
首个🦞龙虾大模型排行榜来了!两个国产 AI 杀进全球前三,养虾前必看
首个🦞龙虾大模型排行榜来了!两个国产 AI 杀进全球前三,养虾前必看你现在养了几只龙虾?
来自主题: AI资讯
9303 点击 2026-03-09 10:51
 搜索
搜索
你现在养了几只龙虾?

谁能想到,AI界最权威的大模型排行榜,竟然是个彻头彻尾的骗局?最近,2025年底的一篇名为《LMArena is a cancer on AI》的文章被翻了出来。登上了Hacker News的首页,引起轩然大波!

当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。
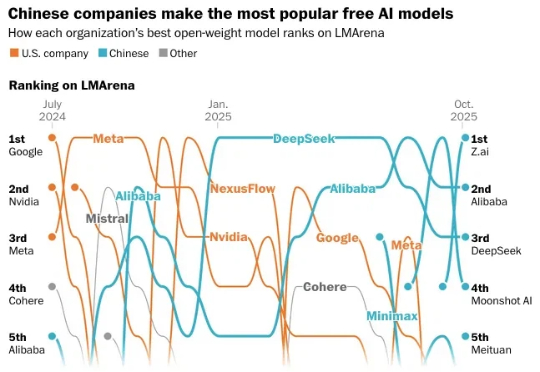
开源大模型,进入中国时间。 10月,公开数据显示,来自中国的开源大模型已经牢牢占据榜单前五。 阿里的Qwen系列和DeepSeek,更是从2024年下半年起,就在开源社区构建起越来越深远的影响力。

AI模型排行榜分两类:以高考式标准化测试衡量特定能力的客观基准测试(如AAII、MMLU-Pro),以及用户匿名盲测、根据偏好对答案投票排名的人类偏好竞技场(如LMArena)。两者各有优劣和局限性,且排行榜本质是门生意。用户应基于实际需求而非榜单名次选择模型,实用性至上。
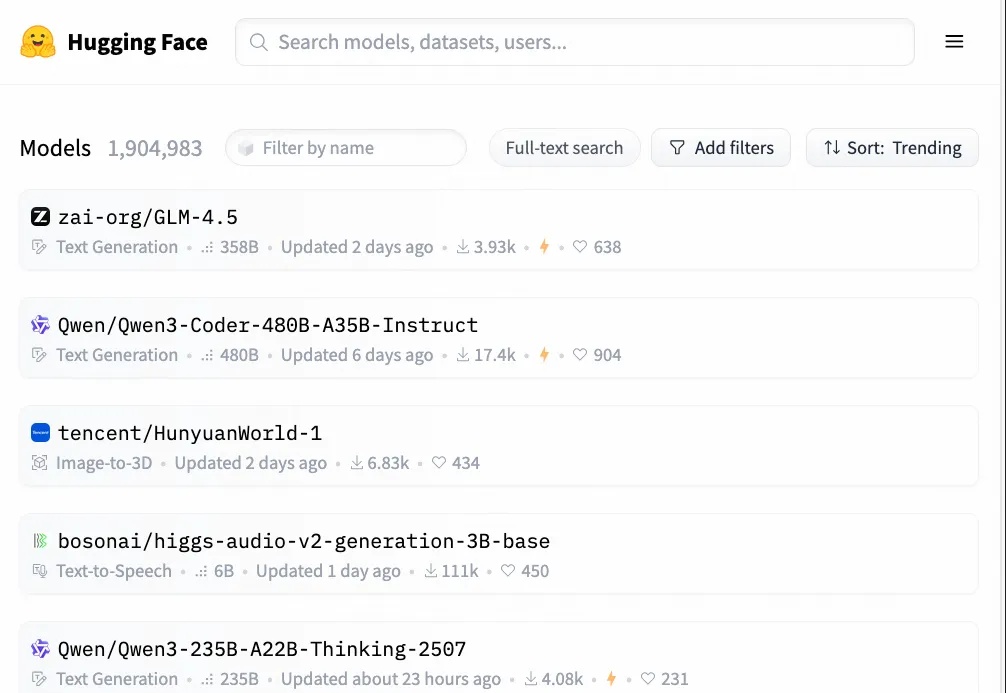
家人们!燃起来了燃起来了! 今天,HuggingFace的开源大模型排行榜前10名中,竟有9个席位被中国模型占据!(深挖了一下,另外一位也是我们华人大神的项目)

GPT-4o原生图像一出手,直接登顶流量王座!今天凌晨,OpenAI再放大招更新GPT-4o,冲进大模型排行榜第二碾压Grok 3、GPT-4.5。创意一键生成,Midjourney瞬间黯然失色,设计师开始颤抖吧。
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。

最近,在全球人工智能模型竞技场(Artificial Analysis)文生图模型排行榜中,一个名叫Red_panda的新模型突然杀出重围,以9%的胜率超越了原榜一大哥Flux1.1Pro成为新王!

一直以来,UC伯克利团队的LMSYS大模型排行榜,深受AI圈欢迎。如今,最有实力的全新大模型排行榜SEAL诞生,得到AI大佬的转发。它最大的特点是在私有数据上,由专家严格评估,并随时间不断更新数据集和模型。