挖漏洞何必Mythos,国产智能体早跑通了
挖漏洞何必Mythos,国产智能体早跑通了手握最强大的模型Mythos,Anthropic却把它锁了起来。
来自主题: AI资讯
7756 点击 2026-04-22 16:38
 搜索
搜索
手握最强大的模型Mythos,Anthropic却把它锁了起来。

大模型人才涌入,帮助智驾厂商突破原有技术框架上限。

用AI跑批量任务的人,手里基本都有一个干活的模型,不是最聪明,但要快、要便宜,稳定不出岔子。
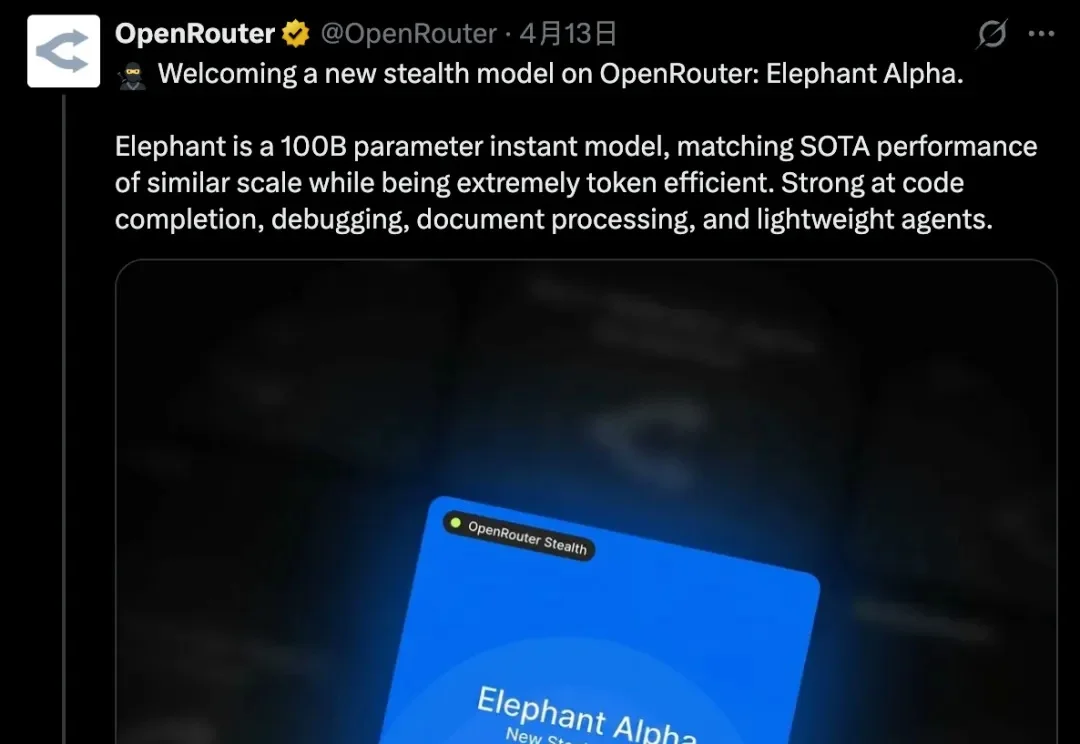
神秘模型Elephant的面纱,终于被揭开了。

2026年3月26日,科创板公布了《宇树科技招股说明书》(申报稿)。拟发行不低于4044.6万股,募集资金约42亿(20亿用于模型研发、11亿用于本体研发4.4亿用于产品开发、6.2亿用于基建)。
4 月的大模型战场,硝烟弥漫。

