

Ilya预言错了!华人Nature一作给RLHF「判死刑」,全球大模型都不可靠
Ilya预言错了!华人Nature一作给RLHF「判死刑」,全球大模型都不可靠2022年,AI大牛Ilya Sutskever曾预测:「随着时间推移,人类预期和AI实际表现差异可能会缩小」。
来自主题: AI资讯
4706 点击 2024-09-29 16:18
2022年,AI大牛Ilya Sutskever曾预测:「随着时间推移,人类预期和AI实际表现差异可能会缩小」。
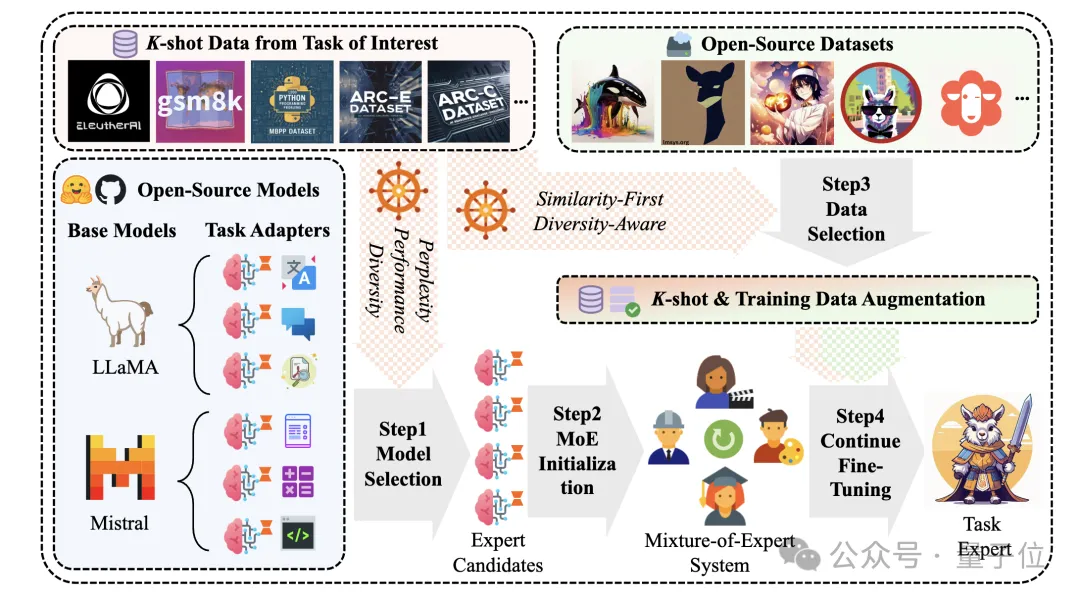
告别传统指令微调,大模型特定任务性能提升有新方法了。 一种新型开源增强知识框架,可以从公开数据中自动提取相关知识,针对性提升任务性能。 与基线和SOTA方法对比,本文方法在各项任务上均取得了更好的性能。
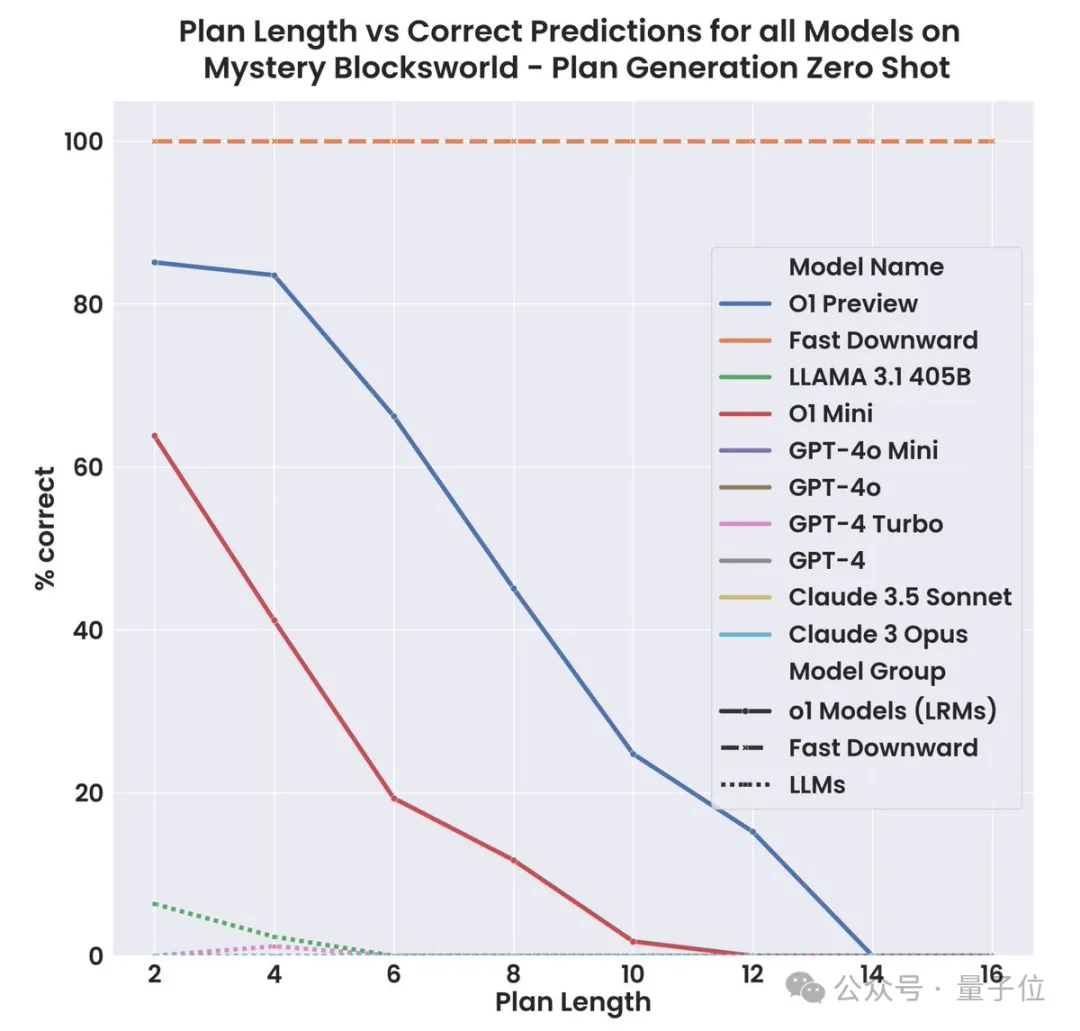
o1-preview终于赢过了mini一次! 亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。

