# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
宋亦仁,NUS Show Lab 博士生,研究方向是生成式 AI,及生成式 AI 的安全性。曾在网易游戏互娱 AI lab 实习,研发服务游戏美术场景的图像生成模型;前小红书
智能创作组算法工程师,在 AIGC 与创意设计结合领域有丰富经验。
刘成,NUS 重庆研究院四年级本科生, 研究方向是生成式 AI,负责 MakeAnything 数据集构建和模型调优。
人类智慧的一大特征是能够分步骤创造复杂作品,例如绘画、手工艺和烹饪等,这些过程体现了逻辑与美学的融合。然而,让 AI 学会生成这样的 “步骤教程” 面临三
大挑战:多任务数据稀缺、步骤间逻辑连贯性不足,以及跨领域泛化能力有限。来自新加坡国立大学的最新研究 MakeAnything,通过 Diffusion Transformer
(DiT)与非对称 LoRA 技术的结合,首次实现了高质量、跨领域的程序化序列生成,在 21 类任务中取得优异表现,同时展现出在新任务上出色的泛化能力。本文
将深入解析这一技术的方案设计与实验结果。
扩散模型擅长单张图像合成,通过设计提示词和 In-Context LoRA 训练,先进的 DiT 模型可以生成多个子图的拼图,具有一致性的外观。但生成多步骤序列时,往往
面临以下问题:
1. 逻辑断层:步骤间缺乏因果关联,如绘画中 “先画轮廓后上色” 的常识易被忽略;
2. 外观漂移:前后帧的生成结果可能外观不一致;
