
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
来自主题: AI技术研报
8813 点击 2026-04-17 08:40
 搜索
搜索
AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。

有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
果不其然,最近一周Claude天天崩,就是为了新模型做储备。

过去两年,具身智能最大的瓶颈,其实不是模型。

两眼一睁,Claude又更新了。Anthropic发布新一代旗舰大模型Claude Opus 4.7。该模型在高级软件工程方面相比Opus 4.6有显著提升,尤其在处理最复杂的任务时提升明显;高分辨率图像处理能力大幅提升,是此前Claude模型的3倍以上

这两天,一款名为Elephant(大象)的匿名模型,在OpenRouter上悄然亮相。上线不到48小时,这一模型已经冲到OpenRouter热榜(Trending)第一,目前调用量超过1850亿个token。
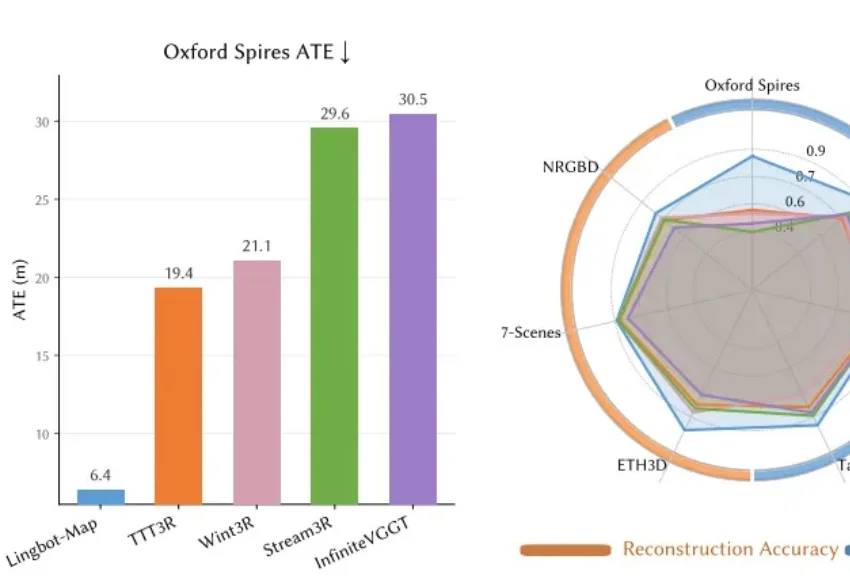
蚂蚁灵波,下了盘大棋。

AI 公司对更多数据的贪婪需求推高了从事该行业不起眼工作的初创公司的销售额:这些公司与律师、博士学位持有者和医生签约 ,由他们对 AI 模型生成的答案进行评分。
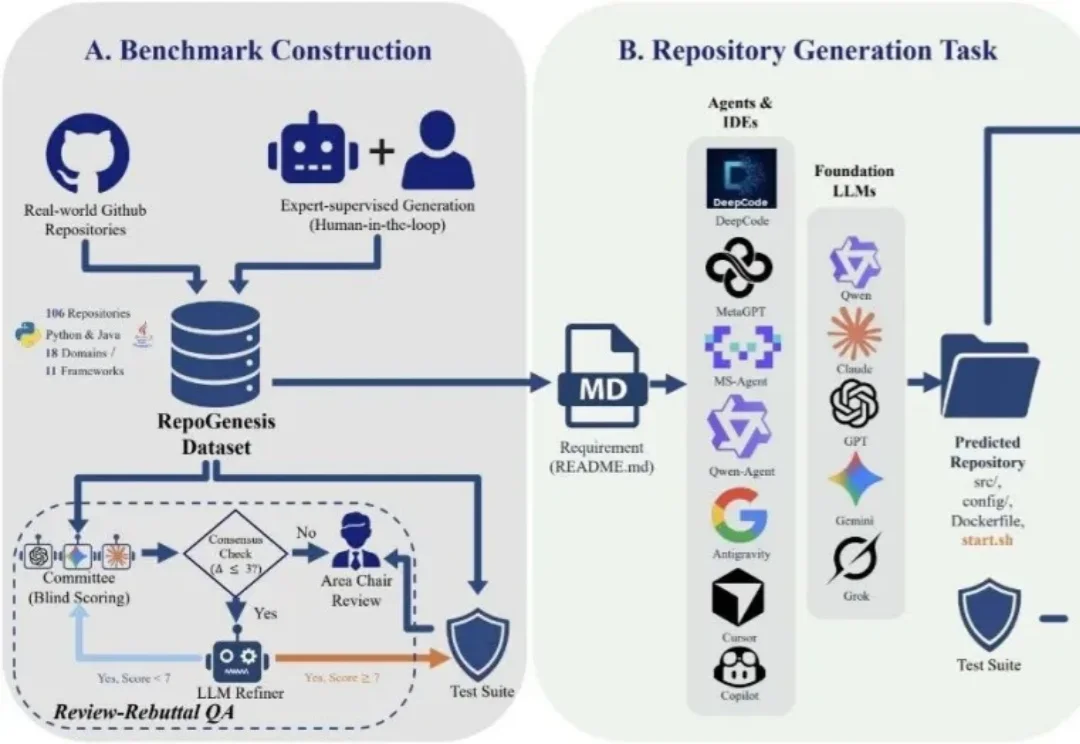
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。