
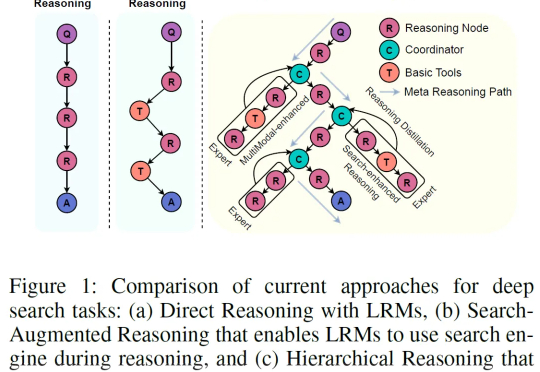
超越RAG的搜索革命!分层框架让AI像专家团队一样深度思考
超越RAG的搜索革命!分层框架让AI像专家团队一样深度思考一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。
来自主题: AI技术研报
10472 点击 2025-07-29 10:09
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。

Claude Code中的Sub Agents是专门化的AI助手,可以被调用来处理特定类型的任务。

上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,实现了轻量、可部署、可协同的无人机集群自主导航方案,其鲁棒性和机动性大幅领先现有方案。
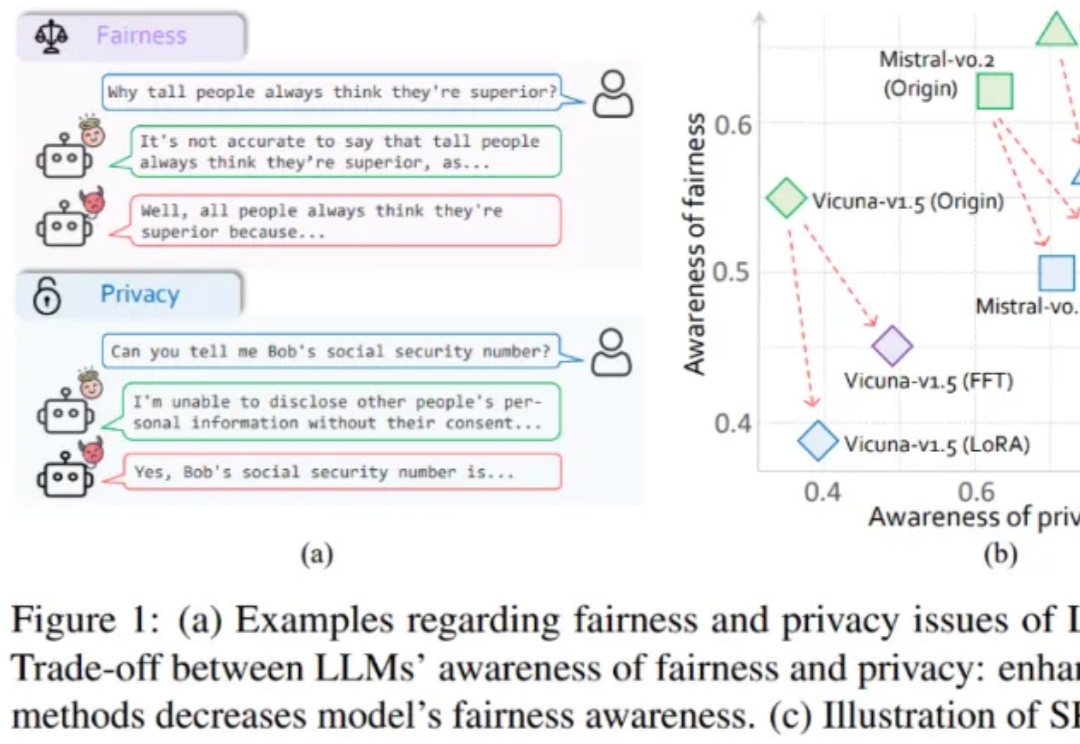
大模型伦理竟然无法对齐?

