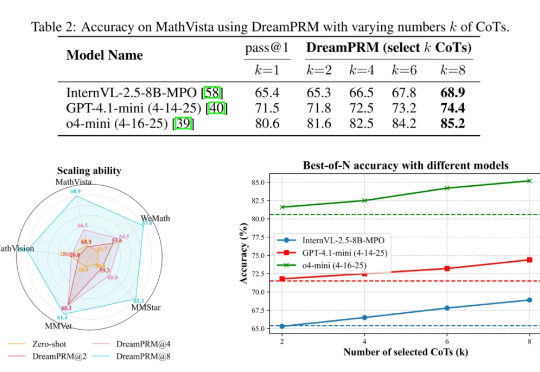
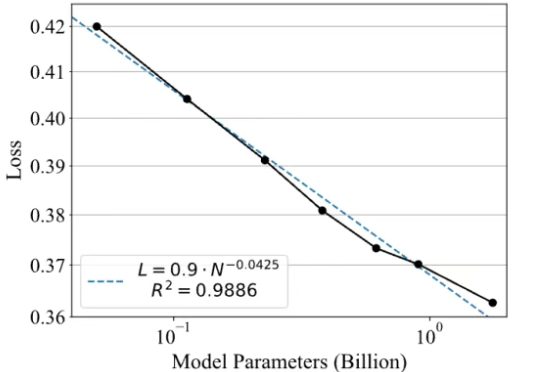
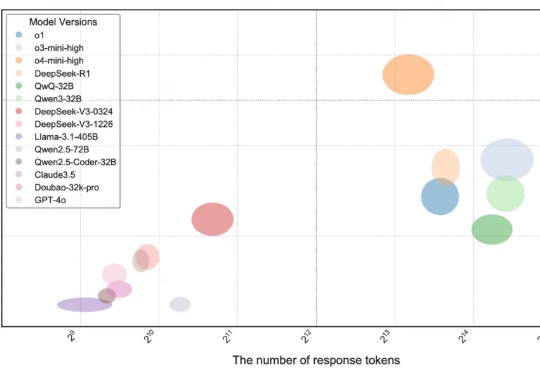
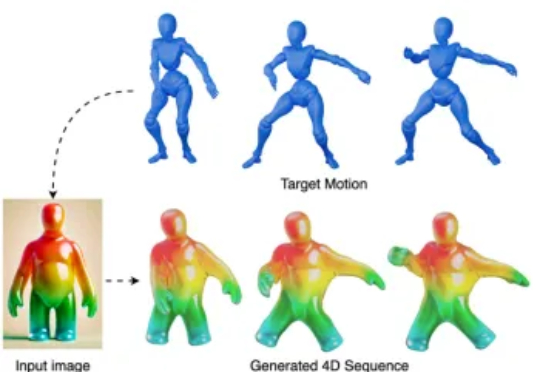
模拟大脑功能分化!北大与港中文发布Fast-in-Slow VLA,让“快行动”和“慢推理”统一协作
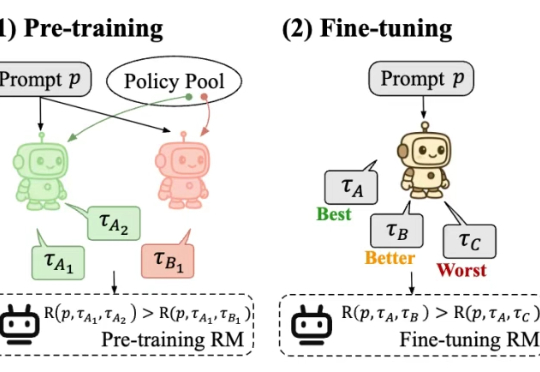
模拟大脑功能分化!北大与港中文发布Fast-in-Slow VLA,让“快行动”和“慢推理”统一协作在机器人操控领域,实现高频响应与复杂推理的统一,一直是一个重大技术挑战。近期,北京大学与香港中文大学的研究团队联合发布了名为 Fast-in-Slow(FiS-VLA) 的全新双系统视觉 - 语言 - 动作模型。
来自主题: AI技术研报
7812 点击 2025-07-12 12:08