谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
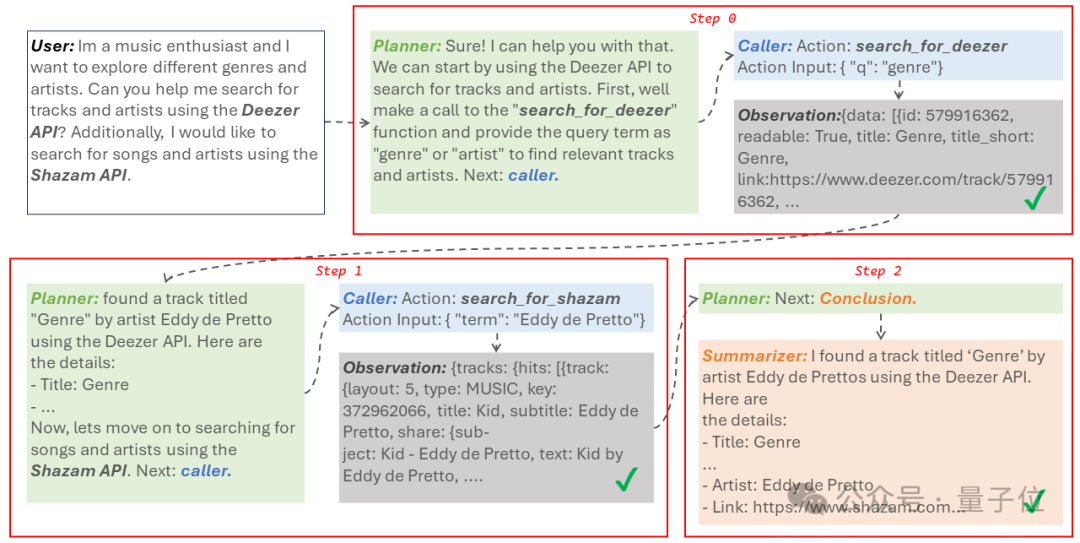
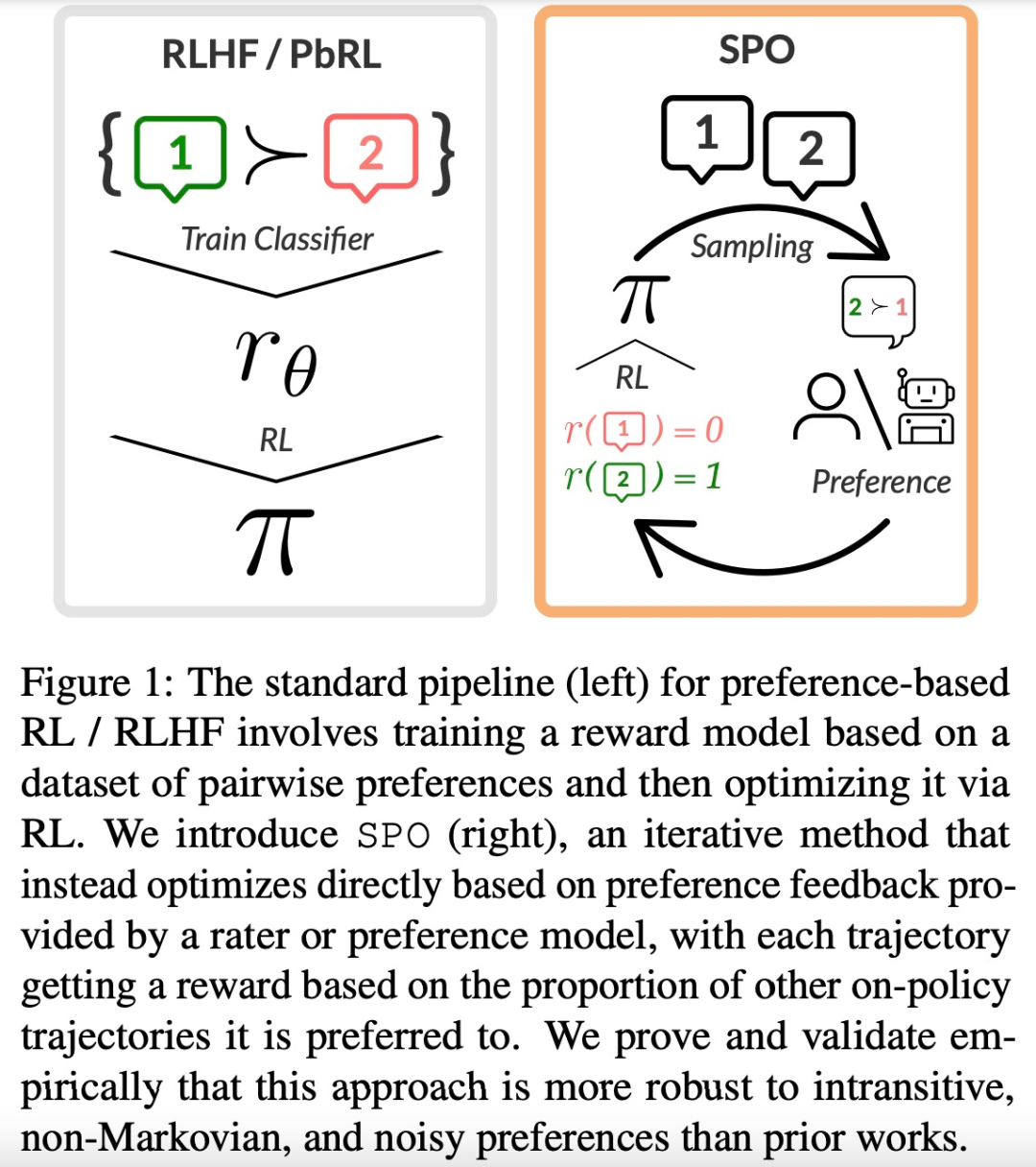
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
来自主题: AI技术研报
5682 点击 2024-02-10 13:02
 搜索
搜索
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
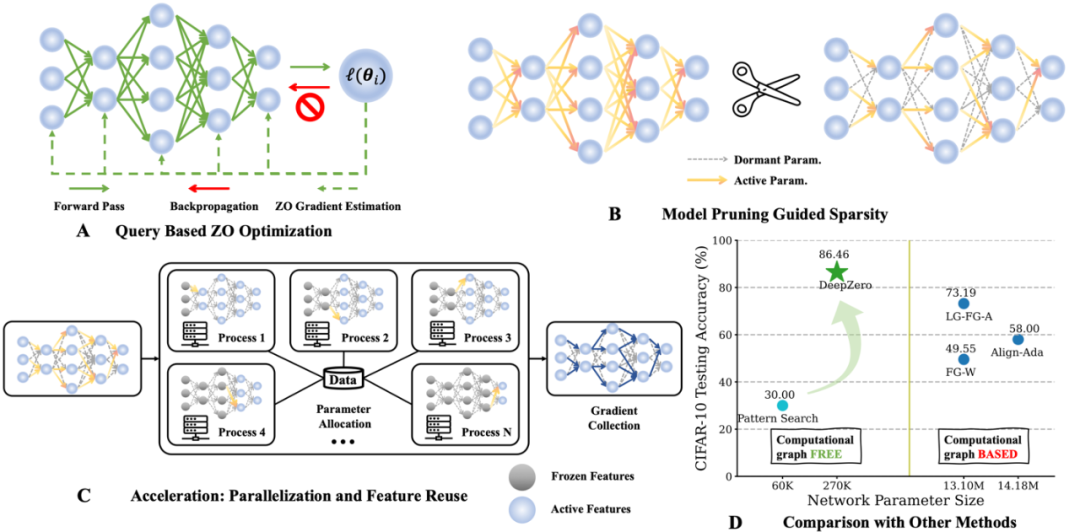
