北大彭宇新教授团队开源细粒度多模态大模型Finedefics
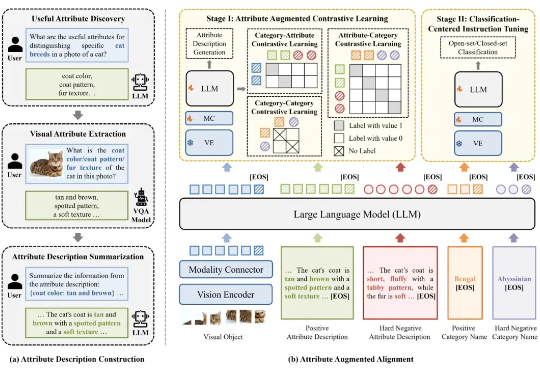
北大彭宇新教授团队开源细粒度多模态大模型Finedefics尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」
来自主题: AI资讯
10351 点击 2025-02-17 17:37