
RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势
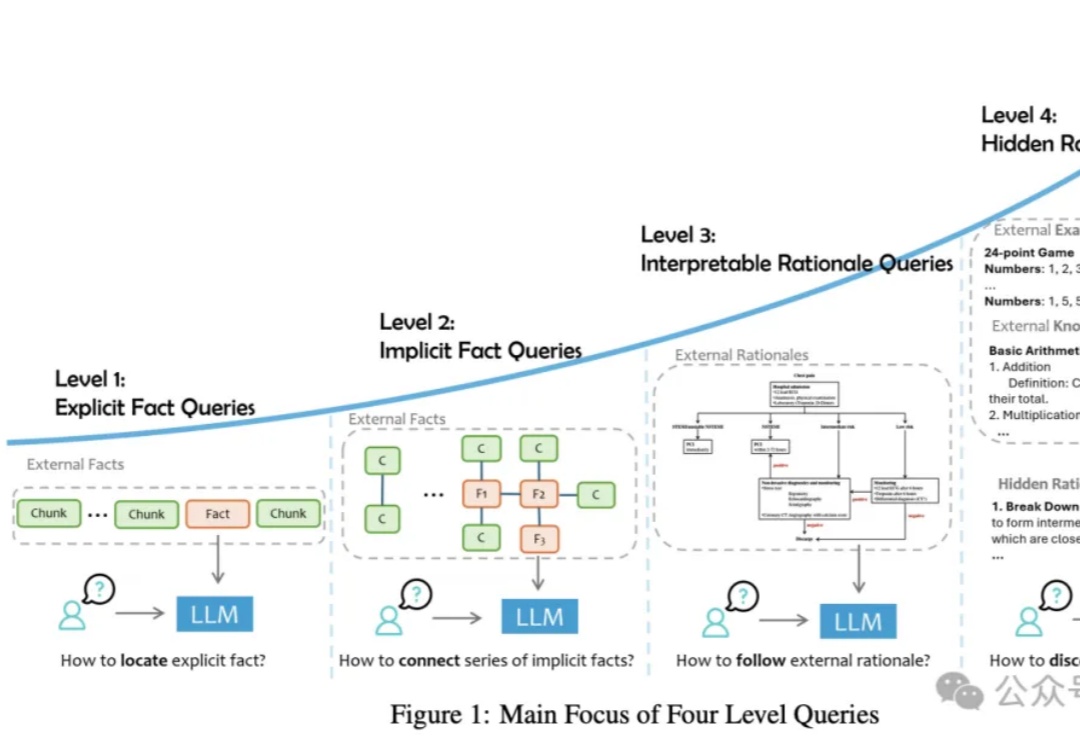
RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
来自主题: AI技术研报
9157 点击 2024-11-21 13:39
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
大模型的执行力从哪里来?
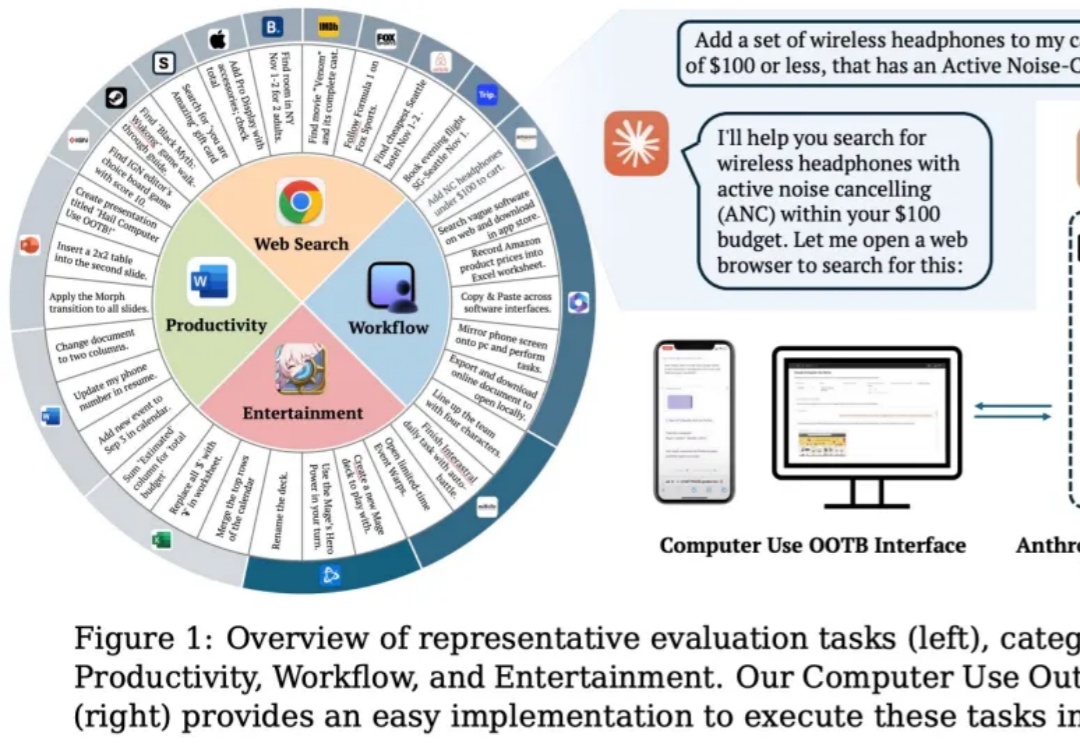
5款预构建Agent、数百万AI协作前景。