大模型医疗应用还在早期,最大挑战还是在数据的处理上,国内至少还需要两到三年来解决; 创业公司还有机会,只要找到合适的切入点。这个行业只有撑死的,没有饿死的。
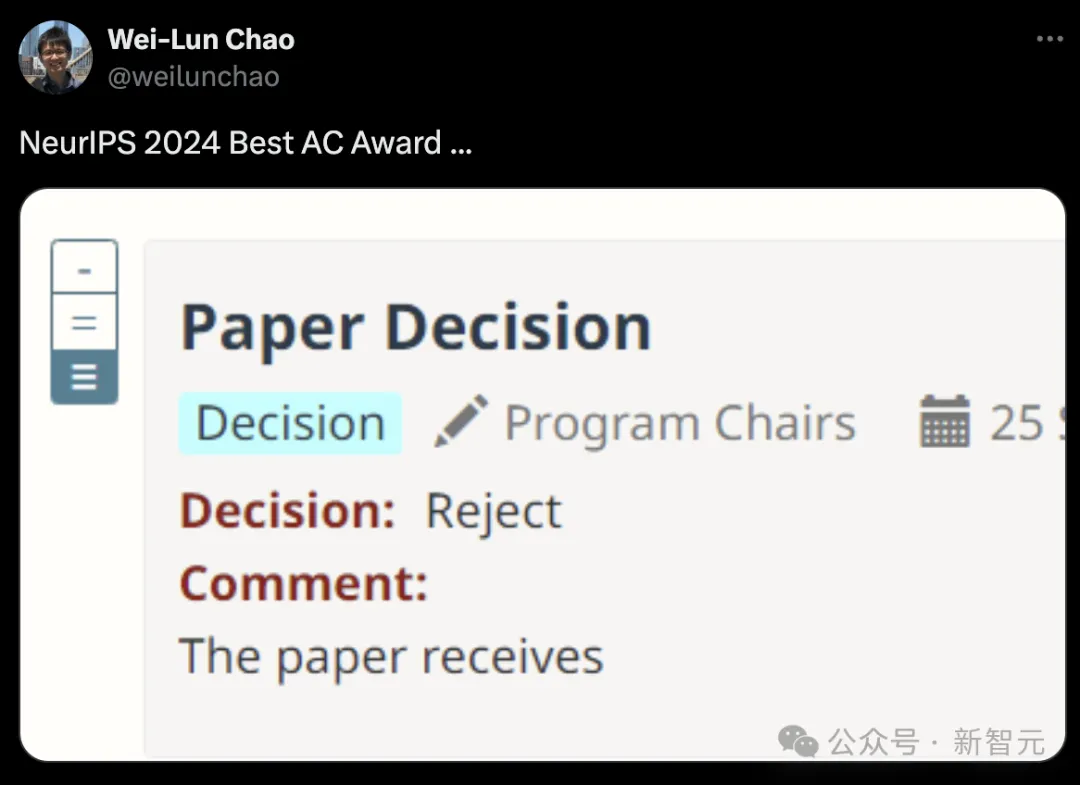
NeurIPS 2024评审结果已经公布了! 收到邮件的小伙伴们,就像在开盲盒一样,纷纷在社交媒体上晒出了自己的成绩单。

视觉数据的种类极其多样,囊括像素级别的图标到数小时的视频。现有的多模态大语言模型(MLLM)通常将视觉输入进行分辨率的标准化或进行动态切分等操作,以便视觉编码器处理。然而,这些方法对多模态理解并不理想,在处理不同长度的视觉输入时效率较低。

Sutton 等研究人员近期在《Nature》上发表的研究《Loss of Plasticity in Deep Continual Learning》揭示了一个重要发现:在持续学习环境中,标准深度学习方法的表现竟不及浅层网络。研究指出,这一现象的主要原因是 "可塑性损失"(Plasticity Loss):深度神经网络在面对非平稳的训练目标持续更新时,会逐渐丧失从新数据中学习的能力。

近日,机器学习研究员、畅销书《Python 机器学习》作者 Sebastian Raschka 又分享了一篇长文,主题为《从头开始构建一个 GPT 风格的 LLM 分类器》。

字节跳动以性价比策略切入市场,掀起价格竞争,但高性能模型仍保持付费门槛。B端市场对豆包视频大模型的接纳度有待观察,其商业变现与用户场景适配性成为主要考验。

要论最近最火的AI视频生成模型,无疑就属字节豆包了。