3. 数据瓶颈:现有的步骤数据集规模小、领域单一,难以支持复杂任务训练。
MakeAnything 的解决思路直击核心:

之前的过程生成方法(如 ProcessPainter, PaintsUndo)使用 U-Net 架构和 Animatediff 时序模块,对于前后帧外观变化大、具有复杂逻辑性的过程生成表现不
佳。而 MakeAnything 采用扩散 Transformer(DiT)作为基础模型,通过拼图将所有帧排版在一张图上,利用空间注意力机制捕捉步骤间依赖关系。具体来说,
MakeAnything 提出蛇形序列布局,将多步骤帧排列为蛇形排列的网格,确保时间相邻的步骤在空间上也相邻(见下图),强化模型对步骤顺序的感知。
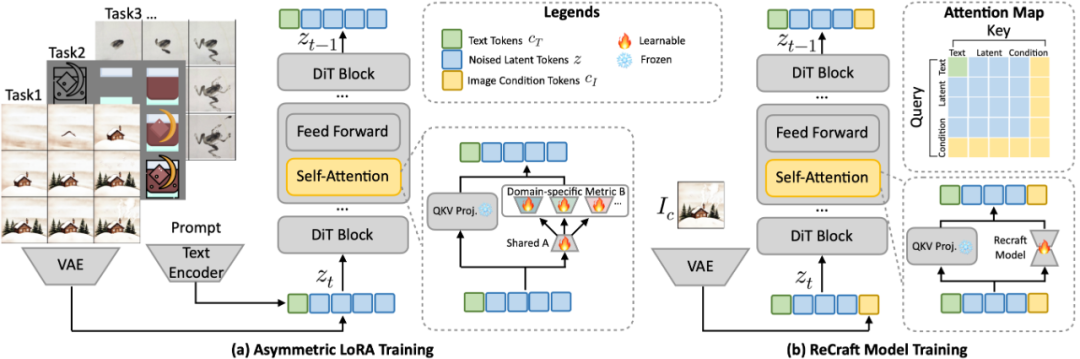
在不同任务序列上混训 LoRA 模型会导致任务冲突,而分任务单独训练则面临过拟合问题 。一些任务 (如特定画师的肖像作品)只有 50 个数据序列,且类别单一,
微调模型后仅能生成肖像。受大语言模型领域 HydraLoRA 启发,我们将非对称 LoRA 引入图像生成,为了兼顾通用知识学习和特定任务效果。在 LoRA 中,A 矩阵
和 B 矩阵是关键组成部分,用于替换传统线性变换中的权重矩阵。A 矩阵通常是一个小尺寸的矩阵,用于将高维空间下采样到低维空间。B 矩阵负责将低维空间重新
投影回原始高维空间。
