
阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节
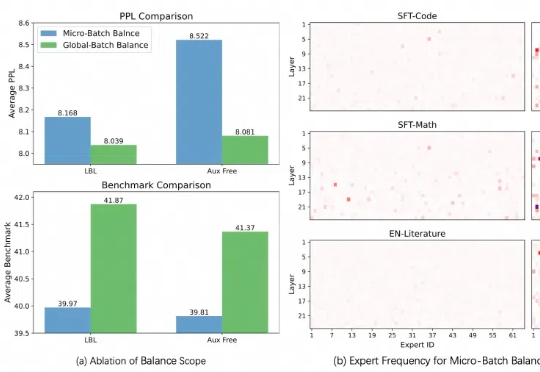
阿里云通义大模型新技术:MoE模型训练专家平衡的关键细节本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。
来自主题: AI技术研报
5038 点击 2025-01-26 11:12
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。

OpenAI 在 “双十二” 发布会的最后一天公开了 o 系列背后的对齐方法 - deliberative alignment,展示了通过系统 2 的慢思考能力提升模型安全性的可行性。

新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。

由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。
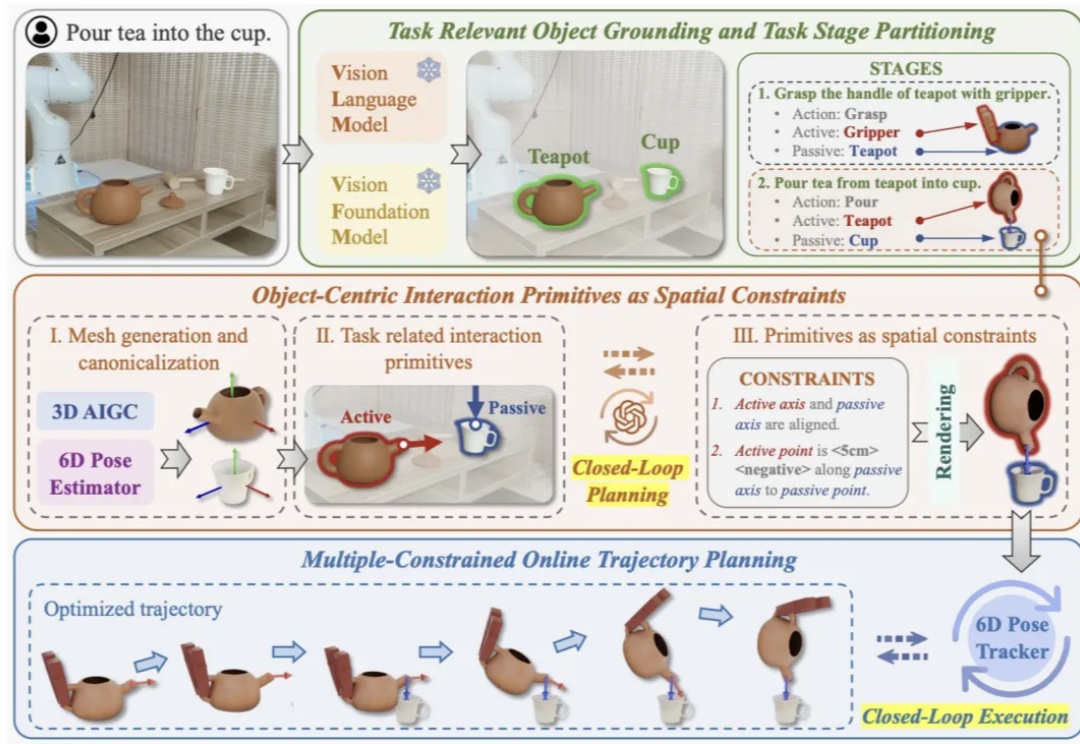
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是具身智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:
仅使用20K合成数据,就能让Qwen模型能力飙升——