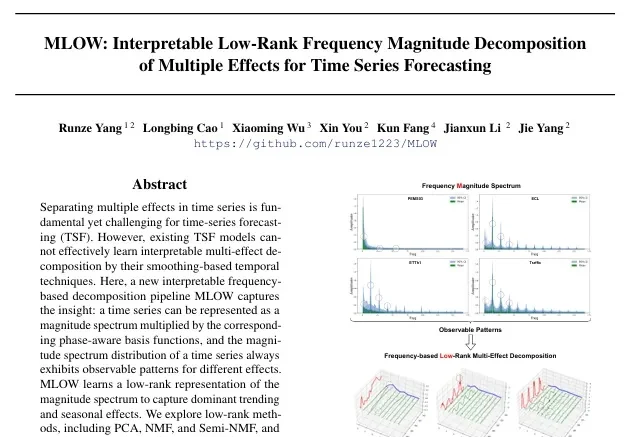
访谈|Codex 团队如何用自己的产品构建产品——整个 Spec 只有 10 个要点
访谈|Codex 团队如何用自己的产品构建产品——整个 Spec 只有 10 个要点OpenAI Codex 团队的产品规格文档只有 10 个要点。不是说每个功能的文档只有 10 个要点,而是整个产品的 spec 就这么多。设计师写的代码量超过了六个月前工程师写的。50 到 100 人的团队,直到最近才有了第二个产品经理。
来自主题: AI技术研报
6036 点击 2026-04-07 10:02