非对称 LoRA 训练时,在所有训练数据集上,微调共享矩阵 A,从大规模预训练中提取通用知识和分步骤逻辑;对不同任务微调单独矩阵 B 以适配具体任务特性,
如油画笔触、乐高拼接规则。推理时按权重融合不同的 B 矩阵,在保持泛化能力的同时,精准适配不同领域需求。
下图展示了水墨画、素描、油画、风景插画过程的生成结果,前后视觉一致性好,过程十分合理。

下图展示了生成粘土玩具、陶艺、毛线玩具、石雕的结果,生成手工艺品的创建过程也不在话下。

下图展示了更详细的 9 帧步骤,分别是沙画和变形金刚的变形过程。

3. ReCraft 模型:从「成品图」反推创作过程
除了生成过程教程,本文还开发了 “ReCraft 模型”,为过程生成引入图像条件。ReCraft 模型利用了变分自编码器(VAE)来编码目标图像中的特征,这些 tokens 随
后与去噪 token 连接,用于指导 DIT 的去噪过程,以确保生成的中间帧在视觉上与目标图像保持一致。我们将 Text2Sequence LoRA 与基础模型融合,作为 ReCraft
模型训练的基础模型。通过复用预训练的 Flux 模型结构,对于单一任务,仅需在 50 + 序列上微调 LoRA 即可实现图像条件生成。
ReCraft 模型特别适合需要从已有作品中逆向工程或者从简单图像中创造详细教程的应用场景。如下图所示,预测绘画、雕刻等手工艺步骤,乐高模型拼搭过程。

MakeAnything 还能在没见过的任务上有一定泛化性能。下图展示了将 MakeAnything 的过程 LoRA 和 Civitai, LibLib 社区的风格化 LoRA 结合使用的结果。尽管
