
可灵视频生成可控性为什么这么好?快手又公开了四篇研究
可灵视频生成可控性为什么这么好?快手又公开了四篇研究可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。
来自主题: AI技术研报
9541 点击 2025-01-23 11:32
可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。

模型蒸馏也有「度」,过度蒸馏,只会导致模型性能下降。最近,来自中科院、北大等多家机构提出全新框架,从两个关键要素去评估和量化蒸馏模型的影响。结果发现,除了豆包、Claude、Gemini之外,大部分开/闭源LLM蒸馏程度过高。
该技术报告的主要作者 Lu Wang, Fangkai Yang, Chaoyun Zhang, Shilin He, Pu Zhao, Si Qin 等均来自 Data, Knowledge, and Intelligence (DKI) 团队,为微软 TaskWeaver, WizardLLM, Windows GUI Agent UFO 的核心开发者。

我亲眼见证了数据量的爆炸式增长以及行业的巨额投入。当时就很明显,AI是推动这些数据增长背后的关键动力。那是一个非常有趣的时刻——Meta正在完成“移动优先”的过渡,开始迈向“AI 优先”。
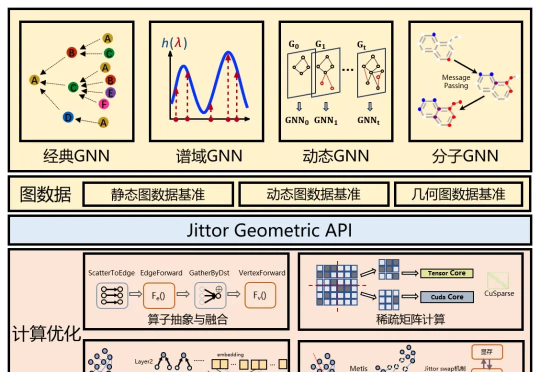
ittor Geometric 1.0是由中国人民大学与东北大学联合开发的图机器学习库,基于国产Jittor框架,高效灵活,可助力处理复杂图结构数据,性能优于同类型框架,支持多种前沿图神经网络模型,已开源供用户使用。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
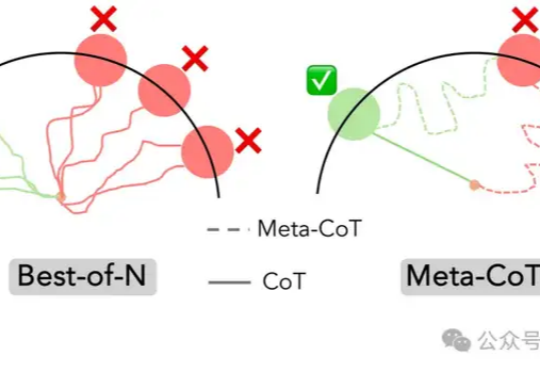
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!

意图识别及其在智能设计中的应用
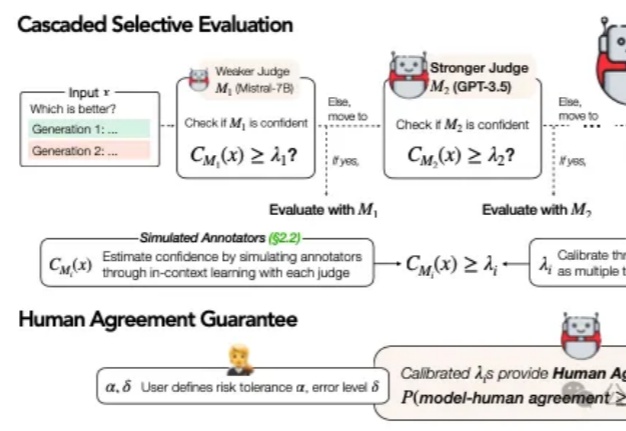
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
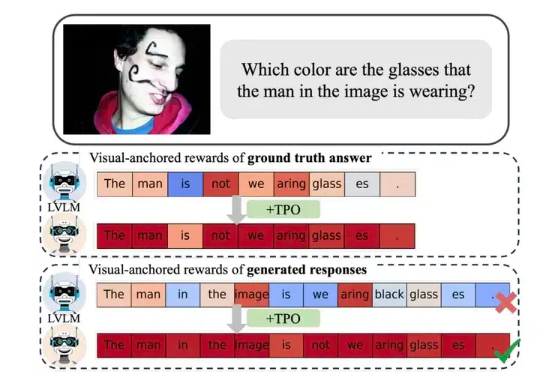
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。