企业AI的基本技术架构也已经达成共识:强大的AI模型+图技术加持的RAG+Agent搭建+安全护栏。

在“最难AI榜”,拿下中国第一、全球第五。

今天,DeepSeek 全新研发的推理模型 DeepSeek-R1-Lite 预览版正式上线。所有用户均可登录官方网页 (chat.deepseek.com),一键开启与 R1-Lite 预览版模型的超强推理对话体验。DeepSeek R1 系列模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。

又一个国产版《Her》,就这么水灵灵地来了。
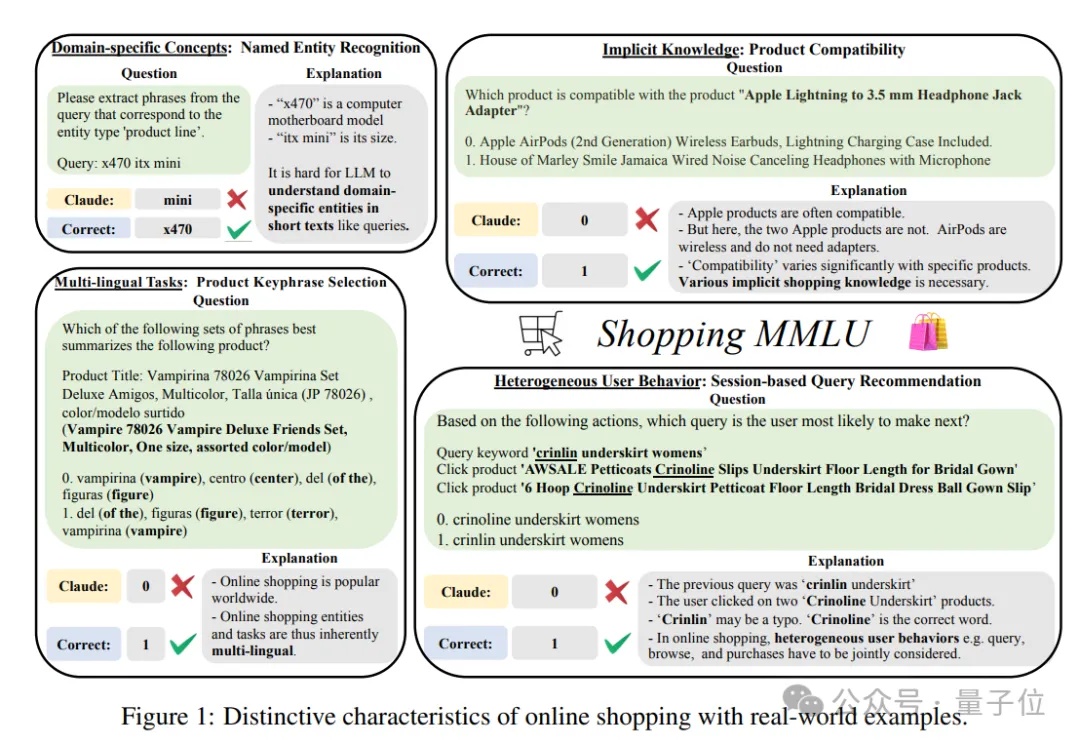
谁是在线购物领域最强大模型?也有评测基准了。
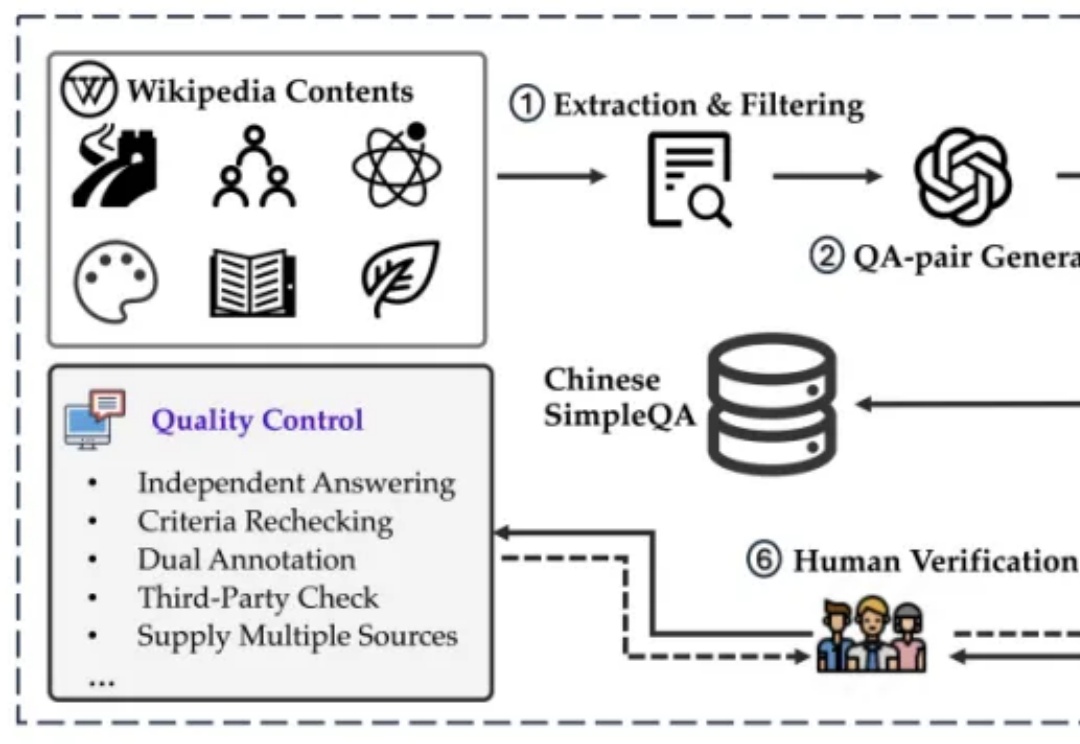