MakeAnything 训练是没见过冰雕、浮雕、衍纸画和水彩画,仍能取得相当不错的泛化结果。我们认为不同任务之间是相通的,比如各类雕刻和不同绘画题材。

三、实验结果 & 评估
1. 评估指标
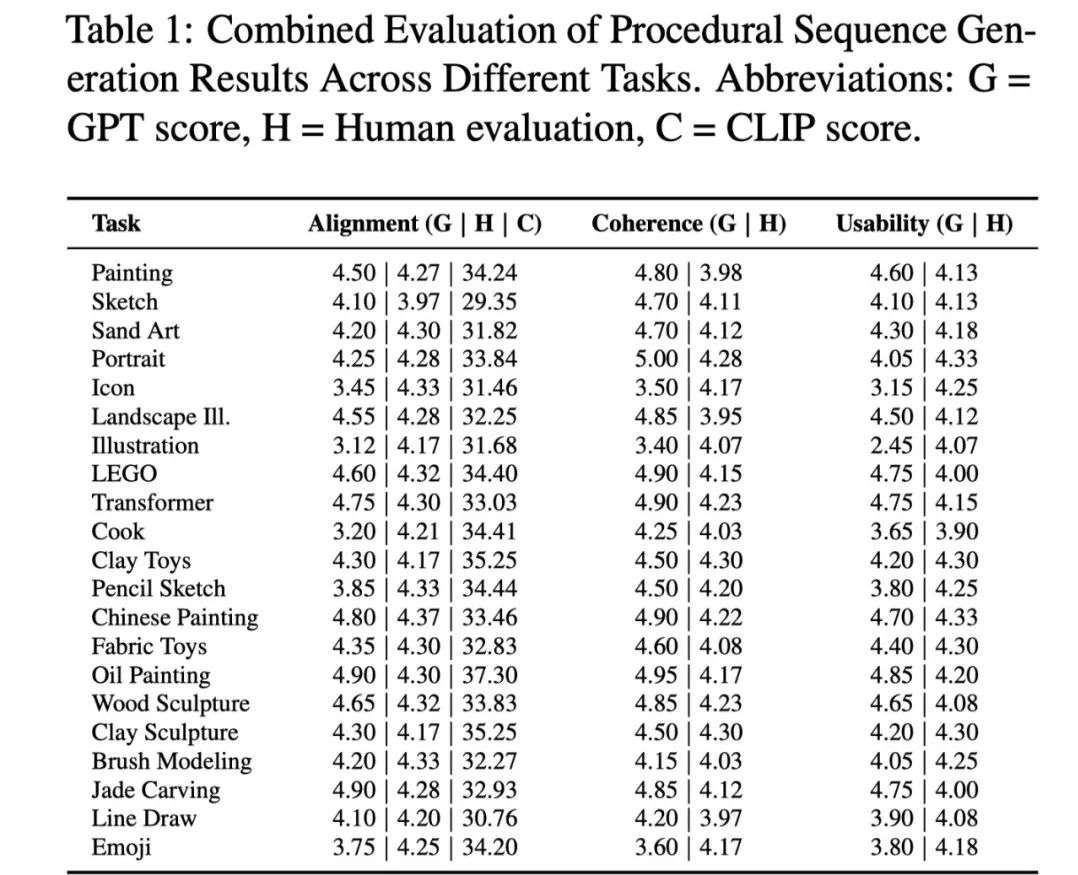
一个好的教程需要是连贯的、合逻辑的并且有用的。MakeAnything 采用 CLIP Score 来评估生成结果的文本 - 图像对齐,用 GPT4-o 和人类评估来评价生成结果的
连贯性和有用性。通过精心设计了 GPT4-o 的输入提示和评分规则,以符合人类的偏好。在对比实验中,我们将不同基准的结果与我们的结果进行拼接,一次性输入
GPT4-o,并让其选择在不同评价维度上最好的结果。
在 Text2Sequence 任务中, MakeAnything 和最先进的 baseline 方法对比,分别是 ProcessPainter,Flux 1.0, 商业 API Ideogram。在 Image2Sequence 任务中,
MakeAnything 对比了 Inverse Painting 和 PaintsUndo 两种绘画过程生成方法。
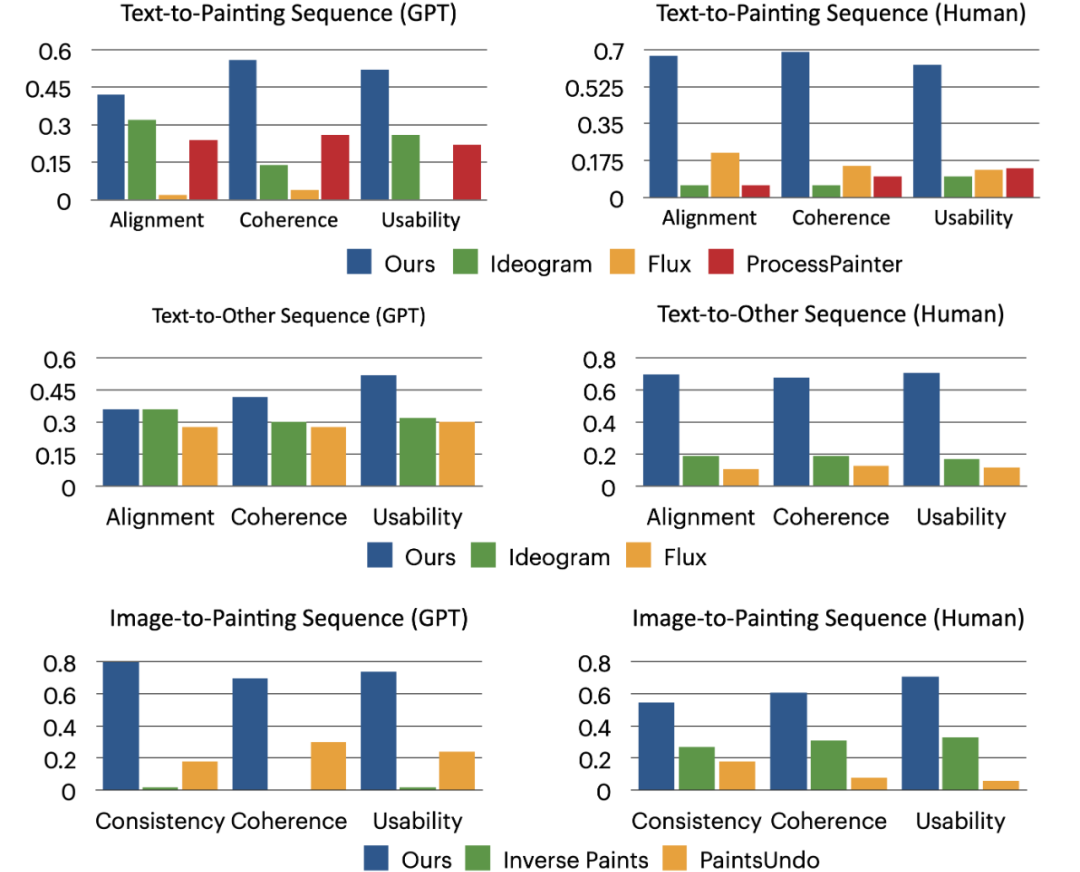
实验结果显示,MakeAnything 的结果在图文一致性, 逻辑连贯性、有用性上取得领先。
