# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
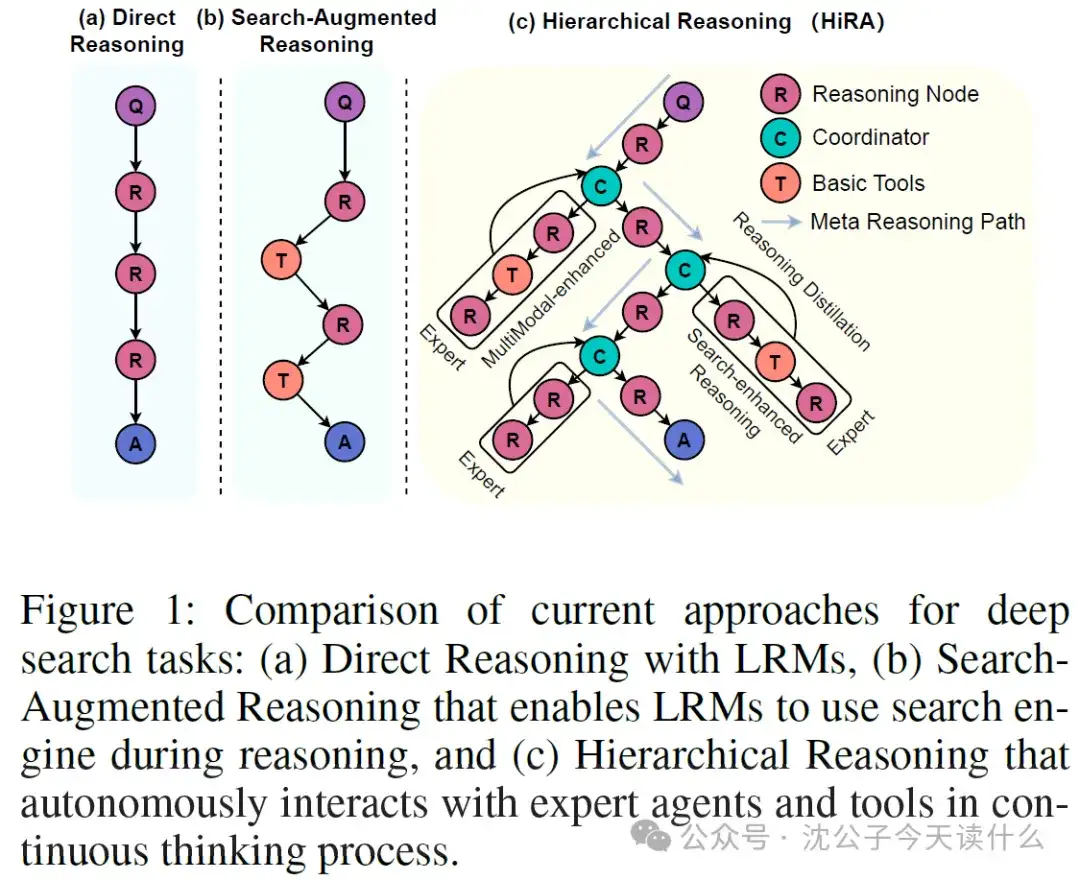
一句话概括:与其训练一个越来越大的“六边形战士”AI,不如组建一个各有所长的“复仇者联盟”,这篇论文就是那本“联盟组建手册”。(原论文题目见文末,点击阅读原文可直接跳转至原文链接,Published on arxiv on 03 Jul 2025, by Renmin University of China)
亲爱的读者们,沈公子的公众号agent🤖和base model近期取得了重大突破,今后公众号文章行文会更流畅,处理公式和符号也完全达到人类专家水准,会大幅减少出现错乱和显示异常的情况,提升阅读体验。enjoying :)
第一阶段:核心思想概览
论文的动机
在面对“未来的家庭娱乐会是什么样?”或“结合最新的财报和市场趋势,分析一下苹果公司的下一个增长点可能在哪里?”这类复杂问题时,我们需要的不仅仅是简单的搜索结果。我们需要一个能像研究员一样,深入思考、跨领域整合信息、并最终给出一个全面、有洞察力的答案的系统。
传统的搜索引擎,如谷歌或百度,只是信息检索的第一步,它们给我们一堆网页链接,后续的筛选、阅读、整合、提炼观点等繁重工作,都需要用户自己完成。近年来兴起的“检索增强生成”(RAG)技术,虽然能自动检索并生成答案,但大多遵循一个固定的、预设好的流程,就像一个只会按部就班办事的初级助理,缺乏灵活性和深度。
而更先进的一些AI智能体(Agent)方法,虽然尝试让一个大模型同时具备规划、搜索、执行代码等多种能力,但这又带来了新的问题:单一模型既当“战略规划师”又当“一线执行者”。这就像让一个公司的CEO不仅要制定公司未来五年的发展战略,还要亲自去跑市场、写代码、做设计。结果可想而知:CEO的宝贵精力被琐碎的执行细节淹没,无法进行清晰、连贯的顶层战略思考,导致整个决策过程效率低下、容易出错,而且想给公司增加一个新业务(比如视频制作),就需要对CEO进行复杂的再培训,扩展性极差。
这篇论文的动机,正是要解决这种“规划与执行耦合过紧”导致的效率和扩展性瓶颈。
论文的主要贡献
为了实现这些创新,作者设计了一个由三个核心角色组成的团队:
论文的显著成果在于,它不仅仅在数值上取得了领先(如在GAIA等复杂基准测试上大幅超越SOTA),更重要的是,它为构建更强大、更可扩展的AI智能体系统提供了一个行之有效的架构范式。这种“分而治之、专人专事”的思想,解决了单一模型“精神分裂”的困境,使得AI能够以一种更有条理、更高效的方式解决真正复杂的问题。
理解论文的关键与难点
因此,我们的解释将从自适应推理协调员(Adaptive Reasoning Coordinator) 这个枢纽角色切入。
第二阶段:核心概念的深入解析
用比喻理解核心机制:组建一家明星咨询公司
想象一下,我们成立了一家顶级的咨询公司,专门解决客户提出的各种刁钻、复杂的问题(例如,“如何为一款新型咖啡机开拓亚洲市场?”)。
这个咨询公司的运作模式,就是HiRA框架的精髓:CEO(规划器)专注于战略,PM(协调员)负责调度和信息提炼,专家团队(执行器)负责具体执行。
比喻与技术的对应关系



第三阶段:HiRA工作流程详解
让我们跟随一个具体的例子,详细拆解HiRA框架从接收问题到给出答案的全过程。假设用户提出的问题是论文案例中的:“根据维基百科,在东盟(ASEAN)国家集团中,哪两个国家的首都之间地理距离最远?请按字母顺序列出这两个国家。”
第一步:接收任务,规划器启动
第二步:协调员的智能调度
第三步:执行器的专业操作
第四步:协调员的提炼与反馈
第五步:规划、执行、反馈的循环(关键所在)
第六步:生成最终答案
通过这个流程,我们可以看到,HiRA是一个动态的、可反思的、具备纠错能力的闭环系统。协调员的“信息蒸馏”功能至关重要,它屏蔽了执行层的噪音,让规划器能始终保持在战略层面进行清晰的思考和调整。
第四阶段:实验设计与验证分析
主实验:核心论点的验证
消融实验:内部组件的贡献
通过在Table 2中逐个移除HiRA的关键模块,实验证明了:
这些结果清晰地表明,HiRA的每一个核心组件都对最终的卓越性能做出了关键且不可替代的贡献。
深度实验:方法的内在特性
文章来自公众号“沈公子今天读什么”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