如何解决模型生成幻觉一直是人工智能(AI)领域的一个悬而未解的问题。为了测量语言模型的事实正确性,近期 OpenAI 发布并开源了一个名为 SimpleQA 的评测集。而我们也同样一直在关注模型事实正确性这一领域,目前该领域存在数据过时、评测不准和覆盖不全等问题。例如现在大家广泛使用的知识评测集还是 CommonSenseQA、CMMLU 和 C-Eval 等选择题形式的评测集。
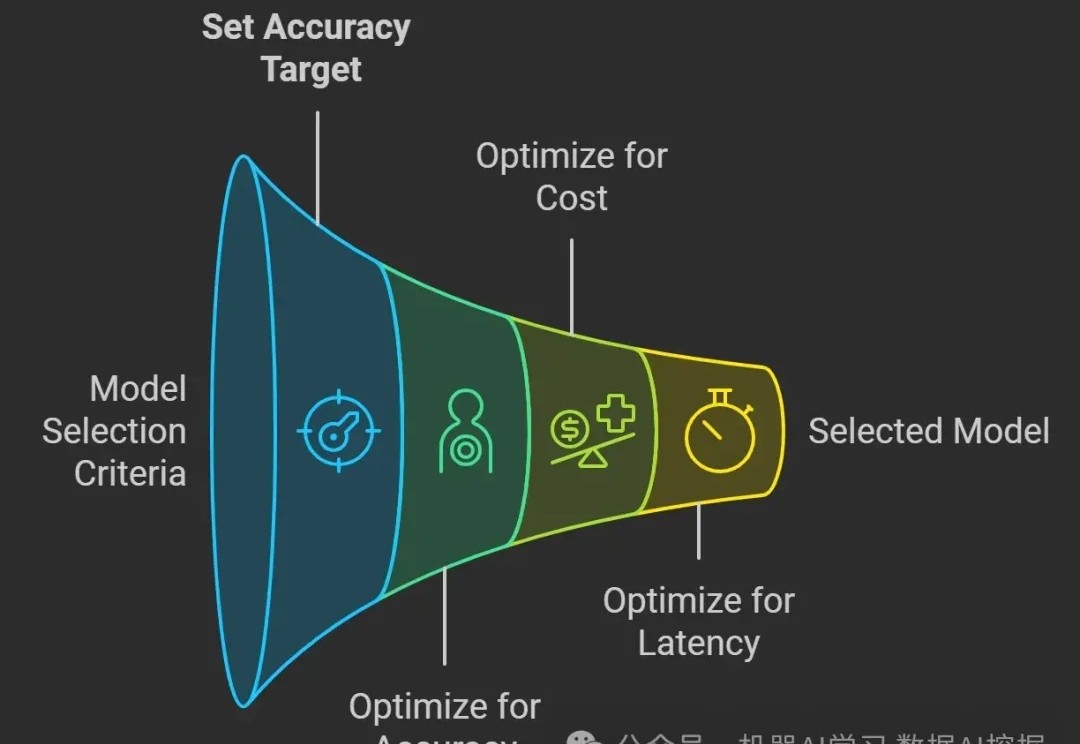
当你开始任何客户项目时,最常见的问题之一是:“我应该使用哪个模型?” 这个问题没有直接的答案,它是一个过程。在本博客中,我们将解释这个过程,这样下次客户问你这个问题时,你可以与他们分享这份文档。