
华人团队领衔!OpenAI深夜祭出「首个生命科学大模型」GPT-Rosalind,碾压95%人类专家!
华人团队领衔!OpenAI深夜祭出「首个生命科学大模型」GPT-Rosalind,碾压95%人类专家!就在今天,OpenAI正式宣布推出GPT-Rosalind,一款专为生物学和药物研发打造的垂直领域推理模型!它旨在加速从基础生物学、药物发现到转化医学的整个研究流程,解决新药研发周期长、流程复杂等核心痛点。
来自主题: AI资讯
9663 点击 2026-04-17 13:09
 搜索
搜索
就在今天,OpenAI正式宣布推出GPT-Rosalind,一款专为生物学和药物研发打造的垂直领域推理模型!它旨在加速从基础生物学、药物发现到转化医学的整个研究流程,解决新药研发周期长、流程复杂等核心痛点。

刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7

3B激活参数,视觉能力直逼Claude Sonnet 4.5。

Gemini 终于推出桌面客户端了!除了能做网页端的一切,它的杀手锏是能捕捉屏幕上所有窗口,突破浏览器限制,把一切都装进模型上下文,帮你解读一切。

视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。

最近Hermes agent被讨论得沸沸扬扬的,今天,我们来深度拆解下它是怎么做Skills 闭环系统的。

很多人以为,给Agent装上更多Skill,它就会变得更强。

Agent 的持续学习和自我进化是最近行业内的讨论热点。
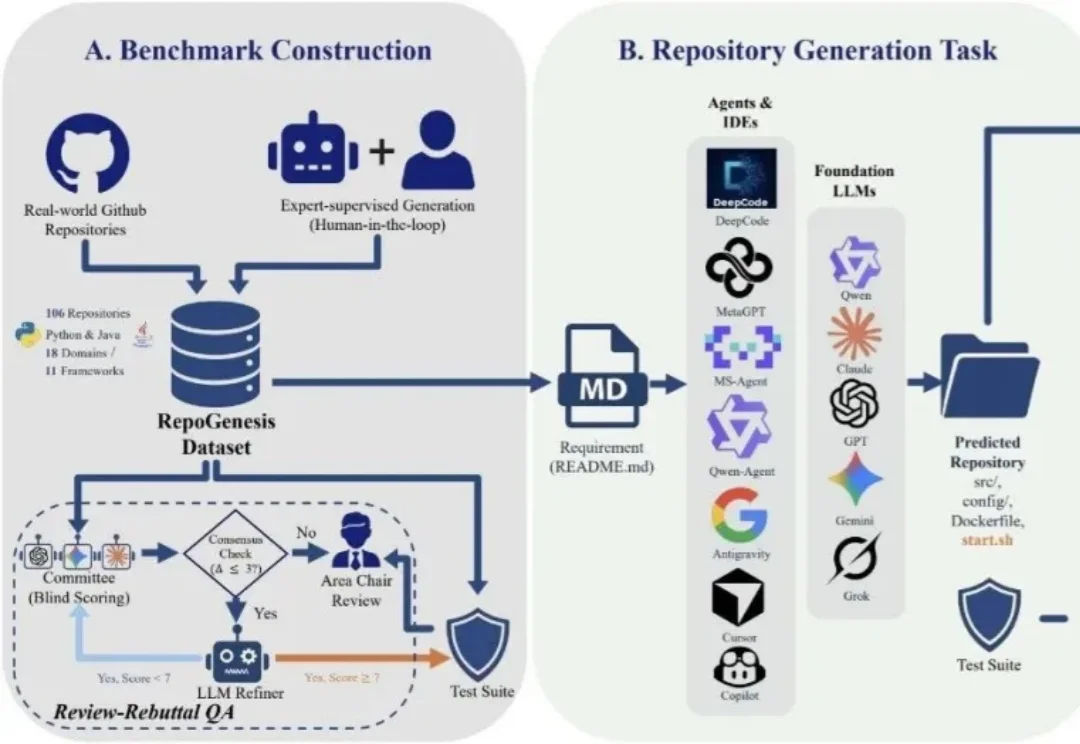
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
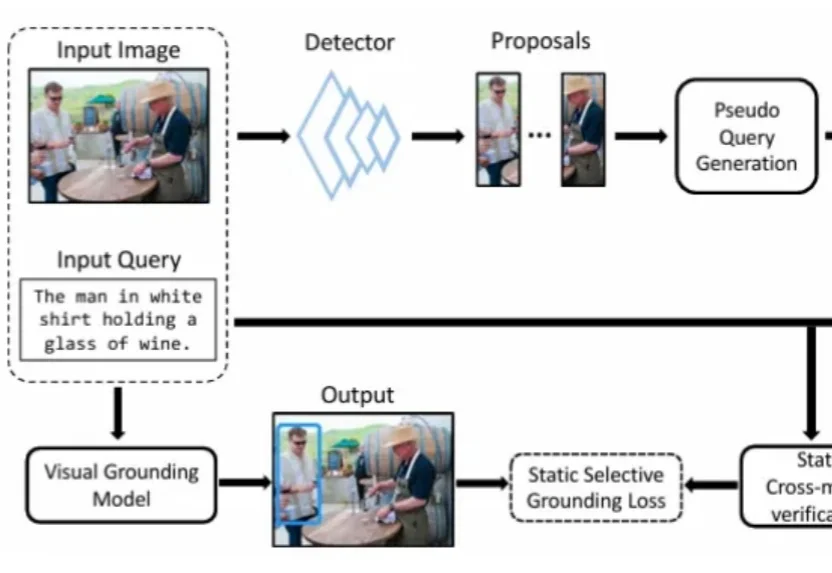
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。