
无需人类或GPT-4打标签!南大&旷视研究院无监督范式大幅降低视觉大模型对齐成本
无需人类或GPT-4打标签!南大&旷视研究院无监督范式大幅降低视觉大模型对齐成本不用打标签,也能解决视觉大模型的偏好对齐问题了。
来自主题: AI技术研报
7580 点击 2024-06-23 20:08
 搜索
搜索
不用打标签,也能解决视觉大模型的偏好对齐问题了。

在人工智能领域的发展过程中,对大语言模型(LLM)的控制与指导始终是核心挑战之一,旨在确保这些模型既强大又安全地服务于人类社会。早期的努力集中于通过人类反馈的强化学习方法(RLHF)来管理这些模型,成效显著,标志着向更加人性化 AI 迈出的关键一步。
本文主要内容为提示词工程师的工作实际经验和感悟。详人所略,略人所详。Prompt领域的优秀教程越来越多,基础知识可以参见社区先辈刘海同学:[23.08] 网上疯传的「AI 提示词工程师」到底是什么?

大模型对齐新方法,让数学推理能力直接提升9%。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

OPO 无需训练即可实现实时动态对齐,而且因其即插即用的特性,适用于所有的开源与闭源大模型。

并非所有人都熟知如何与 LLM 进行高效交流。 一种方案是,人向模型对齐。于是有了 「Prompt工程师」这一岗位,专门撰写适配 LLM 的 Prompt,从而让模型能够更好地生成内容。
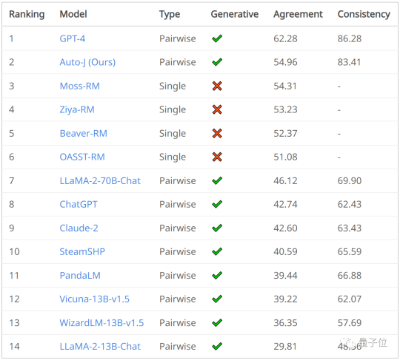
评估大模型对齐表现最高效的方式是?在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。