
不换模型,性能涨了39%:让AI智能体自己修bug的开源方案来了
不换模型,性能涨了39%:让AI智能体自己修bug的开源方案来了NeoSigma 团队今天开源了一个叫 auto-harness 的系统,核心做的事只有一件:让智能体自己发现自己的 bug,自己修,自己验证。
来自主题: AI技术研报
9112 点击 2026-04-23 10:53
 搜索
搜索
NeoSigma 团队今天开源了一个叫 auto-harness 的系统,核心做的事只有一件:让智能体自己发现自己的 bug,自己修,自己验证。

“Claude 和许多模型在不需要太多诱导的情况下,就会陷入‘有某种东西是我,我感觉非常有意识’的这种状态。”

很少有人能意识到印奇只比杨植麟大4岁。两人都是从AI1.0时代开始创业,那时作为“AI四小龙”代表人物的印奇,名气远比杨植麟大。但到了以大模型为核心的AI2.0时代,印奇反而要追赶比他年轻的杨植麟。

千里科技的AI商业闭环,今天正式加速了

阿里前几天开源的Qwen3.6-35B-A3B,让这次讨论不再只是一次普通的新旧模型对比。它一边要面对谷歌Gemma4-26B-A4B的外部竞争,一边又必须回答一个更麻烦的问题:相较于 Qwen3.5-35B-A3B,它到底是升级,还是修补?更现实的是,很多人现在真正跑着的,其实是Qwen3.5-27B,那么这条新的35B-A3B路线,到底值不值得迁过去。
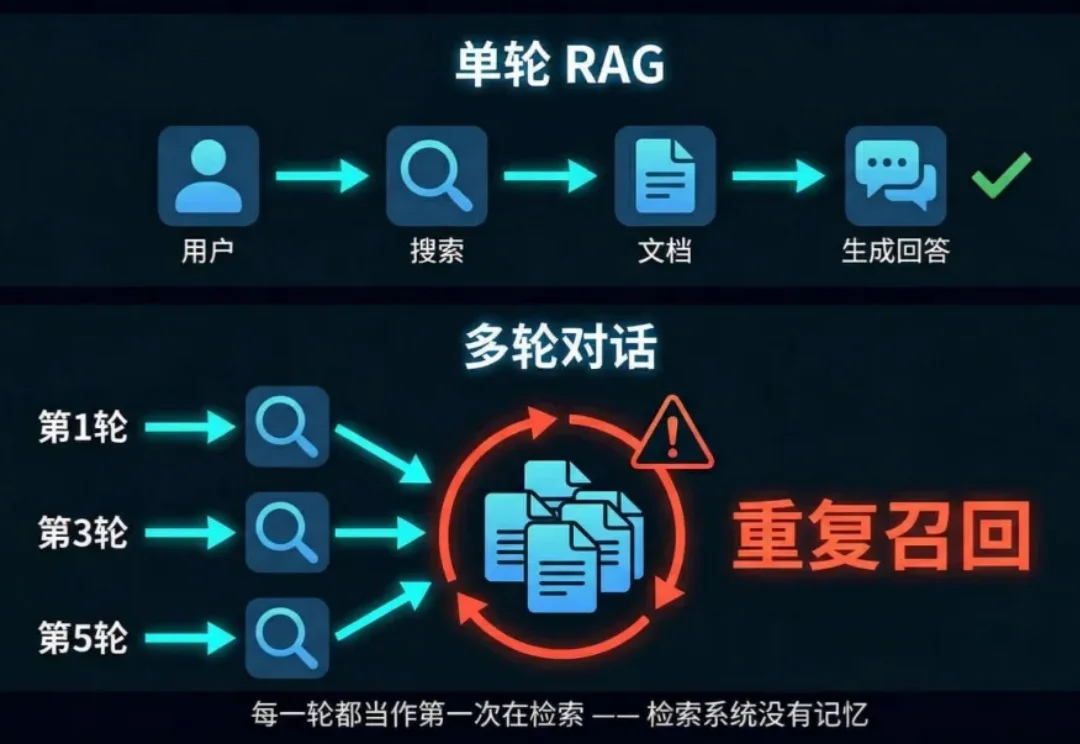
做 RAG 的团队,基本都会在多轮对话上吃过亏。
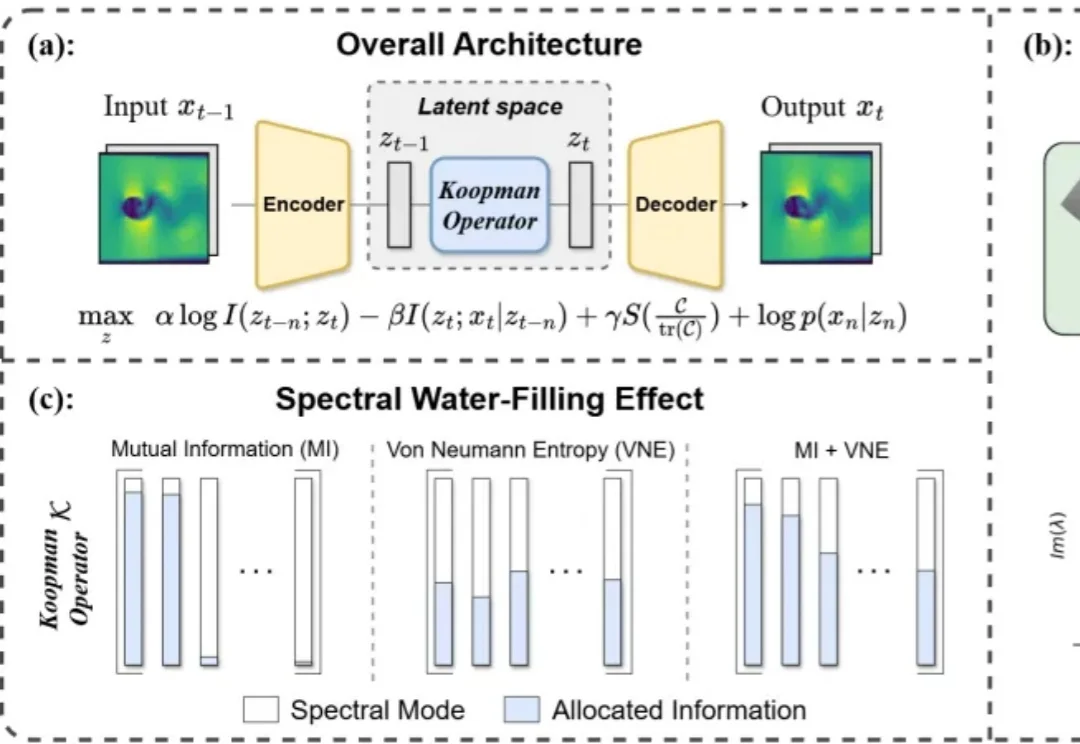
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。