今天介绍一篇密歇根州立大学 (Michigan State University) 和劳伦斯・利弗莫尔国家实验室(Lawrence Livermore National Laboratory)的一篇关于零阶优化深度学习框架的文章 ,本文被 ICLR 2024 接收,代码已开源。

2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。
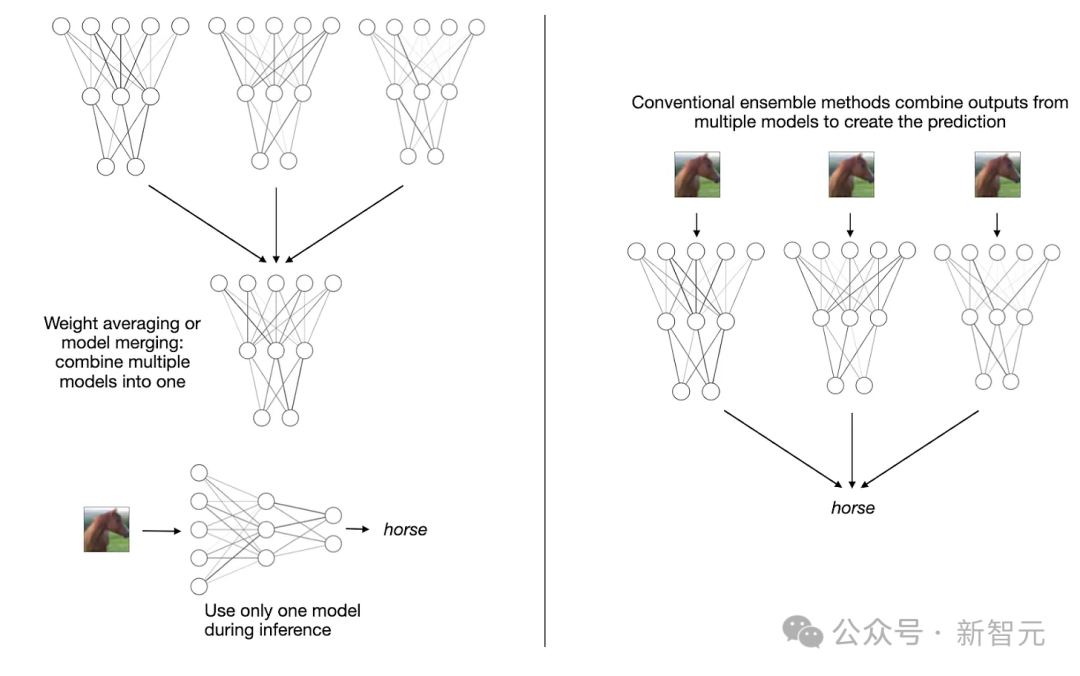
AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。