先说一个很多人没意识到的事实:2026年了,每个主流Agent框架底下的工具调用训练数据,格式全是乱的。
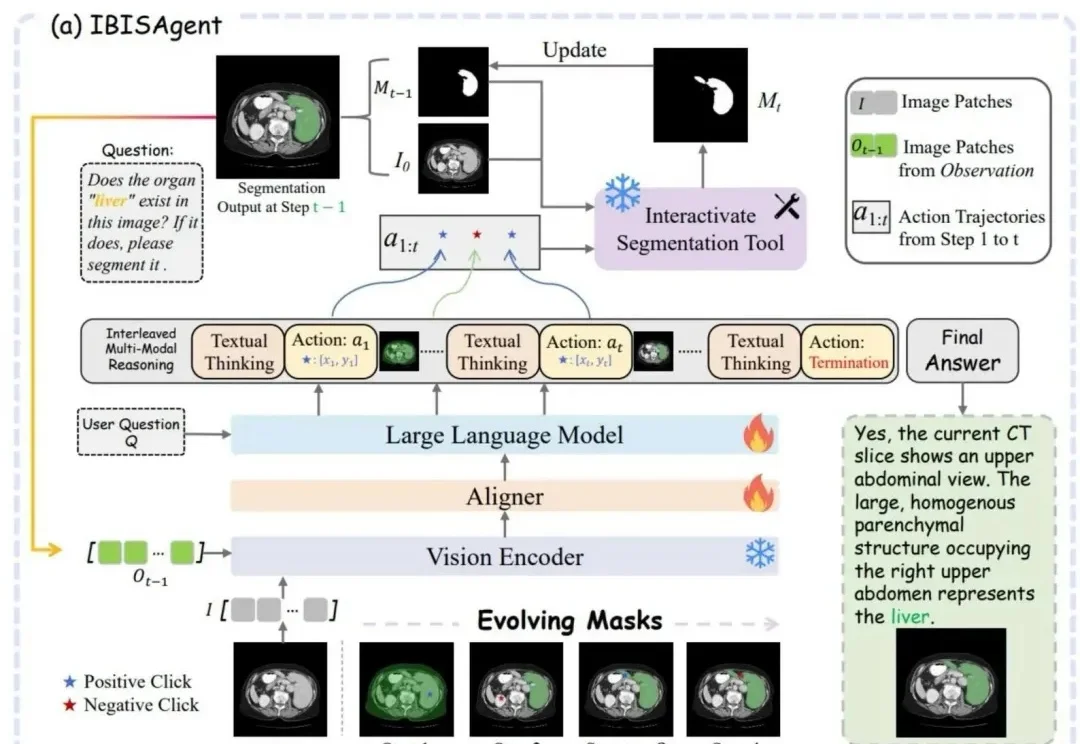
这个生物医学视觉推理框架,被CVPR 2026接收了!

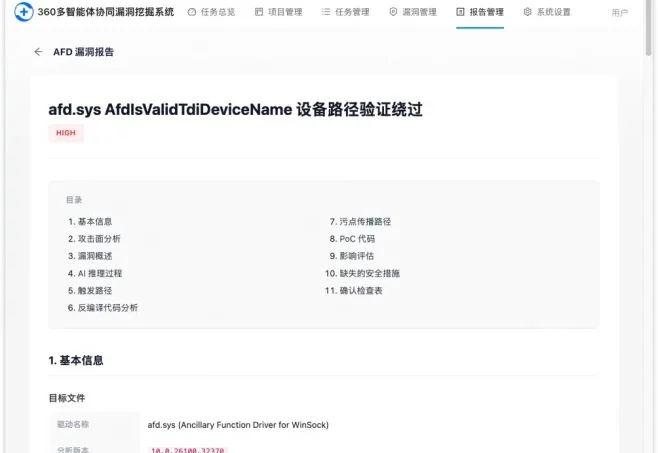
如果你在网络安全圈混,最近一定被“Mythos”刷过屏——Anthropic 搞出了一个能挖 Bug 的 AI 模型,但因为怕被坏人滥用,愣是没敢公开发布。

北京时间凌晨 3 点,直播准时开始,OpenAI 发布了 ChatGPT Images 2.0。据介绍,「ChatGPT Images 2.0 是下一步进化:一个最先进的模型,能够处理复杂的视觉任务,并生成精确、可直接使用的视觉内容。」