今天,多位开发者在DeepSeek官方交流群和社交媒体上反馈,DeepSeek官方API所调用的模型能力出现了变化,已拥有一百万的上下文窗口,而不是此前的128k,知识截止日期更新为2025年5月,而不是此前的2024年。

就在刚刚,自变量机器人发布了全球首个世界统一模型架构的具身智能基础模型:WALL-B。基于世界统一模型,WALL-B解决了传统VLA架构在模块间数据搬运上的bug点——
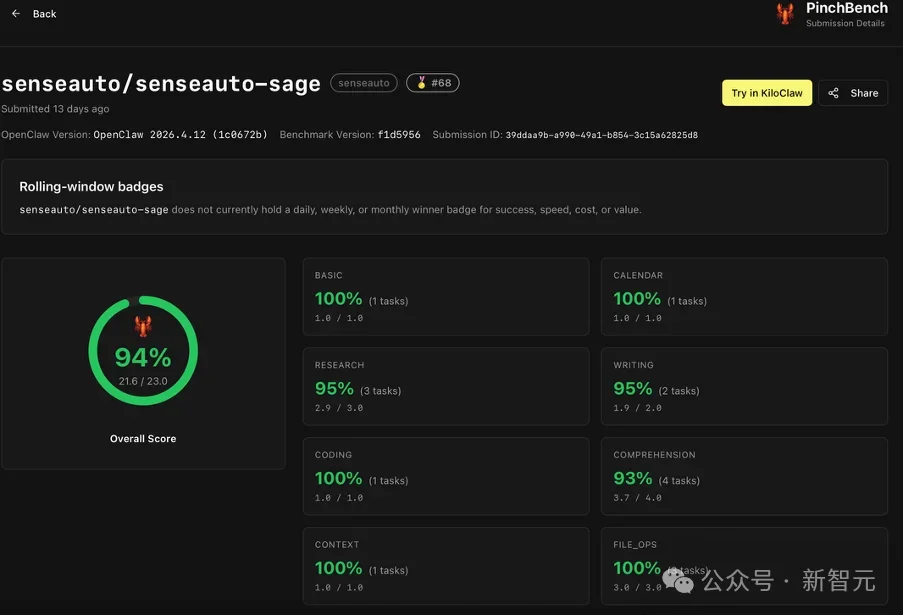
一个3B激活参数的端侧模型,在全球Agent权威评测中,以94%任务完成率,超越了Claude、GPT-5.4、Gemini等国际主流云侧和端侧大模型。商汤绝影Sage来了,它不是「更聪明的语音助手「,而是第一个真正能在车里「办成复杂事「的智能体基座。