
轻松盗走 2500 万美元,我们该如何防范人工智能造假危机?
轻松盗走 2500 万美元,我们该如何防范人工智能造假危机?人工智能诈骗已成现实,引人忧虑。近几个月来,人工智能接连浮现,我们频繁在新闻标题中看到如下字眼:AI 泄露了公司代码,还根本就删不掉;AI 软件侵犯了用户的人脸信息隐私;某大模型产品被曝泄露私密对话……等等。
来自主题: AI资讯
5589 点击 2024-02-13 21:20
 搜索
搜索
人工智能诈骗已成现实,引人忧虑。近几个月来,人工智能接连浮现,我们频繁在新闻标题中看到如下字眼:AI 泄露了公司代码,还根本就删不掉;AI 软件侵犯了用户的人脸信息隐私;某大模型产品被曝泄露私密对话……等等。

分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。
该团队的新模型在多个基准测试中都与 Gemini Pro 、GPT-3.5 相媲美。

最近来自香港科技大学(HKUST)、南洋理工大学(NTU)与加利福尼亚大学洛杉矶分校(UCLA)的研究者们提供了新的思路:他们发现大语言模型如 ChatGPT 可以理解传感器信号进而完成物理世界中的任务。该项目初步成果发表于 ACM HotMobile 2024。

最近,UIUC苹果华人提出了一个通用智能体框架CodeAct,通过Python代码统一LLM智能体的行动。
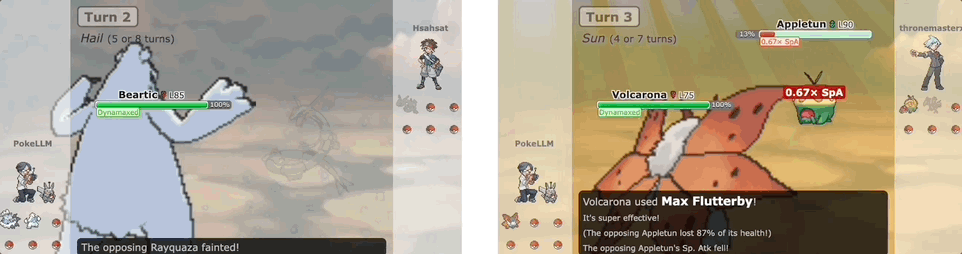
基于大模型的Agent会玩宝可梦了,人类水平的那种!名为PokéLLMon,现在它正在天梯对战中与人类玩家一较高下:
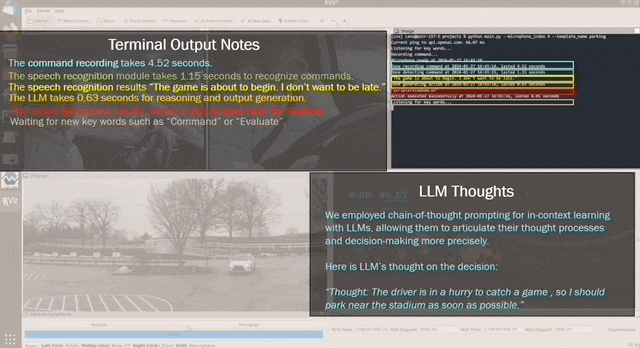
现在一句口令,就能指挥汽车了。比如说声“我开会要迟到了”“我不想让我朋友等太久”等等,车就能理解,并且自动加速起来。

大模型的新考验来了!近日,来自卡内基梅隆大学的研究人员发布了评估LLM多模态Web代理性能的基准测试。

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。
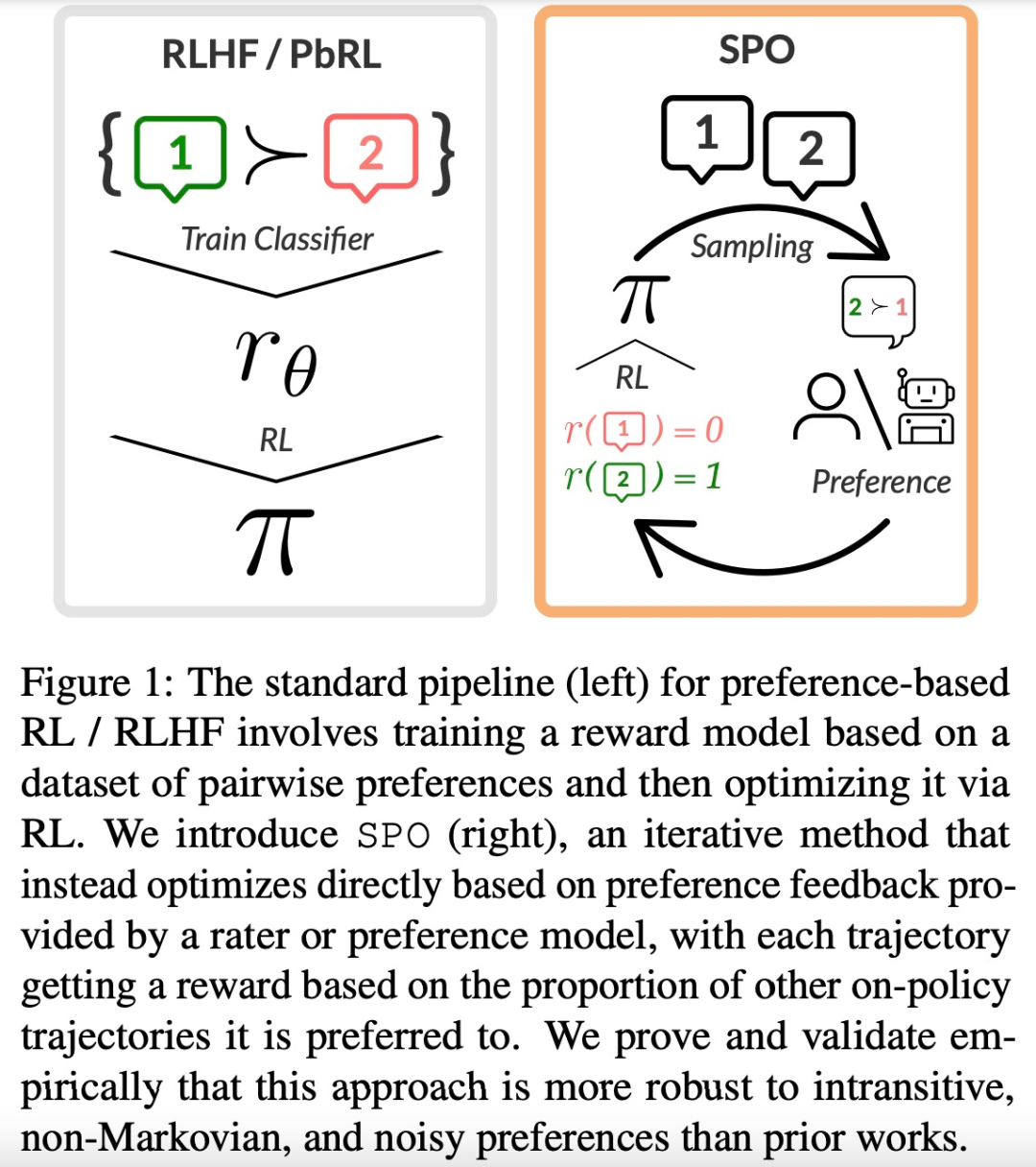
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。