
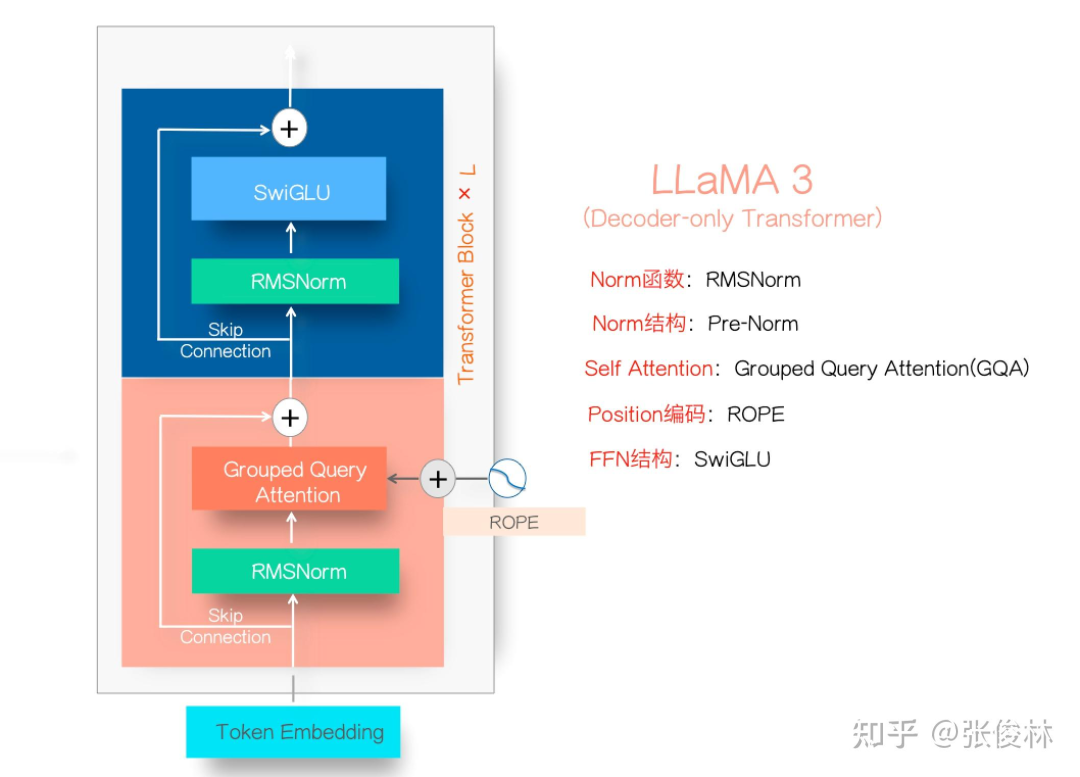
浅谈Llama3.1,从结构、训练过程、影响到数据合成
浅谈Llama3.1,从结构、训练过程、影响到数据合成Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。
来自主题: AI技术研报
12453 点击 2024-08-20 14:39
Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。

作为基础的视觉语言任务,指代表达理解(referring expression comprehension, REC)根据自然语言描述来定位图中被指代的目标。REC 模型通常由三部分组成:视觉编码器、文本编码器和跨模态交互,分别用于提取视觉特征、文本特征和跨模态特征特征交互与增强。

大模型“退烧”?困在“恰饭”难里?

当一家人工智能公司的首席执行官更像是计算机科学家而不是推销员时,我感觉更舒服

“乱世”其实早已到来,只不过这次是公开承认了这个现实。

更适合中国宝宝体质的图生视频大模型。

4秒看完2小时电影,阿里团队新成果正式亮相——
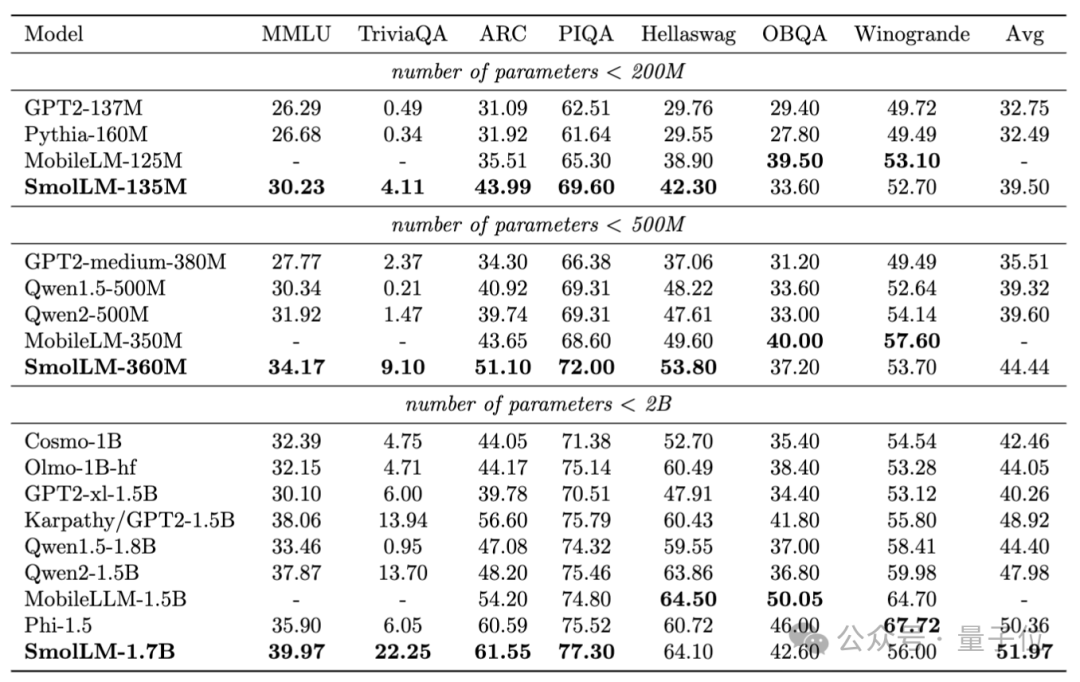
浏览器里直接能跑的SOTA小模型来了,分别在2亿、5亿和20亿级别获胜,抱抱脸出品。

合成数据2.0秘诀曝光了!来自微软的研究人员们提出了智能体框架AgentInstruct,能够自动创建大量、多样化的合成数据。经过合成数据微调后的模型Orca-3,在多项基准上刷新了SOTA。
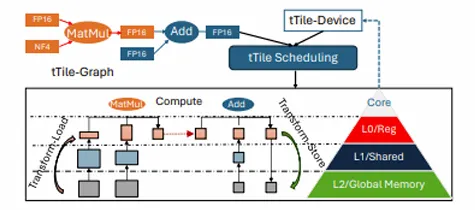
在人工智能领域,模型参数的增多往往意味着性能的提升。但随着模型规模的扩大,其对终端设备的算力与内存需求也日益增加。低比特量化技术,由于可以大幅降低存储和计算成本并提升推理效率,已成为实现大模型在资源受限设备上高效运行的关键技术之一。然而,如果硬件设备不支持低比特量化后的数据模式,那么低比特量化的优势将无法发挥。