
通往AGI的第二条路
通往AGI的第二条路春节期间,OpenAI又悄悄投出了一颗深水炸弹——Sora。 也就是文生视频的AI模型,相较于此前的Pika、Runway,Sora生成的60秒视频更流畅,也更逼真。
来自主题: AI资讯
11090 点击 2024-02-19 11:02
 搜索
搜索
春节期间,OpenAI又悄悄投出了一颗深水炸弹——Sora。 也就是文生视频的AI模型,相较于此前的Pika、Runway,Sora生成的60秒视频更流畅,也更逼真。

龙年刚一开年,OpenAI又打开了新局面,这次火的是文生视频。2月16日凌晨,OpenAI发布了文生视频大模型Sora。Sora能够根据文本提示创建详细的视频、扩展现有视频中的叙述以及从静态图像生成场景。
过去几天,OpenAI 非常热闹,先有 AI 大牛 Andrej Karpathy 官宣离职,后有视频生成模型 Sora 撼动 AI 圈。
短短几天,「世界模型」雏形相继诞生,AGI真的离我们不远了?Sora之后,LeCun首发AI视频预测架构V-JEPA,能够以人类的理解方式看世界。

为何Sora会掀起滔天巨浪?Sora的技术,就是机器模拟我们世界的下一步。而且今天有人扒出,Sora创新的核心秘密时空Patches,竟是来自谷歌DeepMind和谢赛宁的论文成果。

视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。

尽管收集人类对模型生成内容的相对质量的标签,并通过强化学习从人类反馈(RLHF)来微调无监督大语言模型,使其符合这些偏好的方法极大地推动了对话式人工智能的发展。
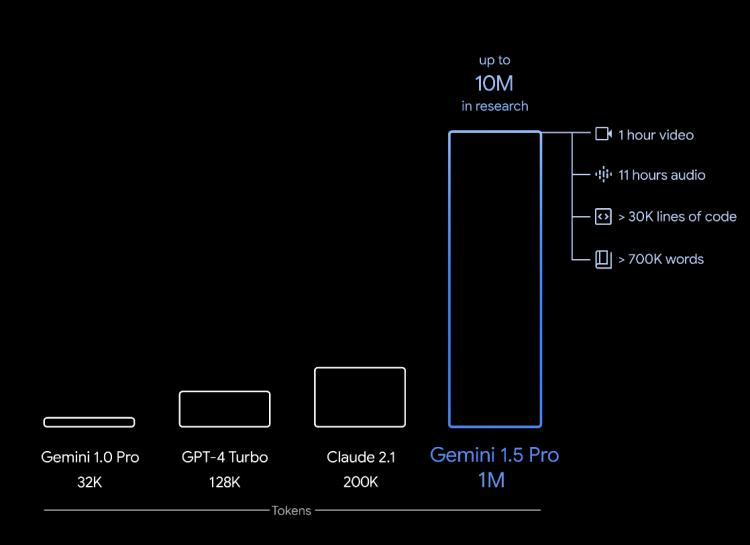
这两天,几乎整个AI圈的目光都被OpenAI发布Sora模型的新闻吸引了去。其实还有件事也值得关注,那就是Google继上周官宣Gemini 1.0 Ultra 后,火速推出下一代人工智能模型Gemini 1.5。

简单粗暴的理解,就是语言能力足够强大之后,它带来的泛化能力直接可以学习图像视频数据和它体现出的模式,然后还可以直接用学习来的图像生成模型最能理解的方式,给这些利用了引擎等已有的强大而成熟的视频生成技术的视觉模型模块下指令,最终生成我们看到的逼真而强大的对物理世界体现出“理解”的视频。

普林斯顿大学和DeepMind的科学家用严谨的数学方法证明了大语言模型不是随机鹦鹉,规模越大能力一定越大。