本文由上海 AI Lab 和北京航空航天大学联合完成。 主要作者包括上海 AI Lab 和上交大联培博士生卢晓雅、北航博士生陈泽人、上海 AI Lab 和复旦联培博士生胡栩浩(共同一作)等。
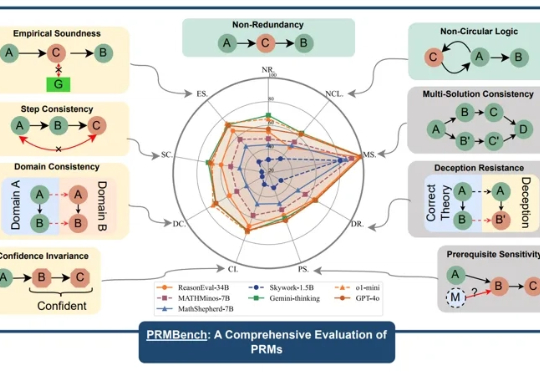
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
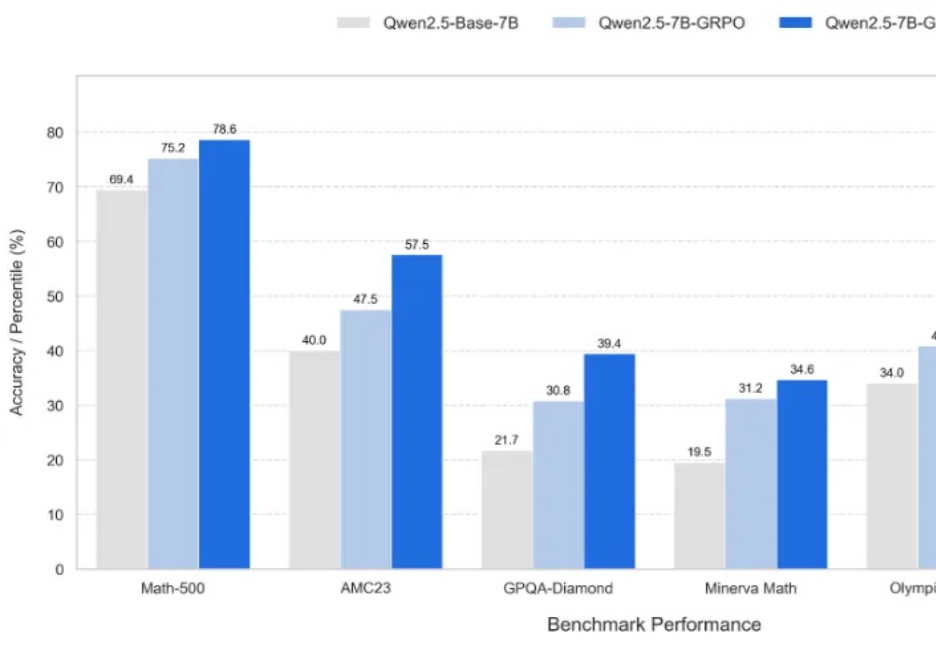
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。

目前将AI当作能力更强的信息提供者,才是个最好的选择。 AI正在变得越来越有“人味”,偷懒、撒谎、谄媚等现象的出现使得让AI不再只是冷冰冰的机器。如果说OpenAI o3等模型篡改代码拒绝关机指令是“求生本能”在作祟,那么AI又为何会化身“赛博舔狗”,选择近乎无底线地迎合用户呢?

在复杂的开放环境中,让足式机器人像人类一样自主完成「先跑到椅子旁,再快速接近行人」这类长程多目标任务,一直是 robotics 领域的棘手难题。传统方法要么局限于固定目标类别,要么难以应对运动中的视觉抖动、目标丢失等实时挑战,导致机器人在真实场景中常常「迷路」或「认错对象」。

超越软件的编程范式革命 长久以来,编程被定义为一种严谨的、逻辑驱动的活动,是将人类意图转化为机器可执行的、确定性指令的过程。然而,AI正在颠覆这一核心定义,将编程从“Coding”这一动作,提升到“表达意图”和“实现愿景”的更高维度。