参数模型杀入全球第五,拿下中国第一!国内明星初创阶跃星辰的这个自研模型太过亮眼,甚至引起了外国网友的热议。

近日,来自斯坦福、MIT等机构的研究人员推出了低秩线性转换方法,让传统注意力无缝转移到线性注意力,仅需0.2%的参数更新即可恢复精度,405B大模型两天搞定!
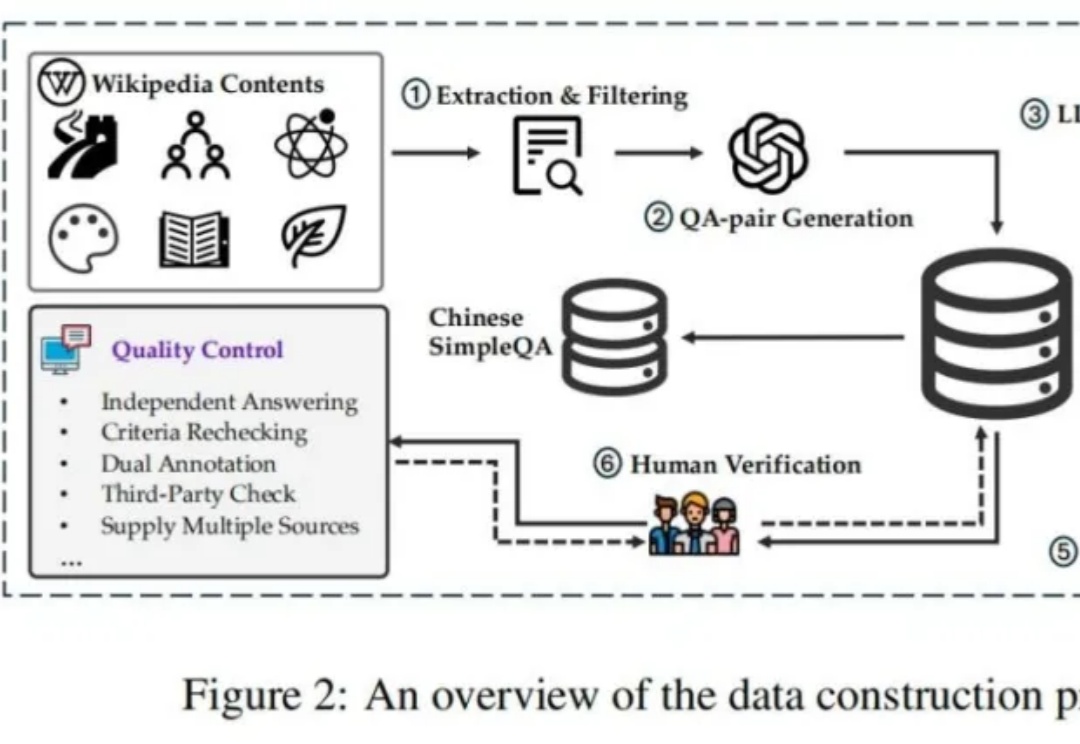
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。