作为人工智能领域划时代的技术革新,大模型卓越的生成能力和流畅的自然交互方式,正不断突破人机交互的想象边界,引领我们进入到一个全新的智能交互时代。
2024年,是大模型落地的关键一年,国内外的大厂都在动作频频。但要想打造出首个超级AI原生应用,还是要敢啃技术硬骨头,这已成业内共识。
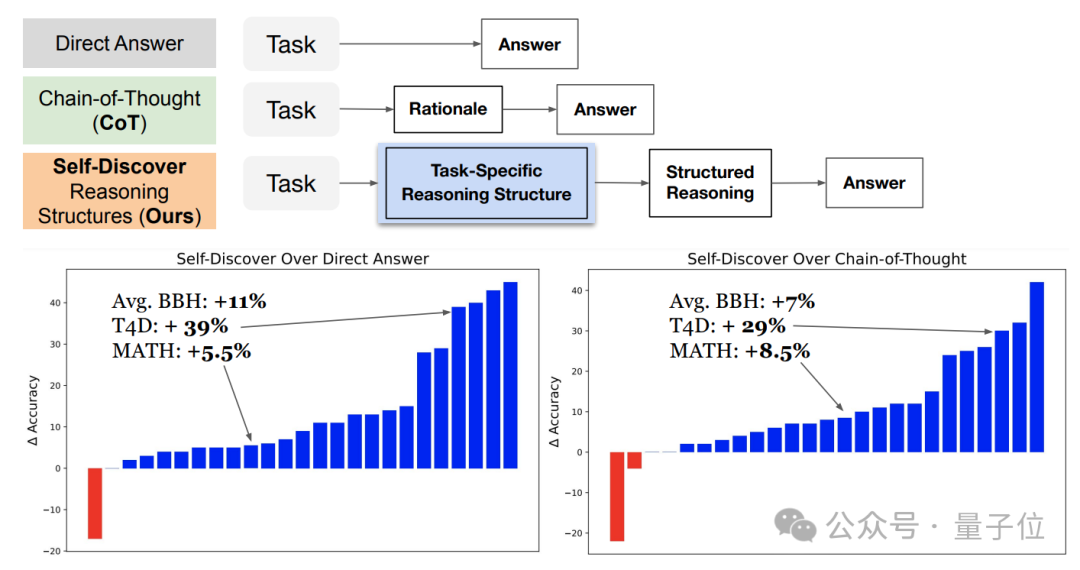
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

国外网站AIPRM收集了100多项ChatGPT统计数据,考察了ChatGPT的增长、使用和公众意见等各项数据。上线一年多以后ChatGPT真的成茶叶蛋了吗?