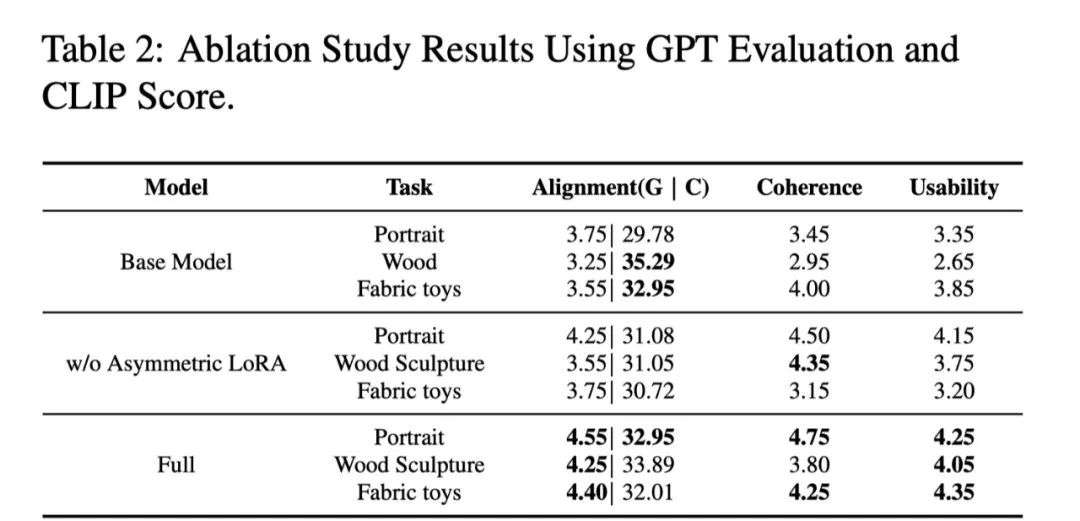
3. 消融实验
我们对不对称 LoRA 进行了消融实验,下图对比了肖像生成和草图生成的结果。前者在 50 张肖像绘画序列上训练, 后者在 300 张卡通角色草图序列上训练。我们
对比了基础模型的结果、标准 LoRA 的结果,以及采用对不对称 LoRA 的结果。从结果可以看出,尽管基础无法生成合理的分步骤结果,但是图文一致性整体不错。
采用标准 LoRA 在类别分布不均匀的小数据上训练导致了严重的过拟合,虽然分步骤的过程合理,图文一致性显著变差。而采用不对称 LoRA 结果很好的兼顾过程合
理性和图文一致性。我们认为在海量过程数据上训练的 A 矩阵学习到了更多通用的知识,有利于缓解过拟合。
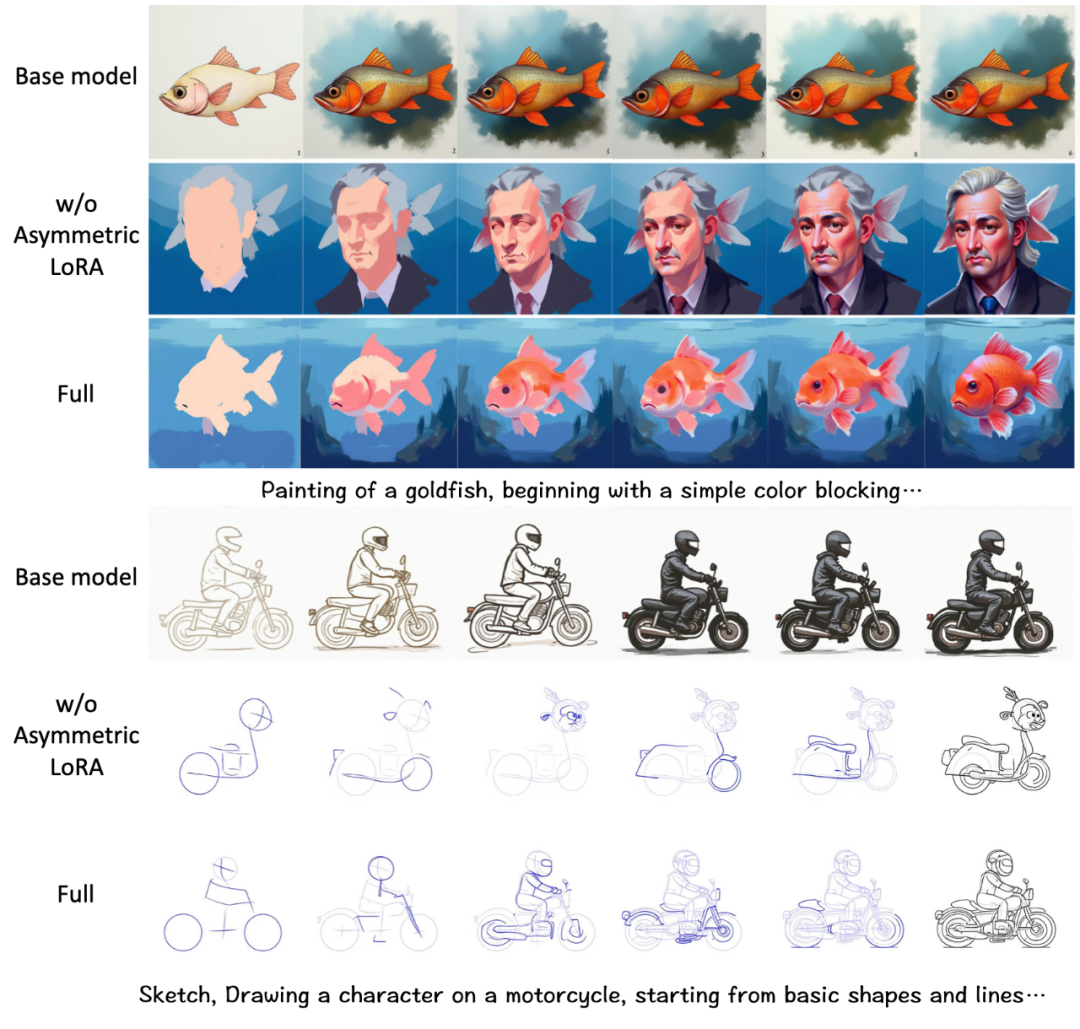
表 2 展示了在更多任务上的定量实验结果,进一步证实结论。
结语
MakeAnything 标志着 AI 从 “生成结果” 迈向 “生成过程” 的关键一步。更多细节见原文:https://arxiv.org/abs/2502.01572
其代码、模型与数据集已开源 GitHub: https://github.com/showlab/MakeAnything,期待更多开发者共同探索过程生成的无限可能。
文章来自于微信公众号 “机器之心”,作者 :宋亦仁、刘成



【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
